Screenshots commentés
Quelques screenshots de présentation du script:
Cette capture montre les premières lignes de notre script. Il est intéressant de noter la ligne de html redirigée par le chevron “>” ainsi que l'ouverture de la première boucle qui permet de lire chacun des fichiers contenus dans le répertoire “URLS”.
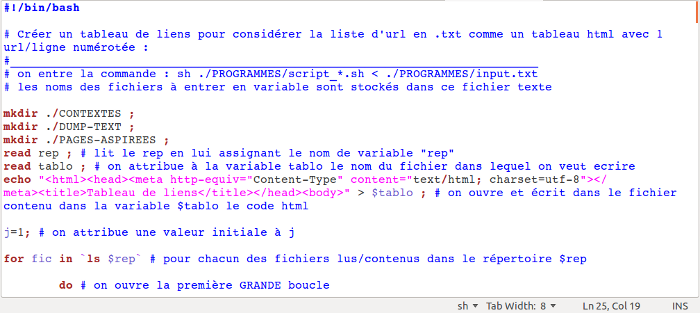
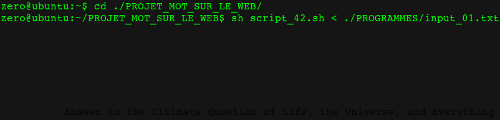
C'est ici que tout commence. Il faut rediriger vers le script le fichier “input_01.txt” qui va indiquer au script quel est le fichier contenant les URLS et où rediriger les sorties .html.
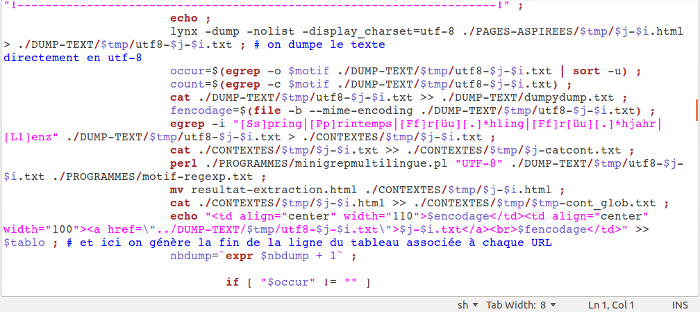
Voilà le coeur du script, les différents traitements qui vont nous permettre d'extraire les données qui nous intéressent. On retrouve donc dans l'ordre:
lynx qui permet de dumper le texte
cat qui va concaténer tous les dumps dans un seul fichier .txt
egrep qui extrait la ligne où apparaît l'occurence du mot recherché
perl qui lance le script créé par Serge Fleury et Pierre Marchal qui redirige en sortie les contextes directement au format .html
Cela ne représente qu'un échantillon des différents traitements effectués, puisque n'apparaît pas par exemple iconv qui permet de modifier l'encodage d'un dump.
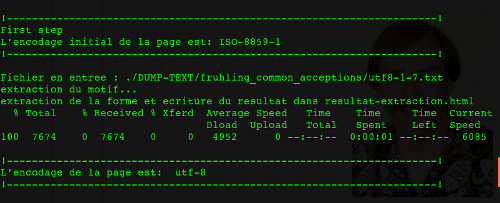
Et enfin, le script à l'oeuvre! (LW approved)
Cliquez >ici< pour télécharger le script.
Tableau de sortie
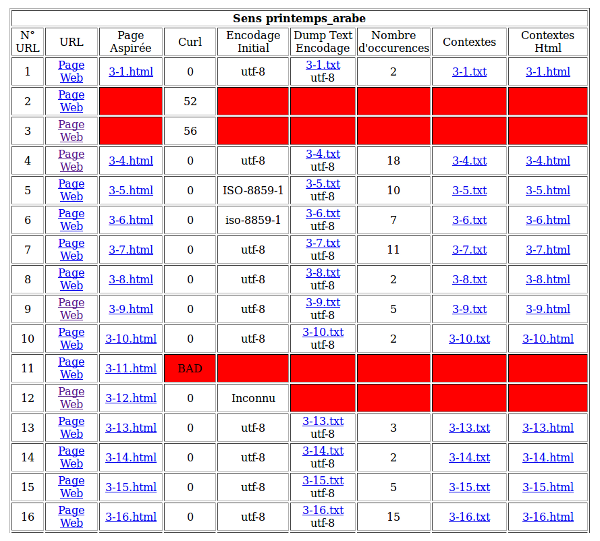
Cliquez sur la miniature pour accéder aux tableaux de résultat.
