boîte à outils 2
Annotation du texte
Savoir plusRécupération des patrons morphosyntaxiques
Cette 3e étape a un script indépendant. Il utilise les fichiers annotés avec Talismane obtenus dans l’étape précédente, et renvoie un fichier txt avec les patrons morphosyntaxiques trouvés dans le corpus. J’ai numéroté les résultats trouvés dans le fichier txt.
L’idée principale de ce script n’est pas compliquée : on crée d’abord 2 listes par leur ordre dans le corpus annoté, une pour les tokens et l’autre pour leurs étiquettes POS; ensuite, il faut comparer l’etiquette POS et ses suivants avec la suite proposée par patron; si on trouve une suite, on stockera ses tokens correspondants dans la liste de sortie.
Avec ce script, j’ai testé ces 4 patrons morphosyntaxiques suivants dans la rubrique « à la une » (3208) :
ADJ+NOM
NOM+ADJ
NOM+PREP+NOM+PREP
VERBE+DET+NOM
Finalement, voici le script et les résultats obtenus :
#!/usr/bin/perl -w
#------------------------------------------------
#usage:
# perl BaO3.pl nom_fichier_talismane patron
#example:
# perl BaO3.pl sortieTalismane_3208.txt V DET NC
#fichier obtenu:
# sortie_patron_chainePatron.txt
#------------------------------------------------
use utf8;
#----------------------------------
#obternir les arguments du terminal
#----------------------------------
my $fichier = shift(@ARGV); #nom du fichier Talismane
my @patron = @ARGV; #suite du patron
my $chaine_patron = join("",@patron); #créer la chaine de patron pour la comparaison plus tard
#------------------------------------------------------------------------------------
#lecture du fichier Talismane,obtenir la liste des tokens et la liste de leur POS tag
#------------------------------------------------------------------------------------
open(TALISMANE, "<:encoding(utf8)", $fichier);
my @liste_formes = (); #liste de token
my @liste_pos = (); #leur tag
while (my $ligne=<TALISMANE>){
if ($ligne =~ /^[0-9]+\t[^\t]+\t[^\t]+\t[^\t]+\t/){
chomp ($ligne);
my @token_info = split(/\t/,$ligne);
