
Boîte à outils #1
• Les objectifs
L'objectif principal de cette boîte à outils est d'extraire le contenu textuel des fils rss tirés du journal Le Monde, sur l'année 2011. Pour ce faire, nous avons dû réaliser un script qui, en plus de permettre l'extraction du titre et du résumé de chaque article contenus dans les balises ‹title› et ‹description›, permettait également de régler les difficultés suivantes:– Problèmes d'encodages : les fils en entrée ne sont pas tous encodés de la même manière.– Présence de scories d'encodage : remplacer les entités HTML et les caractères spéciaux.– Obligation d'avoir une sortie au format XML : s'assurer de construire du XML bien formé.
– fichiers XML écrits sur une ou plusieurs lignes : homogénéisation.
Pour extraire du texte des fils rss, nous avons exploré trois méthodes différentes:
– Une méthode "rustique" utilisant des expressions régulières
– Une méthode utilisant la bibliothéque XML::RSS
– Une méthode utilisant la bibliothèque XML::libXML
• Le corpus
L'arborescence ci-dessous donne à voir la structuration de notre corpus.
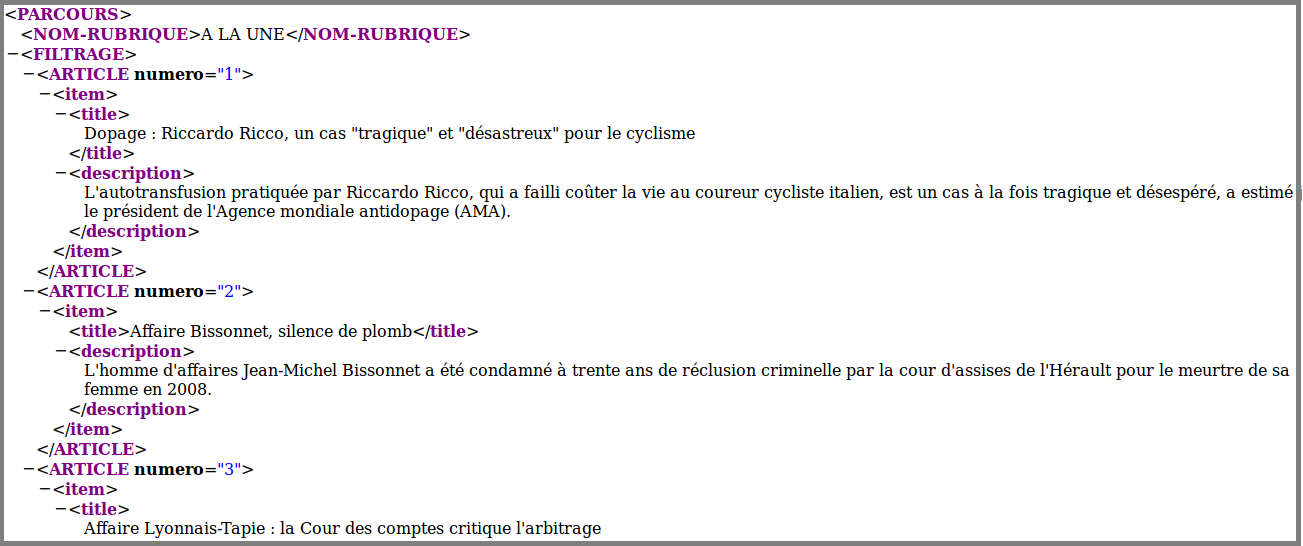
Nous avons choisi de ne travailler que sur la rubrique A LA UNE, représentée par le numero de fichier 3208.
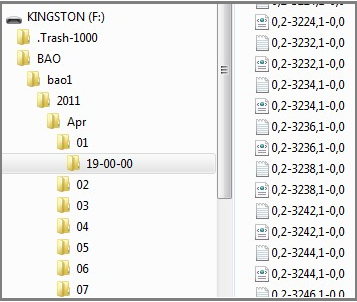 Arborescence fils rss
Arborescence fils rss
• Les différentes méthodes
Les trois scripts réalisés ne présentent en surface que très peu de diffèrences. En effet on pourra remarquer que la procédure principale est identique pour les trois méthodes.
On retrouvera pour chacune d'entre elles les étapes suivantes:
– Création des fichiers pour stocker le résultat en sortie
–Création de la forme du document XML
– Nettoyage des entités HTML et caractères spéciaux
– Parcours de l'arboresence
– Détéction de l'encodage
– Test sur la clef de la variable $contenu, à l'aide d'une table de hachage, pour éviter de récupérer des doublons.
L'ensemble de ces étapes sont présentées brièvement dans les extraits de scripts encadrés en gris. La principale diffèrence, entre ces trois méthodes, se situe au niveau de la tâche de filtrage du texte (voir les encadrés rouges).
a) Méthode "rustique": Regexp
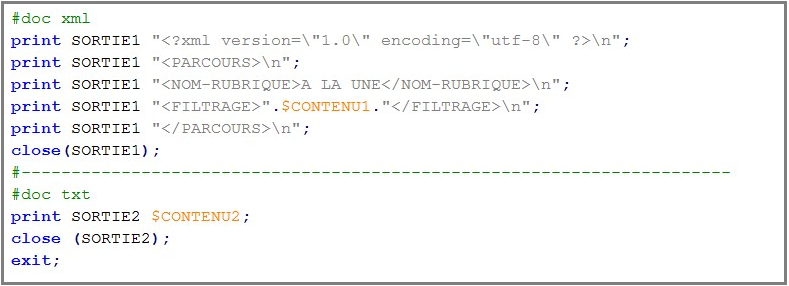
• On crée une sortie au format txt et une autre au format xml afin de récupérer les données générées à l'issue du traitement.

