



Voici quelques scripts principaux:
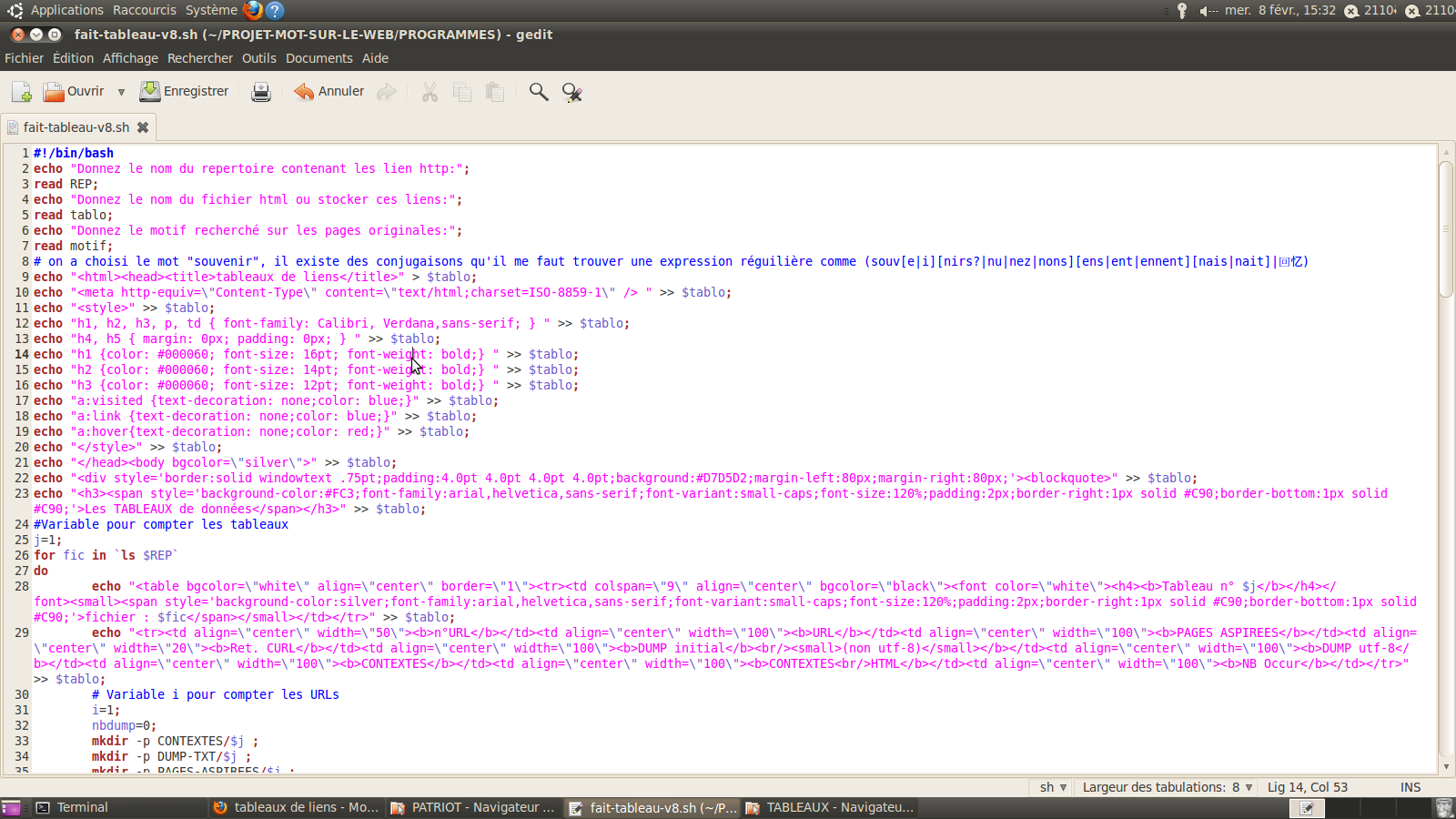
1.Un script qui produit un fichier HTML plusieurs tableaux à 3 colonnes chacun regroupant ces URLs, les pages aspirées correspondantes, les DUMPS des pages aspirées obtenus avec lynx.
