Réalisation
Afin de pouvoir extraire tous les titres et descriptions, j'ai d'abord observé l'arborescence
du flux rss.
Pour parcourir tous les fichiers xml, en Python, je me sers de la méthode
os.walk()
de la librairie os. Cette fonction retourne une liste de tous les fichiers xml.
En Perl, j'accède aux fichiers de manière récursive à l'aide de la fonction parcours_arborescence.
Ensuite, je traite les fichiers par leurs noms (chaque nom correspond en fait à une rubrique). Dans mon travail, j'en utilise 5 :
"média", "international", "voyage", "livres", "sciences".
Le nombre total de fichiers s'y élève à 2848.
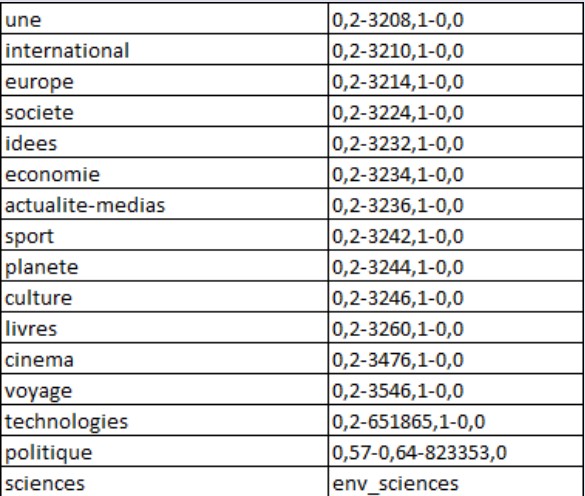
Les codes en Perl et Python, ainsi que les résultats obtenus après l'execution des codes :