• On précise la forme que devra avoir notre document XML (solution à une des difficultés de départ) .
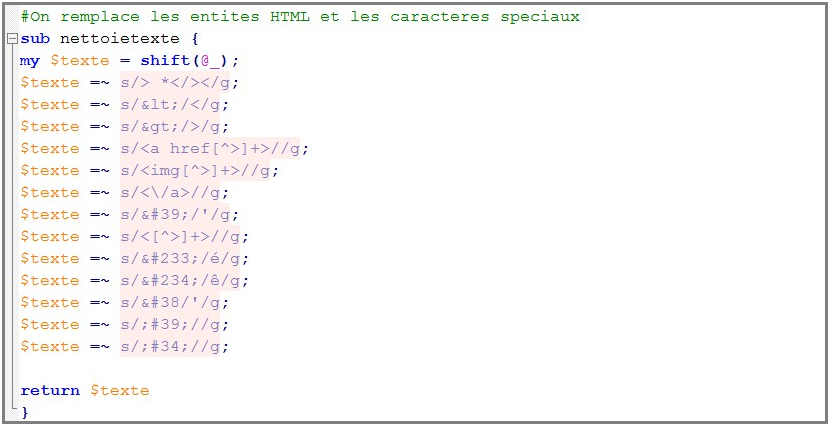
• On met en place une fonction qui permettra de remplacer tous les caractères spéciaux et les entités HTML qui nous posent problème (solution au problème de départ) . Nous aurions également pu utiliser la fonction XML ::Entities::decode, issu du module XML ::Entities, qui permet de décoder toutes les entités.
On parcours l'arborescence de notre corpus en appelant la fonction parcoursarborescence. Si le ficher n'existe pas on passe au suivant et si on tombe sur un répertoire on relance le sous-programme.

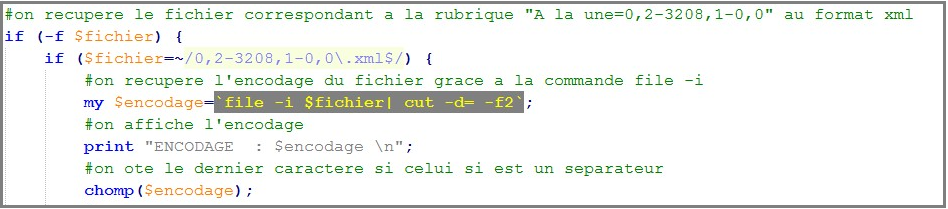
• On ne récupère que les fichiers correspondants à la rubrique A LA UNE, puis détection de l'encodage avec la commande file -i.
• On fait en sorte de n'avoir qu'une seule ligne pour chaque fichier à traiter. Pour cela, on supprime les éventuels caractères séparateurs présents en fin de ligne, puis on procède à la concatenation de toutes les lignes (on règle ainsi le problème des différences de forme entre les fichiers!).
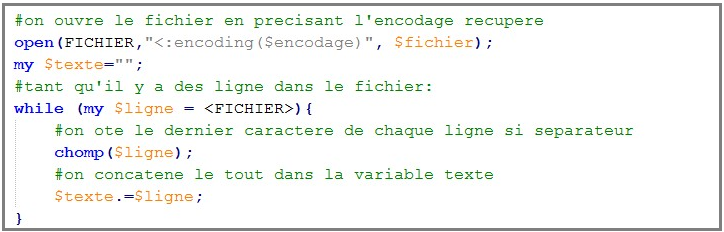
• Usage d'une expression régulière pour le filtrage du texte. Cette partie du script (encadrée en rouge) sera modifiée dans les deux autres méthodes utilisées que nous présenterons par la suite.

• Enfin, on lance la procédure de nettoyage du texte (sub nettoietexte).

• Pour visualiser le script en entier cliquez ICI
b) Bibliothèque XML::RSS
• On utilise ici une librairie de perl, efficace et adaptée, pour la récupération des éléments dans un fichier RSS. Pour ce faire il est nécessaire de la déclarer au préalable en début de script. Puis il faudra instancier un nouvel objet RSS...