Le terme "BAD" qui apparaît dans le tableau indique qu'une URL a été correctement aspirée par curl, mais que le contenu est du type "Bad Request" ou "error 400".
Enchaînement des boucles
Un petit schéma vaut toujours mieux qu'une longue explication.
Voici schématisées les différentes étapes qui nous ont permis d'extraire à partir d'un corpus d'URLs sélectionnées les occurences du mot “Printemps” et leur contexte :
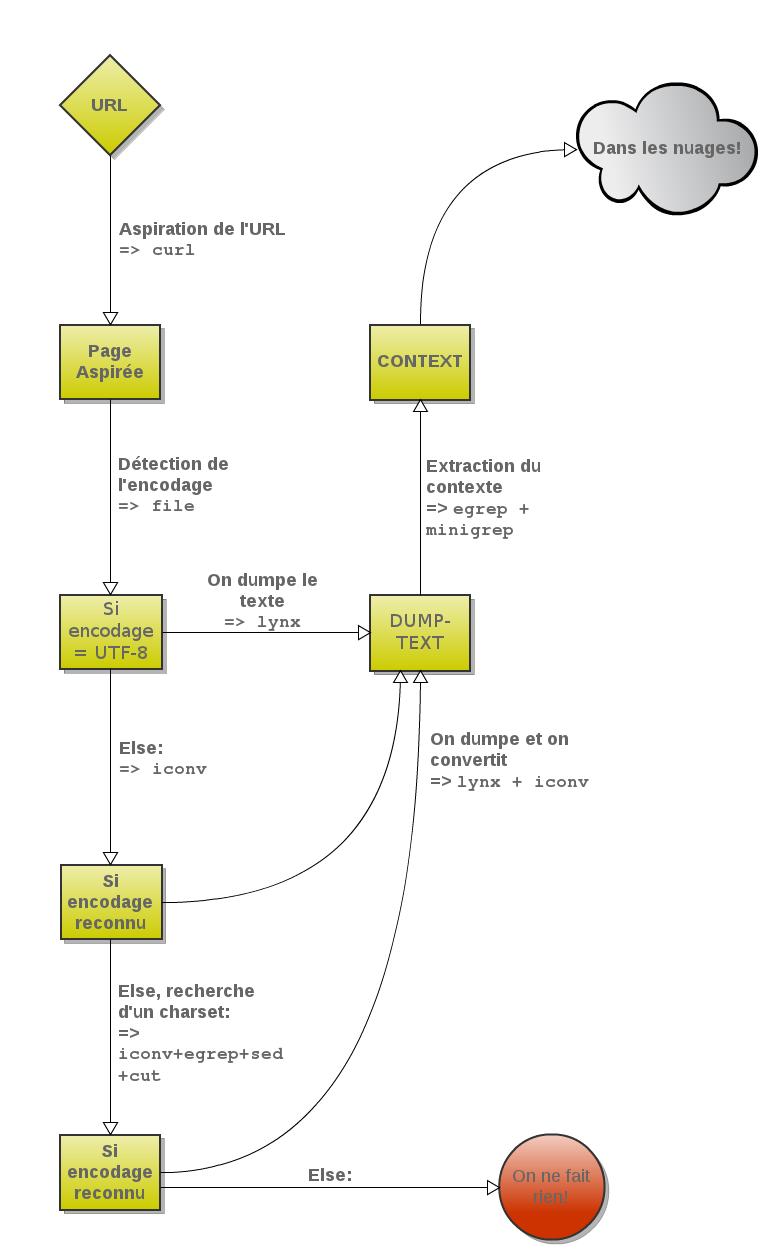
Cliquez sur la miniature pour agrandir l'image.
On applique une boucle itérative (c'est-à-dire considérer tour à tour chacun des éléments d'un ensemble) :
Pour chacune des urls, je veux aspirer la page depuis l'adresse http:// et la sauvegarder localement dans le dossier des pages aspirées:
Si tout s'est bien passé,
Si la page est en UTF-8,
et si c'est vrai,
...alors je dumpe le texte !
Je vais ensuite extraire les contextes autour du mot choisi.
Sinon :
Quel est l'encodage de la page ?
...il faut déterminer l'encodage...
Si l'encodage est reconnu,
extraire le texte et l'encoder en UTF-8
Sinon :
...on ne peut rien faire !
Voici grossièrement le schéma de la chaîne de traitement du projet “mot sur le web”...
Dans le tableau final, nous avons ajouté quelques gadgets comme un traitement capable de compter le nombre d'occurences figurant dans la page aspirée.