
L'objectif de la troisième boîte à outils est d'extraire des patrons morpho-syntaxiques et des relations de dépendances dans les données que nous avons extraites et annotées lors des deux boîtes à outils précédentes. Un patron morpho-syntaxique est une suite de POS récurrente que l'on observe dans les données.
Nous mettons en oeuvre quatre méthodes pour extraire les patrons et les relations : un script perl, un script python, des feuilles de style xslt et des requêtes xquery. Le commentaire de ces différentes façons de procéder sera l'occasion de mettre en exergue les avantages et les inconvénients de chacune.
Nous exploiterons les fichiers XML annotés par Treetagger pour y trouver des patrons. Pour extraire les relations, nous exploiterons les fichiers udpipe de la BAO2 transformés au format XML via un script récupéré sur icampus. Ci-dessous, un schéma représentant les fichiers d'entrée et les fichiers de sortie de cette BAO3.
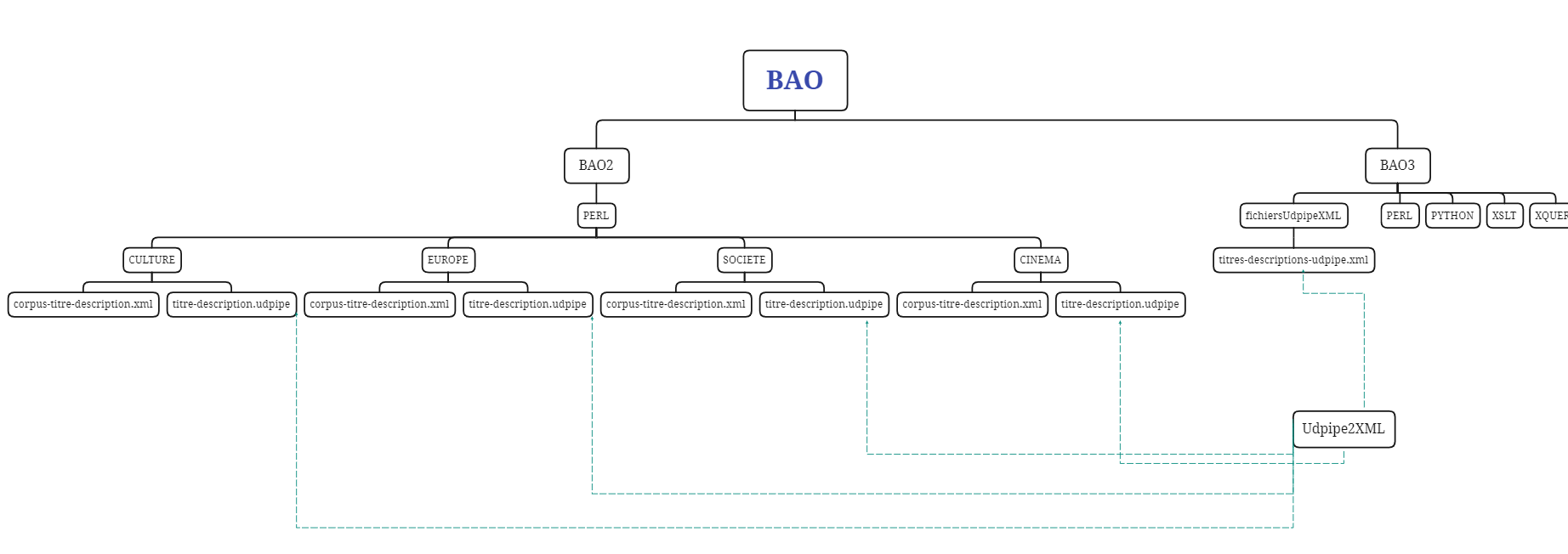
Là encore, les fichiers txt produits sont classés dans des dossiers distincts selon le langage de programmation qui les génère et la rubrique de laquelle on les extraie. Cet ajout personnel est largement commenté à la BAO1.

