Boîte à Outils 1
Extraction des contenus textuels des fils RSS du Monde

ETAPES :
1) Parcourir toute l'arborescence des fils RSS du Monde (classés par rubrique)
2) Extraire leur contenu textuel à l'aide des balises 'title' et 'description'
EN ENTREE :
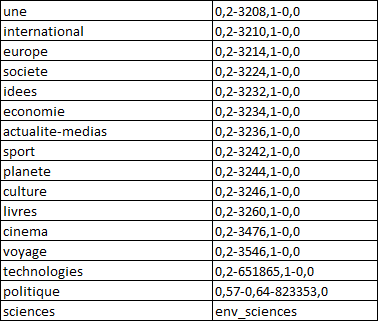
Un dossier de fils RSS trié par mois, jour et heure. Chaque fil RSS contient dans son nom, une rubrique du journal Le Monde (voir correspondances ci-dessous) qui devra
également être spécifiée en entrée du programme. Pour ce projet, les rubriques "A la une" (3208), "culture" (3246) et "planete" (3244) ont été traités.
EN SORTIE :
Une sortie txt et une sortie xml avec le contenu de l'extraction des données du dossier des fils RSS
(en langage Perl et en Python). Exemples ci-dessous :
| Langage | Nom de fichier | Téléchargement |
| Perl | perl-corpus-titre-description-3208.txt | Fichier.txt |
| Perl | perl-corpus-titre-description-3208.xml | Fichier.xml |
PERL
Partie 1/3 : L'entête
L'entête permet de s'assurer du bon fonctionnement
du programme : s'assurer notamment d'avoir des entrées et sorties en encodage UTF-8, ou encore que le
nombre d'arguments passés au programme est exact.
#/usr/bin/perl #----------------------------------------------------------- # Notre script perl prend deux arguments : le nom de l'arborescence # 1) Le nom de l'arborescence 2021 contenant les fils RSS de l'année 2021 # 2) Le nom de la rubrique à traiter ("3208" pour la rubrique "À la une" par exemple). # Ligne de commande : perl BAO1.pl dossier_arborescence rubrique #----------------------------------------------------------- use utf8; use strict; binmode(STDOUT, ":encoding(UTF-8)"); use File::Copy; #----------------------------------------------------------- # Validation des arguments donnés au programme # On s'assure que le bon nombre d'arguments a été fourni par l'utilisateur if ($#ARGV != 1) { print "Le nombre d'arguments est incorrect.\n"; exit; }
Partie 2/3 : Le programme principal
Le programme principal récupère les arguments donnés au programme, c'est ici qu'on initialise également
les variables qui vont nous être nécessaires. On ouvre aussi nos fichiers de sorties dans lesquels
on va écrire nos résultats après parcours d'arborescence et extraction,
avant de déplacer ces fichiers vers leur dossier de sortie correspondants.
#----------------------------------------------------------- # Le programme principal # On prend les arguments et on les stocke dans des variables associées my $repertoire="$ARGV[0]"; my $rubrique="$ARGV[1]"; # On crée une table de hashage pour ne pas avoir de doublons my %h_sans_doublons=(); my $nbItem=0; # On s'assure que le nom du répertoire ne se termine pas par un # "/" à l'aide d'une expression régulière $repertoire=~ s/[\/]$//; # On ouvre deux fichiers afin d'écrire la sortie open my $output_txt, ">:encoding(UTF-8)","perl-corpus-titre-description-$rubrique.txt"; open my $output_xml, ">:encoding(UTF-8)","perl-corpus-titre-description-$rubrique.xml"; # On print un entête xml au fichier xml print $output_xml "\n\n"; # On lance notre fonction "parcours_arborescence_fichiers" qui va fonctionner # de manière récursive sur le répertoire passé en argument &parcours_arborescence_fichiers($repertoire); # On ajoute la balise de fin dans le fichier xml print $output_xml " \n"; #print "$nbItem"; # On ferme les deux fichiers créés close $output_txt; close $output_xml; # On met les fichiers de sortie dans le dossier de sortie BAO1 dédié move("perl-corpus-titre-description-$rubrique.txt", "BAO1") or die "Erreur $!"; move("perl-corpus-titre-description-$rubrique.xml", "BAO1") or die "Erreur $!"; # On sort du programme exit;
Partie 3/3 : Les sous-programmes
Nous avons deux sous-programmes, un sous-programme de parcours et d'extraction des données et un sous-programme
de nettoyage des données. Le premier parcourt de manière récursive le grand dossier contenant tous les fils RSS :
il parcourt chaque dossier et cherche à trouver tous les fichiers dont le nom se termine par la rubrique passée
en argument avec une extension .xml. Une fois trouvés, l'extraction peut commencer à l'aide des balises
'title' et 'description' présents dans ces fichiers xml, qui nous permettent de capturer facilement leur contenu
via les expressions régulières. Cependant, avant d'écrire le contenu extrait, on s'assure qu'on ne l'a pas
déjà rencontré à l'aide d'un dictionnaire, évitant ainsi les doublons d'articles.