push(@liste_formes, $token_info[1]);
push(@liste_pos, $token_info[3]);
}
}
close TALISMANE;
#---------------------------------------------------------
#chercher les patrons dans la liste, stocker les résultats
#---------------------------------------------------------
#liste globale pour stocker les patrons trouvés
my @liste_patrons = ();
#on prend chaque fois le tag et sa forme correspondante, au début de la liste, en même temps, on les supprime de leur liste
while (my $tag = shift(@liste_pos)){
my $forme = shift(@liste_formes);
if ($tag eq $patron[0]){ #si trouver le début, on compare les suivants
$terme = "$forme "; #initialiser la chaine comforme au patron requis
$suite_tag = "$tag"; #chaine de tags trouvé
for (my $compteur = 0; $compteur <= $#patron-1; $compteur++) {
#puisqu'on a supprimé le tag quand on le prenais, donc, l'élément premier dans @liste_pos doit maintenant correspondre le 2e dans @patron
if ($liste_pos[$compteur] eq $patron[$compteur+1]){
$terme = $terme.$liste_formes[$compteur]." ";
$suite_tag = $suite_tag.$liste_pos[$compteur];
}
}
#vérifier la suite trouvée comforme au patron jusqu'à la fin
if ($suite_tag eq $chaine_patron){
push(@liste_patrons, $terme); #ajouter dans liste globale
}
}
}
#----------------------------------------
#écriture du résultat dans un fichier txt
#----------------------------------------
my $chainePatron = join("-",@patron);
open(SORTIE, ">:encoding(utf8)", "sortie_patron_$chainePatron.txt");
$count = 1;
foreach $p (@liste_patrons){
print SORTIE "$count\t$p\n";
$count++;
}
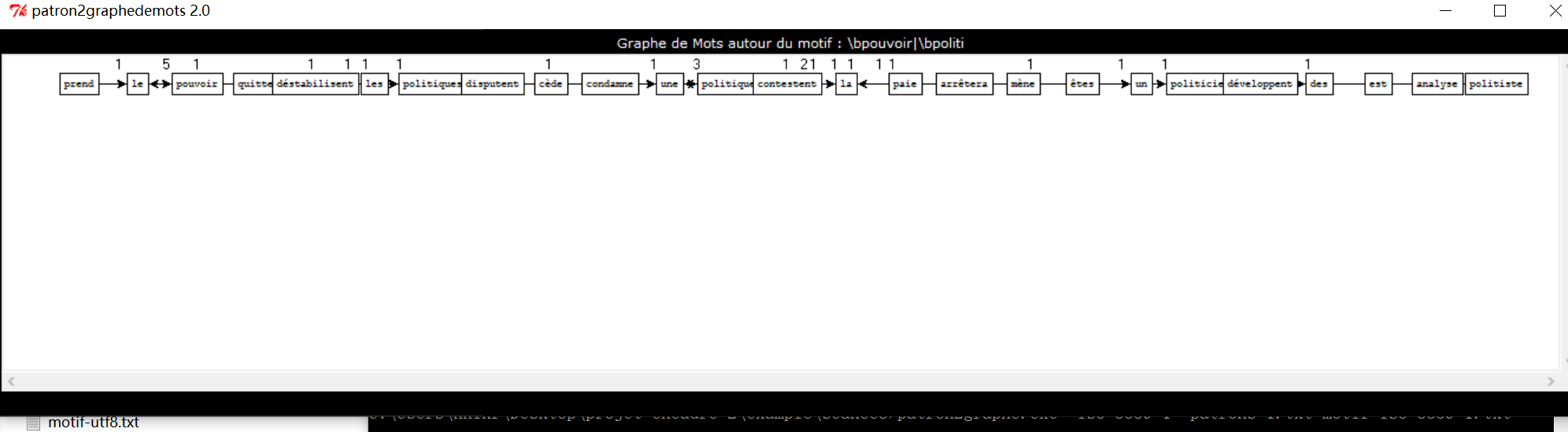
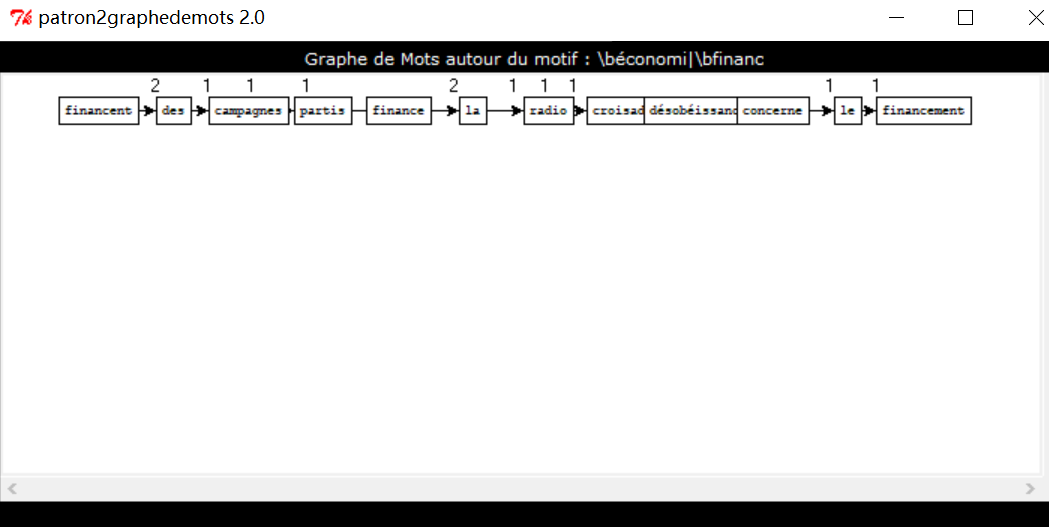
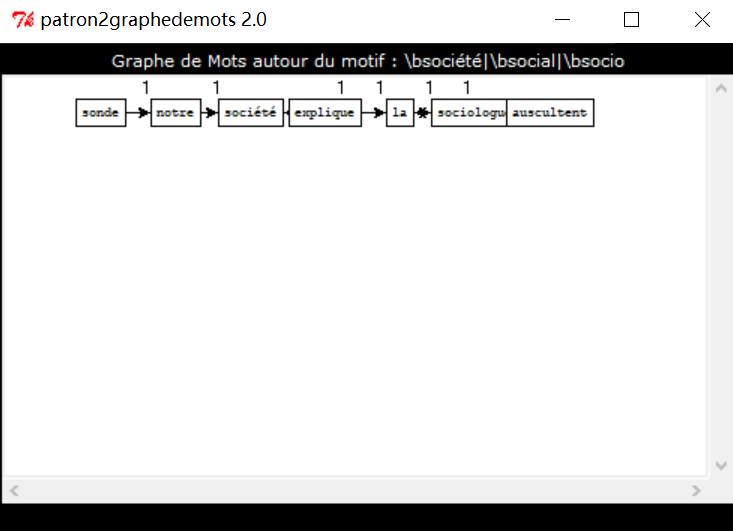
close SORTIE;Avec le logiciel fourni par le prof, j’ai obtenu 3 graphes sur la rubrique « à la Une ». Les trois motifs utilisé sont à propos de « pouvoir/politique », « économie/finance » et « société/socio » respectivement.
Annotation du texte
Savoir plusScripts, résultats obtenus, corpus de test
Savoir plus