boîte à outil 1
Parcours du répertoire arborescent, extraction du texte
Savoir plusLa réalisation de ce projet a deux objectifs essentiels : 1) apprendre le langage de programmation Perl, qui est très performant en traitement de textes ; 2) atteindre certains objectifs linguistiques : annotation du corpus, recherche d’information, étude lexicologique/syntaxique à partir de ces résultats…
Cette chaîne de traitement est mise en œuvre en trois étapes principales :
Premièrement, à partir d’un corpus arborescent, constitué par l’ensemble des fils RSS disponibles sur le site du journal Le Monde de l’an 2019, on récupère tous les titres et leurs résumés d’une même rubrique, et les met dans un fichier texte, ainsi qu’un fichier XML ;
Deuxièmement, On développe le script de l’étape 1, afin de pouvoir annoter le texte récupéré en même temps. Les outils d’annotation utilisés sont TreeTagger et Talismane. Le résultat annoté par TreeTagger est stocké dans un fichier xml, tandis que celui de Talismane est sauvegardé dans un autre fichier txt;
Troisièmement, en utilisant le corpus annoté, on essaie d’écrire un autre script pour extraire certains patrons, par exemple, un nom suivi d’un adjecif.
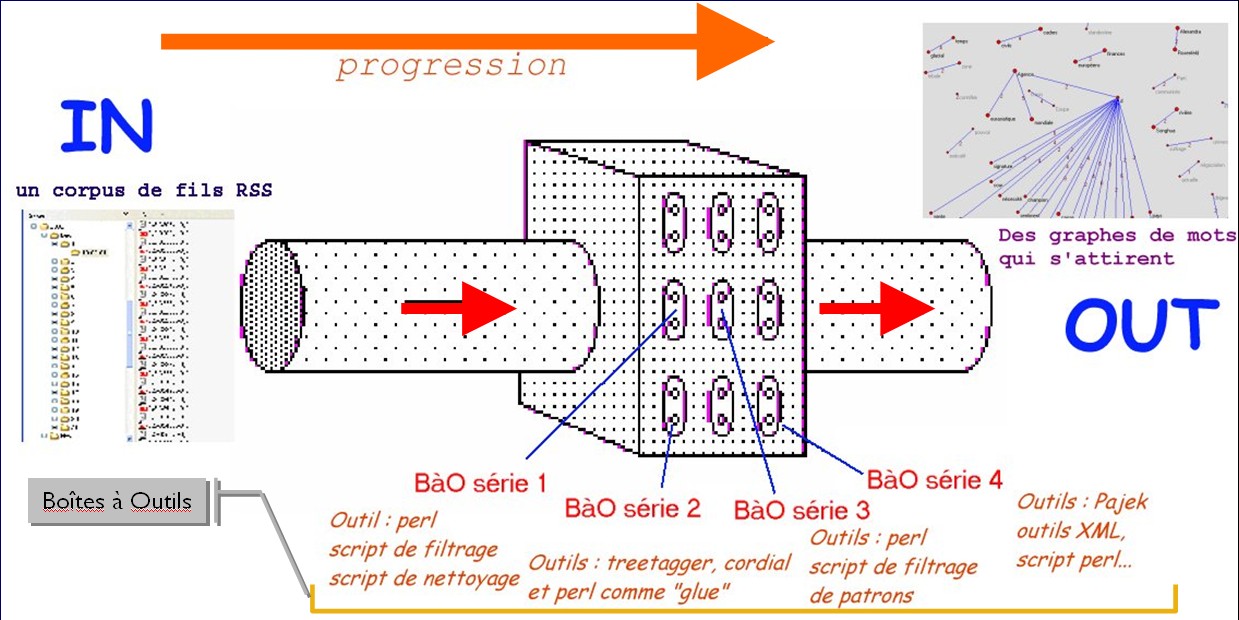


En progressant sur ce projet, je comprends mieux la programmation et le langage de programmation Perl. En plus, ce projet nous montre en détail comment on peut organiser, traiter et chercher des infos utiles dans les textes bruts du monde réel. C’est la base pour des traitements plus compliqués. À partir des fichiers obtenus, on peut analyser des traits linguistiques, par exemple, les collocations les plus utilisées, ou la fréquence de certains termes dans un domaine spécifique.