Si cette condition est validée, alors on écrit le contenu nettoyé grâce au deuxième sous-programme, qui nettoie
les données, notamment car ces dernières peuvent contenir des caractères spécifique au format xml. De plus, on fait
en sorte d'avoir un point à la fin de chaque titre et description s'il n'y en avait pas ou plusieurs
pour aider l'étiquetage de la prochaine BAO.
#----------------------------------------------------------- # Les sous-programmes # 1) Fonction permettant à la fois de parcourir toute l'arborescence # et d'extraire les titres et descriptions nettoyés de chaque fichier sub parcours_arborescence_fichiers { # On parcourt tous les fichiers du dossier dans l'ordre # en notant les chemins $path au fur et à mesure my $path = shift(@_); opendir(DIR, $path) or die "Le chemin $path n'existe pas : $!\n"; my @files = readdir(DIR); closedir(DIR); foreach my $file (sort @files) { next if $file =~ /^\.\.?$/; $file = $path."/".$file; # si le fichier est un dossier, on continue à parcourir l'arborescence de manière récursive if (-d $file) { &parcours_arborescence_fichiers($file); } # si le fichier est bien un fichier RSS (xml) avec la rubrique souhaitée alors on lit le fichier if (-f $file) { if ($file =~ /$rubrique.+\.xml$/) { open my $input, "<:encoding(UTF-8)",$file; $/=undef; # par défaut cette variable contient \n my $ligne=<$input> ; close($input); # quand on tombe sur une ligne matchant avec cette fonction régulière while ($ligne=~/<item><title>(.+?)<\/title>.+?<description>(.+?)<\/description>/gs) { # si le titre n'est pas déjà dans la table de hashage # alors on écrit dans nos fichiers txt et xml # (on considère qu'un article est un doublon si son titre est identique) if (!(exists $h_sans_doublons{$1})) { # RQ : les tables de hashage on toujours besoin d'une valeur # on met ici une valeur par défaut (1) # on écrit le contenu nettoyé $h_sans_doublons{$1}=1; #$nbItem++; my $titre=&nettoyage($1); my $description=&nettoyage($2); print $output_txt "$titre \n"; print $output_txt "$description \n"; print $output_txt "------------------------\n"; print $output_xml "<item>\n<titre>\n$titre\n</titre>\n <description>\n$description\n</description>\n</item>\n"; } } } } } } # 2) Fonction de nettoyage permettant de nettoyer les données # - on nettoie notamment les CDATA présents pour des sections # qui ne devaient pas être reconnus comme balisage, ainsi que quelques entités XML # - on fait en sorte d'avoir (seul) point à chaque fin de titre # ou de description pour faciliter l'étiquetage en BAO2 sub nettoyage { my $texte=shift @_; $texte=~s/(^<!\[CDATA\[)|(\]\]>$)//g; $texte=~s/<.+?>//g; $texte=~s/'/'/g; $texte=~s/"/"/g; $texte.="."; $texte=~s/\.+$/\./; return $texte; } #-----------------------------------------------------------
PYTHON
Partie 1/3 : L'entête
La différence notable entre Python et Perl dans l'entête se trouve au niveau de
l'importation des bibliothèques, notamment afin intéragir avec le système ou pour créer
les expressions régulières, choses qui sont intégrés dans perl par défaut.
#!/usr/bin/python3 #----------------------------------------------------------- # Ligne de commande : python3 BAO1.py dossier_arborescence rubrique #----------------------------------------------------------- # Les bibliothèques # Importation des bibliothèques import sys import re import os import shutil #----------------------------------------------------------- # Expression régulière afin de trouver les éléments titre et description # .+? permet à l'expression de ne pas avoir un comportement "gourmand" regex_item = re.compile("<item><title>(.+?)<\/title>.+?<description>(.+?)<\/description>")
Partie 2/3 : Le programme principal
Pour le programme principal, la différence entre Python et Perl se situe au niveau de l'emplacement :
la fonction principale doit impérativement être à la toute fin du programme, ou du moins, après les sous-fonctions
qu'elle utilise. Si cette condition n'est pas remplie, le programme retournera une erreur,
ne connaissant pas les fonctions qui sont déclarés après elle. Ce problème ne se pose pas dans Perl, qui
aura une lecture plus "globale" de l'ensemble du fichier et des fonctions qu'il contient. Autre subtilité :
Python ne permettra pas de déplacer un fichier si celui-ci existe déjà dans le dossier, il faut donc quelques
étapes supplémentaires pour supprimer l'ancien fichier avant de déplacer le fichier.