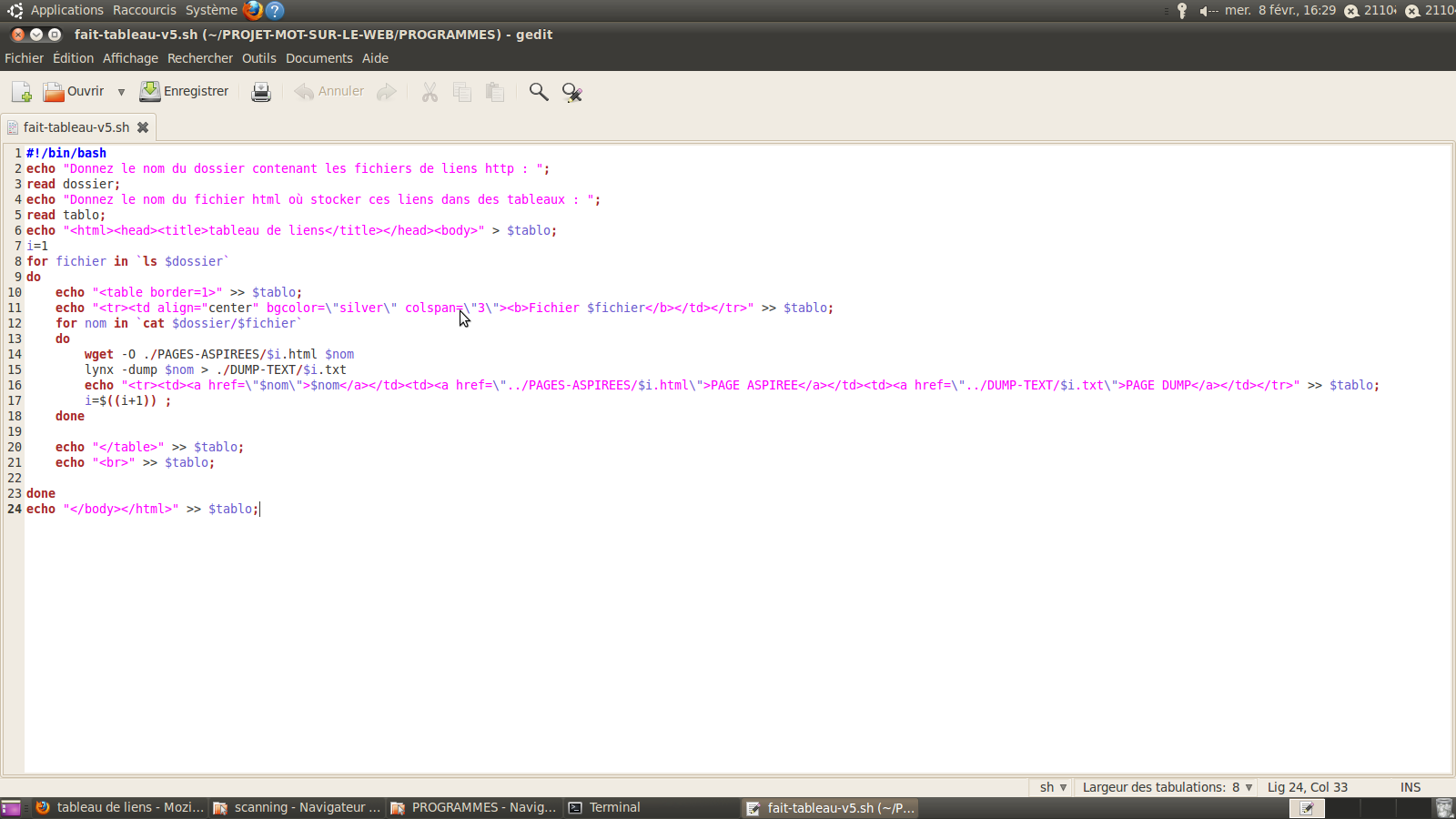 2.Script qui produit un fichier HTML contenant plusieurs tableaux à 4 colonnes chacun regroupant ces URLs, les pages aspirées correspondantes, les DUMPS des pages aspirées obtenus avec lynx, les contextes obtenus avec egrep.
