Boîte à outil 2
Étiquetage morphosyntaxique et en dépendance syntaxique
Dans cette étape, on veut enrichir les données textuelles extraites précédemment avec des informations syntaxiques. Elles doivent apparaître dans des fichiers au format xml.
Les informations annotées
Les outils utilisés
Intégration des données annotées dans le script
Les modifications du script
Les résultats
Nous souhaitons annoter automatiquement les données, segmentées en tokens, avec des étiquettes syntaxiques. Ces étiquettes indiquent le POS, le lemme, les relations de dépendance et les propriétés morphosyntaxiques des mots.
Nous utilisons deux étiqueteurs: Treetagger et Udpipe.
->TREETAGGER
Pour pouvoir fonctionner, Treetagger a besoin d'un fichier tokénisé en entrée comportant un mot par ligne. Pour transformer les données textuelles au format attendu par Treetagger, on utilise un sous-programme (utf8-tokenize.perl) qui tokénise un texte de la sorte. On obtient un fichier de ce type:
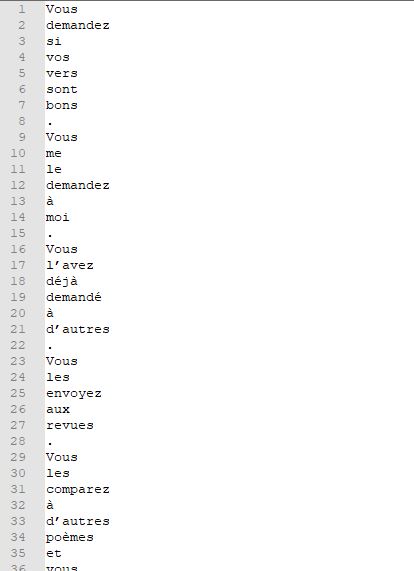
On peut effectuer l'étiquetage à partir du fichier tokénisé. Il est possible d'utiliser plusieurs options du programme pour spécifier les informations que l'on souhaite afficher. Nous utilisons les options -token, -lemma pour faire apparaître les formes et les lemmes des tokens. Il arrive que Treetagger ne reconnaisse pas certains lemmes qu'il rencontre. Il le signale avec une balise "unknown", qui peut être problématique, puisque nous devons construire un fichier xml (format balisé) contenant les annotations. On utilise l'option -no-unknown pour ignorer les lemmes non reconnus. Le fichier annoté se présente ainsi:
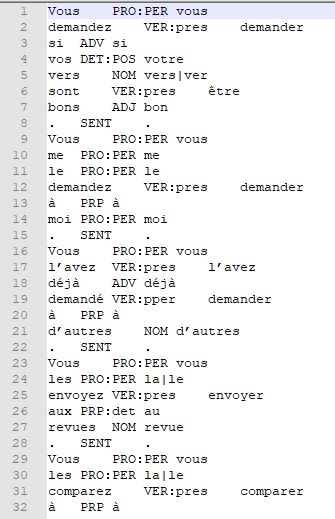
->UDPIPE
Cet étiqueteur est lié au schéma d'annotation UD (Universal Dependencies), il est constitué de jeux d'étiquettes morphosyntaxiques et représente les relations syntaxiques sous la forme d'arbres de dépendance. Udpipe produit des fichiers au format CONLL. Chaque ligne des fichiers CONLL représente un mot avec une série de champs séparés par des tabulations. Ces champs décrivent chaque unité avec son lemme, sa catégorie grammaticale, mais l'étiqueteur fournit aussi des informations qui n'existent pas dans Treetagger: les relations en dépendance. Udpipe présente un autre avantage, la segmentation est déjà incluse dans le programme. Il suffit de lancer le programme en ligne de commande, en spécifiant les options et le modèle de langue voulus. Voici un exemple de sortie généréer par Udpipe:
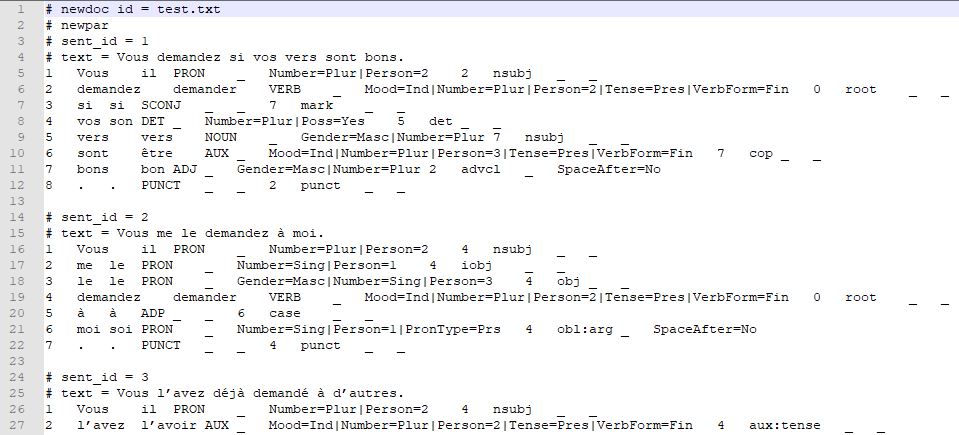
On doit tenir compte de ces deux formats d'annotation pour les intégrer dans la chaîne de traitement, c'est-à-dire annoter tout le contenu textuel des balises "titre" et "description". De plus, on veut inclure les annotations dans des sorties de ce type, au format xml:
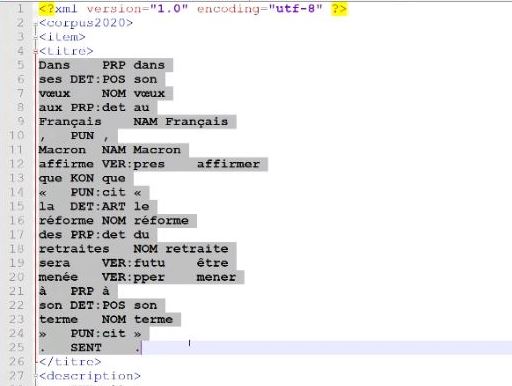
Udpipe produit un fichier au format CONLL, que l'on souhaite convertir en xml. Pour Treetagger, on souhaite obtenir une seule sortie globale au format xml. On enrichit le script de la boîte à outil 1 en optant pour une stratégie d'annotation globale. On annote qu'après avoir extrait toutes les données textuelles, afin de ne pas ralentir le traitement (en effectuant une annotation à chaque extraction du contenu textuel des balises "titre" et "description"). Cette procédure ne pose pas de problème pour Udpipe, mais l'exécution de l'étiquetage de Treetagger nécessite au préalable des textes tokénisés. On insère dans le programme une commande qui tokénise d'abord les textes, puis on les annote dans un second temps. Le programme treetagger2xml-utf8.pl permet de reformater la sortie treetagger au format xml, tandis que le programme udpipe2xml convertit la sortie Udpipe en xml. En résumé, on obtient, pour chaque rubrique et pour chaque étiqueteur, un fichier annoté au format txt et au format xml.
Voici les lignes de code ajoutées au script:
Le script modifié est disponible ici.

Voici des exemples de fichiers xml après l'exécution du script:
Un fichier annoté avec Udpipe au format xml:
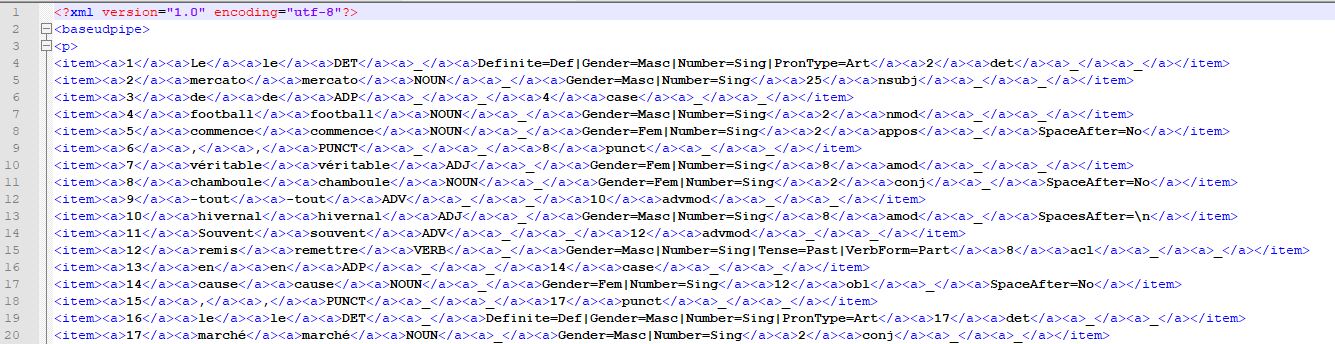
Un fichier annoté avec Treetagger au format xml:
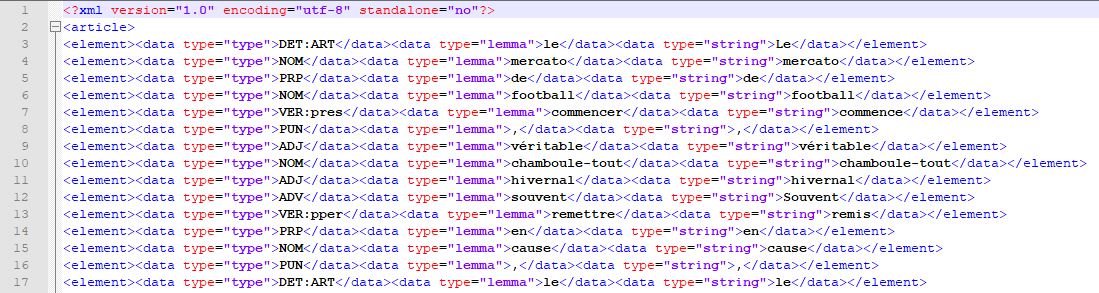
Voici les résultats avec Udpipe après l'exécution du script sur 4 rubriques:
NB: étant donné que les fichiers au format xml sont lourds, nous vous conseillons de les télécharger (clic droit puis "enregistrer le lien sous")