Contextes
Le passage des pages aspirées et dumpées (html2text) à la moulinette Minigrep nous permet d'obtenir en sortie le contexte du mot recherché.
Le motif est traité par une expression régulière, et interprété sous forme de fichier texte par le programme Perl. Le programme a été intégré à notre script afin qu'il soit lancé une fois pour chaque fichier d'url traité mais aussi une fois pour chaque corpus et une dernière fois sur l'intégralité des corpus. Le fichier de sortie nous donne la ligne comprenant le motif recherché, mais aussi la ligne d'avant et celle d'après !
Le programme Minigrep est téléchargeable à droite >>>
Il s'installe à l'aide du terminal et quelques lignes de commande sont nécessaires :
sudo perl -MCPAN -e 'install Unicode::String'
make test
make install
La première ligne vérifie si la version de Perl installée sur la machine est compatible avec le programme, et installe la fonction Unicode nécessaire pour la sortie en UTF-8.
Et Minigrep est fourni avec un mode d'emploi sur la manière de l'éxécuter : on invoque
perl minigrepmultilingue.pl "UTF-8" chemin_relatif_vers_dumpydump.txt chemin_relatif_vers_motif.txt ;
> Les résultats de l'extraction <
Bonus
Voici deux petits programmes Perl dont nous avons eu besoin pour passer nos sorties dans les outils Wordle et Le Trameur :
est un script qui (un peu moins bien que son nom l'indique), à partir de la sortie dumpydump.txt (c'est-à-dire l'intégralité des pages dumpées en format texte), donne en sortie un fichier texte avec le motif recherché (à entrer à la main dans le script - nous l'avons pré-formaté pour toutes nos sorties) encadré par ses contextes gauche et droit de la ligne sur laquelle il apparaît.
La sortie html générée par minigrep.pl (un clic sur la droite) est plus riche que le fichier contenant le mot et ses contextes d'après les pages dumpées, car minigrep donne un contexte plus large autour du mot (une ligne avant et une ligne après sont récupérées).
Le problème est que la sortie proposée par minigrep est aménagée pour être lisible et esthétique, or ce qui nous intéresse afin de pouvoir l'analyser à l'aide d'autres outils : c'est le texte brut ! Ce script dégage donc toutes les balises html et numéros de ligne indésirables à l'aide d'une commande de filtrage améliorée qui recherche et remplace par la même occasion !
PS : les motifs à rechercher et remplacer sont modifiables à l'intérieur du script.
On les lance dans le terminal par la commande qui comprend deux arguments :
perl nomduscript.pl fichier_a_traiter fichier_sortie.txt
Nuages de mots
Pour chaque corpus, nous obtenons trois nuages. Un nuage qui reprend l'ensemble des URLS d'une langue, un pour les acceptions communes et un troisième pour l'idiome "Printemps Arabe".
Les nuages des corpus globaux.
La version agrandie du nuage du corpus Français.
{kind=link}
La version agrandie du nuage du corpus Allemand.
{kind=link}
La version agrandie du nuage du corpus Anglais.
{kind=link}

Les nuages du corpus Français.
La version agrandie du nuage du corpus des acceptions communes.
{kind=link}
La version agrandie du nuage du corpus de l'idiome "Printemps Arabe".
{kind=link}
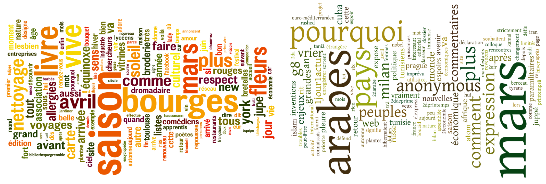
Les nuages du corpus Anglais.
La version agrandie du nuage du corpus des acceptions communes.
{kind=link}
La version agrandie du nuage du corpus de l'idiome "Printemps Arabe".
{kind=link}

Les nuages du corpus Allemand.
La version agrandie du nuage du corpus des acceptions communes.
{kind=link}
La version agrandie du nuage du corpus de l'idiome "Printemps Arabe".
{kind=link}

Discussion
Il est possible de faire une comparaison entre les résultats des corpus ainsi que les résultats de chaques langues prises séparément.
Ayant orienté notre recherche d'URLS, pour moitié acceptions communes, moitié idiome "Printemps Arabe", on remarque dans les corpus qu'à travers les langues que l'adjectif "Arabe" et ses traductions ont pris une part prépondérante comparé aux mots traditionnellement associés à "Printemps".
A travers les trois langues traitées, le mot "Prague" est présent dans chacun des trois corpus, en référence au premier emploi du mot "Printemps" sous son sens révolutionnaire.
Chaque langue, avec le corpus qui lui est associé, présente des spécificités propres à l'usage du mot "Printemps" :
en Allemand, les termes de symboles et de poèmes apparaissent de manière distincte et soulignent le caractère poétique de ce mot
en Anglais, ce mot est centré sur le champ sémantique de la nature, associé à une idée de mouvement, ce qui correspond à l'étymologie du mot
en Français, le terme est largement associé aux festivals et évènements marquant le début d'une nouvelle période (nettoyage de printemps, voyages...), idée de réveil, de renouveau.
Le mot de la fin :
Travailler sur ce projet, nous aura fait mettre en œuvre une somme considérable de différents savoirs. Veille, Programmation, Organisation & Construction, Travail en Equipe.
Ce fût une expérience enrichissante qui nous aura cependant fait prendre conscience de nos multiples faiblesses dans chacun des domaines précédemment cités.
Merci à Serge Fleury, Jean-Michel Daube et Rachid Belmouhoub.