Perl quant à lui, écrasera directement le fichier qui porte le même nom.
# Fonction principale if __name__ == "__main__": if len(sys.argv) != 3: print("Nombre d'arguments incorrects !\n La bonne commande est par exemple : python3 BAO1.py 2021 3208") else: # on prend les arguments donnés au programme # les fichiers de sorties ont un nom prédéfini repertoire = sys.argv[1]; rubrique = sys.argv[2]; fichier_txt = f"python-corpus-titre-description-{rubrique}.txt"; fichier_xml = f"python-corpus-titre-description-{rubrique}.xml"; # on écrit dans les fichiers txt et xml en n'oubliant pas l'entête et les baliseswith open(fichier_txt, "w", encoding="utf-8") as output_txt: with open(fichier_xml, "w", encoding="utf-8") as output_xml: header = "\n \n" output_xml.write(header) # on retrouve nos variables globales ici l_sans_doublons = [] #nb_item = 0 parcours_arborescence_fichiers(repertoire, rubrique, fichier_txt, fichier_xml) output_xml.write(" \n") #print(nb_item) if os.path.exists(f"./BAO1/{fichier_txt}"): os.remove(f"./BAO1/{fichier_txt}") if os.path.exists(f"./BAO1/{fichier_xml}"): os.remove(f"./BAO1/{fichier_xml}") # On met les fichiers de sortie dans le dossier de sortie BAO1 dédié shutil.move(fichier_txt, "BAO1") shutil.move(fichier_xml, "BAO1") #-----------------------------------------------------------
Partie 3/3 : Les sous-programmes
La seule différence notable du programme Python au niveau des sous-programmes est que
la phase de parcours et la phase d'extraction ont été séparées en deux sous-fonctions, contrairement
au programme en Perl qui le regroupait en un seul sous-programme. Le reste du code est plus ou moins similaire
et sur le même principe que le programme Perl, mais "traduit" en langage Python.
#----------------------------------------------------------- # Les fonctions # Fonction de nettoyage du texte permettant d'enlever les CDATA présents pour des sections # qui ne devaient pas être reconnus comme balisage def nettoyage(texte) : textclean = re.sub("<!\[CDATA\[(.*?)\]\]>", "\\1", texte) textclean += "." textclean = re.sub("\.+$", ".", texteclean) return textclean # Fonction permettant d'extraire les informations sur un (seul) fichier RSS # et d'écrire dans le fichier txt chaque titre et description suivi d'une séparation # et d'écrire dans le fichier xml chaque titre et description entouré de balises def extract_un_fil(fichier_rss, fichier_txt, fichier_xml): # on lit le fichier RSS with open(fichier_rss, "r", encoding="utf-8") as input_rss: lignes = input_rss.readlines() texte = "".join(lignes) # pour chaque élément matché (deux groupes) for m in re.finditer(regex_item, texte): # pour éviter les doublons, on crée une variable globale sans doublons de type liste global l_sans_doublons # si le titre n'est pas déjà dans la liste # alors on écrit dans nos fichiers txt et xml # (on considère qu'un article est un doublon si son titre est identique) if m.group(1) not in l_sans_doublons: # on l'ajoute dans la liste l_sans_doublons.append(m.group(1)) #global nb_item #nb_item += 1 titre_net = nettoyage(m.group(1)) description_net = nettoyage(m.group(2)) output_txt.write(f"{titre_net}\n{description_net}\n") output_txt.write("-----------------------------\n") item_xml = f"- \n
\n" output_xml.write(item_xml) # Fonction de parcours d'arborescence permettant de parcourir tous les fichiers RSS xml # selon la rubrique choisie def parcours_arborescence_fichiers(repertoire, rubrique, fichier_txt, fichier_xml): if not os.path.isdir(repertoire) : print( "Le chemin n'exite pas !" ) else : # pour tous les fichiers du répertoire for fichier in os.listdir(repertoire): # on joint le chemin f = os.path.join(repertoire, fichier) # si le fichier est un dossier, on continue récursivement le parcours # sur les dossiers de ce nouveau répertoire if os.path.isdir(f): parcours_arborescence_fichiers(f, rubrique, fichier_txt, fichier_xml) # si le fichier on est un fichier RSS avec la bonne rubrique if os.path.isfile(f) and f.endswith(".xml") and rubrique in f: extract_un_fil(f, fichier_txt, fichier_xml)\n{titre_net}\n \n\n{description_net}\n \n