2.Script qui produit un fichier HTML contenant plusieurs tableaux à 4 colonnes chacun regroupant ces URLs, les pages aspirées correspondantes, les DUMPS des pages aspirées obtenus avec lynx, les contextes obtenus avec egrep.
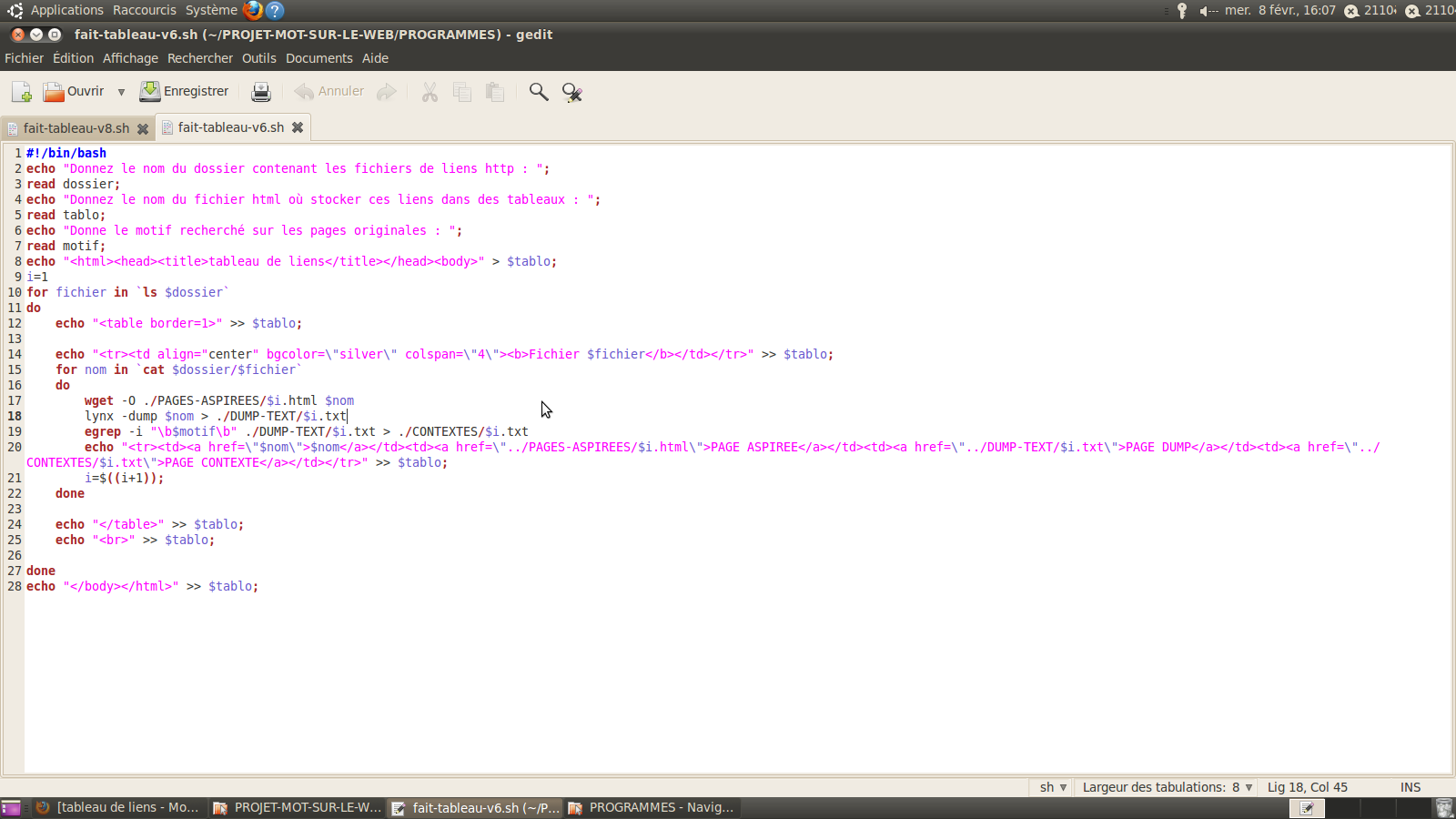
3.script final avec les motifs recherchés
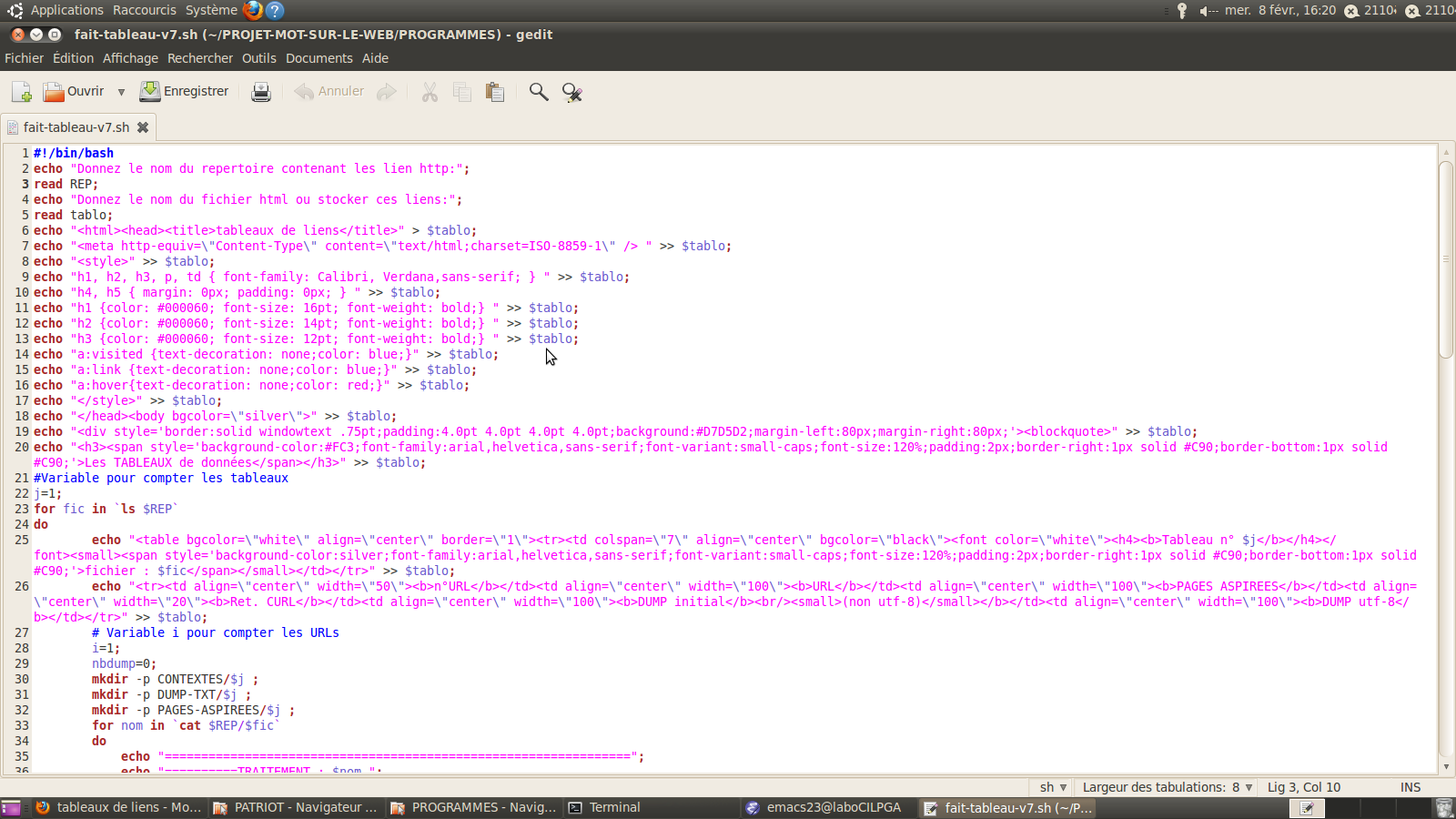
Quelque commandes utilisées
mkdir : Crée un dossier.
echo: Affiche du texte sur la sortie standard
curl:aspire (télécharge) le contenu des pages web(URLs).
iconv: modifie l'encodage des fichiers des pages aspirées.
lynx: extrait des fichiers *.txt à partir des fichier *.html.
egrep: Permet d'afficher les lignes correspondant à un motif donné dans un fichier donné.
cat: lit les fichier texte et concatène les contextes.