Boîte à Outils 4 - Du texte au graphe
On doit d'abord adapter le script de la BA03 pour que la sortie soit au format CSV et compréhensible par padagraph.
import re
from pathlib import Path
fic = "./corpus-titre-description.udpipe.xml"
sent_buf= {}
obj_buf = []
couples = set()Après avoir importé les bibliothèques nécéssaires à la réalisation du script re pathlib et collections, on peut commencer à instancier les variables qui seront utilisées dans la suite du script et notamment les buffers qui permettent de conserver les données avant le traitement.
On donne à la variable couples la qualité de set
On n'oublie pas de récupérer le path du fichier xml depuis lequel ont va récupérer les informations de relation
On créee comme dans le script Perl une fonction qui permet de nettoyer le résultat de l'expression régulière où l'on transforme tout ce qui n'est pas un caractère alphabétique en une chaîne vide
def clean (s) :
return re.sub("[^\w]", "", s)for line in Path(fic).read_text(encoding="utf-8",errors="ignore").split("\n") :
if line.startswith("<element>") :
m=re.search(r"<id>([0-9]+)</id>",line)
if m:
idx=m.group(1)
fields = re.findall(r"<data [^>]+>([^<]+)</data>", line)
word, lemma, tag, head, rel = fields
lemma = clean(lemma)
sent_buf[idx] = lemma
if rel == 'obj' :
obj_buf.append((lemma,head))
if line == "<item>" :
for obj_lemma, head in obj_buf :
couples.add((f"{sent_buf[head]}", f"{obj_lemma}"))
obj_buf = []
sent_buf = {}On entre ensuite dans le corps du script. On va lire le fichier udpipe ligne par ligne et extraire les informations étiquetées par UDPipe. On peut effectuer cette extraction à l'aide d'expression régulières. Dans mon cas il faut faire une ligne pour reconnaître l'id et une autre ligne pour reconnaitre le contenu des balises data. Avec findall on récupère toutes les informations dans une liste que l'on peut ensuite dépaqueter avec une liste de variable auxquelles ont donne la valeur de chaque élément de la liste.
On va ensuite entrer dans le dictionnaire sent_buf le lemme nettoyé avec comme clé sont index. Si la valeur de la variable relation est objet, on ajoute également à la liste obj_buf le tuple qui contient le lemme et l'index de sa tête.
Pour chaque item (c'est à dire chaque ensemble titre-description), on ajoute dans l'ojet couples le lemme du gouverneur (que l'on récupère grâce au dictionnaire sent_buf) et le lemme de l'objet.
Quand tous les objets de l'item ont été traités, on réinitialise les buffers et on peut recommencer l'opération.
La dernière étape du script constiste en l'affichage des données précédemment récoltée au format accepté par padagraph, c'est à dire un format CSV et en notant par @ les noeuds et par _ les relations. Il faudra aussi afficher les relations séparées de --
print("@Gouv: #id, label")
for lemme in {gov for gov in couples} :
print(f"g_{lemme[0]},{lemme[0]}") #-->(id: lemme et label : la forme)
print("@Dep: #id, label")
for lemme in {dependant for dependant in couples} :
print(f"d_{lemme[1]},{lemme[1]}")
print("_obj:")
for gouv,dep in couples :
print(f"g_{gouv},--,d_{dep}")python BAO3bis.py | curl -X POST -H 'Content-Type: text/csv' --data-binary @- "https://padagraph.magistry.fr/post_csv/EvSa"On peut ensuite à l'aide d'une commande bash envoyer directement le résultat du programme dans padagraph pour obtenir le graph des relations souhaité.
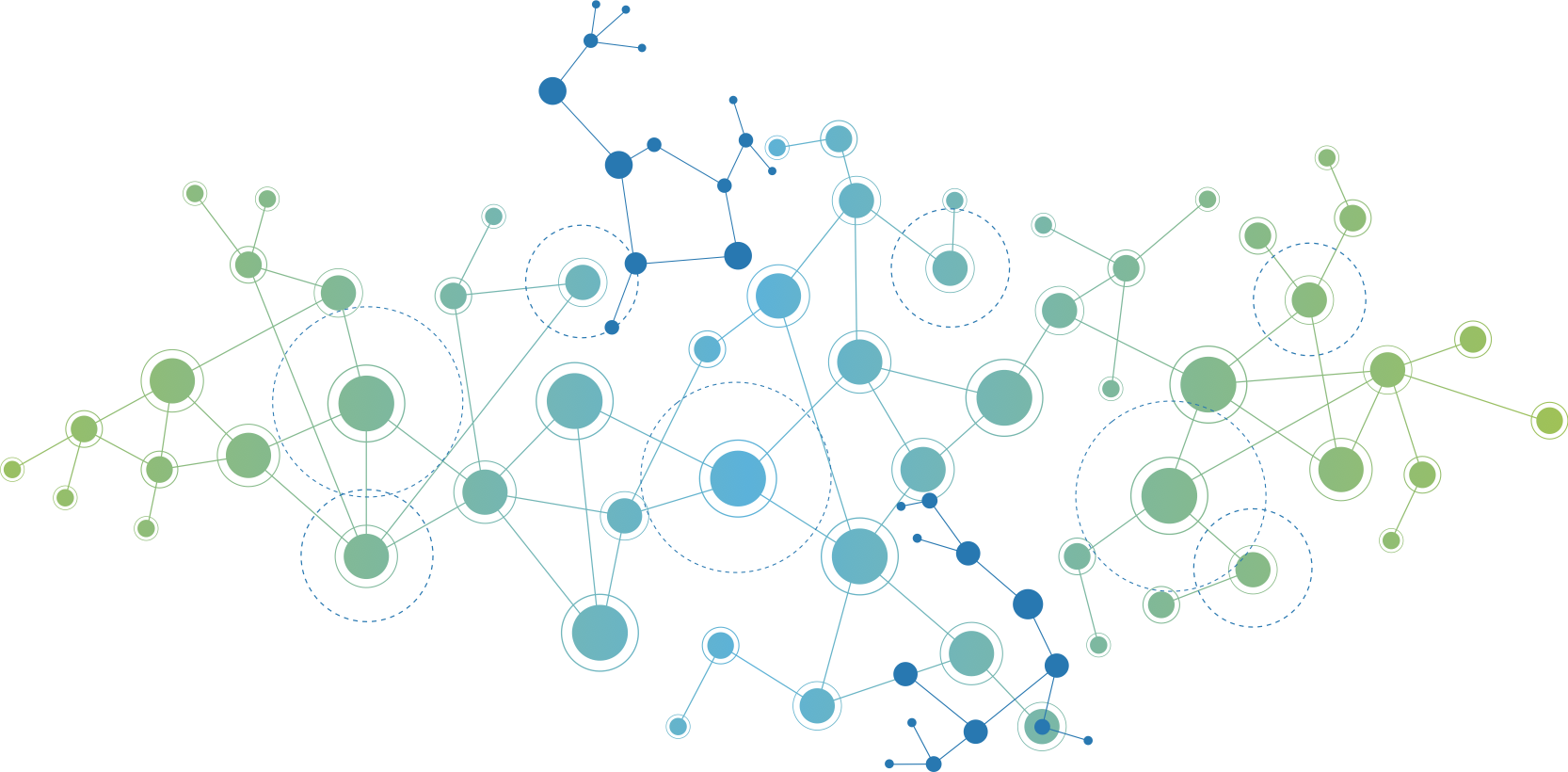
On obtient le résultat suivant
Projet réalisé par Eve Sauvage
En première année de Master Traitement Automatique des Langues