On récupère les deux arguments que l'on a donnés au programme, le premier est le fichier à traiter et le second le patron recherché. On ouvre en lecture le fichier à traiter et l'on crée une liste contenant les lignes du fichier. Tant qu'il y a des lignes (ou pour mieux traduire ce que fait shift en PERL : tant que l'on peut vider la liste de lignes d'une de ses lignes), on crée une variable terme qui contiendra les mots correspondant au patron. Si la ligne contient le premier élément du patron renseigné (dans la balise XML dédiée à la POS).

Alors on doit lire autant de lignes qu'il y a de POS dans le patron renseigné. On incrémente un indice grâce auquel on vérifie que les POS des lignes suivantes sont bien celles du patron que l'on cherche, si tel est le cas, on ajoute la forme trouvée au syntagme.

On compte enfin le nombre de fois que le syntagme apparaît dans notre flux RSS via un dictionnaire.

Après avoir ouvert le fichier l'annotation udpipe de nos flux RSS que l'on a au préalable mis au format XML, on découpe notre texte sur la base des balises <p>. Autrement dit, on procède à un découpage par phrases. Tant qu'il reste des phrases dans le fichier, on segmente les items (sur la base des retours à la ligne). Pour chacune des lignes que l'on vient de segmenter, si la ligne contient dans la 8ème balise <a> la relation que l'utilisateur a donné en argument au programme.
alors :

La forme du dépendant de la relation renseignée correspond au deuxième groupe de capture de notre regex, soit la deuxième balise <a>.
La position du dépendant de la relation renseignée correspond au premier groupe de capture de notre regex, soit la première balise <a>.
La position du gouverneur de la relation renseignée correspond au troisième groupe de capture de notre regex, soit la 7ème balise <a>.

On recherche la prochaine ligne dont la première balise <a> contient la position du gouverneur et on en extraie la forme contenue dans la seconde balise <a>.
On compte également le nombre de fois que les deux formes sont dans cette relation de dépendance via un dictionnaire.

On applique le même procédé à la différence que l'on recherche la position du gouverneur parmi les premières balises <a> des lignes précédentes au lieu des lignes suivantes.
La particularité du script est qu'il utilise un buffer, une fenêtre glissante qui va parcourir chaque ligne et récupérer des tuples POS/forme.

Nous nous attardons ici surtout sur la fonction d'extraction du patron. Elle prend comme arguments le fichier à traiter et le patron recherché. On créé un buffer, c'est à dire une liste de tuples de longueur égale à celle du patron renseignée par l'utilisateur. Il contient par défaut des pointillés qui seront remplacés par les données lues à chaque ligne. Pour chaque ligne que l'on va lire dans notre fichier, on supprime en effet le premier tuple de notre liste de tuples et si la ligne correspond bien à la chaîne de caractères décrite par la regex (autrement dit si la ligne ne décrit pas l'ouverture ou la fermeture d'une balise titre ou description mais contient bien du texte informatif et étiqueté).

Alors j'ajoute au buffer le tuple POS/forme (que je récupère via les groupes de capture de ma regex). Dans le cas contraire, ou la ligne n'est pas une ligne contenant un token annoté, alors on reforme le buffer par défaut.

Ensuite, on vérifie que la POS que l'on vient d'extraire dans notre buffer correspond à celle du patron au même indice. Si tel est le cas, on l'ajoute au terme et on l'écrit dans le fichier de sortie.
Ce script utilise deux buffers, un buffer de phrase et un buffer de relation objet. Un set "couples" est utilisé pour contenir les dépendants et les gouverneurs.

Pour chaque ligne du fichier, si la ligne commence par la balise <item> (autrement dit, si la ligne décrit l'analyse en dépendance d'un token), on récupère tout le contenu textuel compris entre les dix balises a, qu'on définit comme étant :
1. La position du token
2. La forme du token
3. Le lemme du token
4. La POS du token
5. Qu'importe
6. Qu'importe
7. La position du gouverneur du token courant
8. La fonction syntaxique du token courant
9. Qu'importe
10. Qu'importe
On ajoute ensuite à notre dictionnaire sent_buf la position du token comme clé et son lemme comme valeur.

Si la fonction syntaxique du token de la ligne courante (contenue dans la 8ème balise <a>) est celle recherchée par l'utilisateur, alors on ajoute au buffer de relation le tuple composé du lemme du token courant et de la position de son gouverneur.

Si la ligne ne commence pas par une balise <item> mais par une balise <p>, autrement dit si l'on atteint la fin de la phrase, alors pour chaque tuple lemme / position de gouverneur de notre buffer de relation, on ajoute à notre set de couples le lemme du gouverneur et le lemme du dépendant. On exploite ici le fait que la position du gouverneur contenue dans la deuxième string des tuples du buffer de relation est également une des clés du dictionnaire sent_buf. On décompose ensuite chaque tuple de notre set "couples" et on écrit le résultat dans le fichier de sortie.
On peut extraire un patron via une feuille de style XSLT qui interroge une arborescence XML. Le fonctionnement des feuilles de style XSL est largement documenté sur le site internet produit pour le cours "Document Structuré". Pour chaque balise <element> du fichier XML, si la POS de l'élément correspond à la première POS du patron que l'on souhaite mettre au jour, alors on vérifie les POS des éléments alentours relativement à ce premier élément, de sorte à vérifier s'il s'agit du patron qui nous intéresse. La POS est renseignée dans la première balise <data> de nos fichiers étiquetés via Treetagger à la BAO2. Pour l'exemple illustré ci-dessus, si l'on trouve un élément étant un nom, on s'assure que l'élément suivant soit une préposition et que l'élément encore après soit un nom. Si tel est le cas, on récupère leurs formes, contenues dans la troisième balise <data>.
Pour chaque <item> de chaque phrase, si la 8ème balise <a> contient la relation recherchée, alors on récupère la forme du dépendant à la deuxième balise <a>, sa position à la première balise <a> et la position de son gouverneur à la septième balise <a>.
Si le numéro de la position du dépendant est supérieur à celui de la position du gouverneur, alors on affiche en sortie la forme du dépendant suivie de la forme du gouverneur, contenue dans le premier des éléments précédents dont la position dans la première balise <a> correspond à la position du gouverneur (que l'on vient de trouver dans la septième balise <a> du dépendant).
Si a contrario la position du gouverneur est plus grande que celle du dépendant, on reproduit l'opération en cherchant cette fois-ci le gouverneur parmi les éléments suivants
L'extraction de patrons en xquery est la plus maniable et la plus synthétique de toutes les méthodes que nous avons vues jusqu'à présent. Comme en xslt, on descend dans l'arborescence du fichier jusqu'à attendre les <element>. On déclare autant de variables qu'il y a de POS dans le patron que l'on cherche. La première variable contient la POS de l'élément courant, les deux autres variables contiennent deux éléments qui suivent. On concatène les formes des éléments déclarés dans les variables à condition que la variable 1 soit un nom, et que la POS des variables 2 et 3 soient respectivement une préposition et un nom.
L'extraction de relations en xquery se fait de manière assez similaire à l'extraction de patrons. On définit trois variables, la première contient la fonction syntaxique de l'élément (huitième balise <a>) la seconde sa position (première balise <a>) et la troisième la position du gouverneur : la septième balise <a> A CONDITION que la variable contenant la fonction syntaxique de l'élément contienne bien "objet".
Si la position du dépendant est plus grande que celle du gouverneur, on affiche la forme du dépendant suivie de la forme du premier élément des éléments précédents dont la position à la première balise <a> est égale à la position du gouverneur (septième balise <a> du dépendant). Si la position du gouverneur est plus grande que celle du dépendant, c'est dans les éléments suivants que l'on cherche la forme du gouverneur.