• ...et le parser!
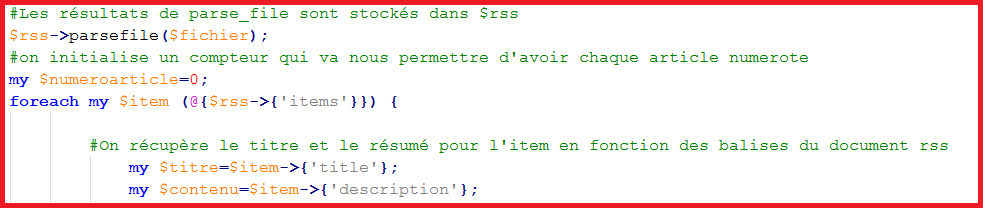
• Pour visualiser le script en entier cliquez ICI
c) Bibliothèque XML::libXML
• Cette librairie de perl permet d'accéder aux données stockées dans des documents XML. Les documents sont traités comme un arbre de noeuds et les données de ces noeuds sont accessibles en appelant des méthodes sur les objets, eux-mêmes noeuds. On n'oubliera pas, là encore, de déclarer la bibliothèque au début du script.

• Initialisation du module XML::libxml, puis extraction du titre et du contenu à partir des noeuds.
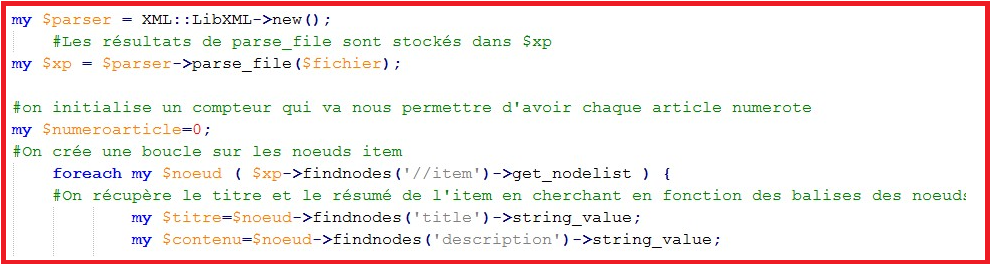
• Pour visualiser le script en entier cliquez ICI
• Présentation des résultats:
Quelque soit la méthode utilisée pour la tâche de filtrage, les fichiers récupérés en sortie sont identiques. On notera, tout de même, que la méthode utilisant une expression régulière est un peu plus longue en terme de temps de traitement que les deux autres.
SORTIE TXT
Pour voir le fichier, cliquez sur l'image.

SORTIE XML
Pour voir le fichier, cliquez sur l'image.
L'objectif principal de cette boîte à outils est d'extraire le contenu textuel des fils rss tirés du journal Le Monde, sur l'année 2011. Pour ce faire, nous avons dû réaliser un script qui, en plus de permettre l'extraction du titre et du résumé de chaque article contenus dans les balises ‹title› et ‹description›, permettait également de régler les difficultés suivantes:
Pour extraire du texte des fils rss, nous avons exploré trois méthodes différentes:
– Une méthode "rustique" utilisant des
– Une méthode utilisant la bibliothéque
– Une méthode utilisant la bibliothèque
• Le corpus
L'arborescence ci-dessous donne à voir la structuration de notre corpus.
Nous avons choisi de ne travailler que sur la rubrique A LA UNE, représentée par le numero de fichier 3208.
Arborescence fils rss
• Les différentes méthodes
Les trois scripts réalisés ne présentent en surface que très peu de diffèrences. En effet on pourra remarquer que la procédure principale est identique pour les trois méthodes.
On retrouvera pour chacune d'entre elles les étapes suivantes:
– Création des fichiers pour stocker le résultat en sortie
–Création de la forme du document XML
– Nettoyage des entités HTML et caractères spéciaux
– Parcours de l'arboresence
– Détéction de l'encodage
– Test sur la clef de la variable $contenu, à l'aide d'une table de hachage, pour éviter de récupérer des doublons.
L'ensemble de ces étapes sont présentées brièvement dans les extraits de scripts encadrés en gris. La principale diffèrence, entre ces trois méthodes, se situe au niveau de la tâche de filtrage du texte (voir les encadrés rouges).
a) Méthode "rustique": Regexp
• On crée une sortie au format txt et une autre au format xml afin de récupérer les données générées à l'issue du traitement.
• On précise la forme que devra avoir notre document XML (solution à une des difficultés de départ) .
• On met en place une fonction qui permettra de remplacer tous les caractères spéciaux et les entités HTML qui nous posent problème (solution au problème de départ) . Nous aurions également pu utiliser la fonction XML ::Entities::decode, issu du module XML ::Entities, qui permet de décoder toutes les entités.
On parcours l'arborescence de notre corpus en appelant la fonction parcoursarborescence. Si le ficher n'existe pas on passe au suivant et si on tombe sur un répertoire on relance le sous-programme.
• On ne récupère que les fichiers correspondants à la rubrique A LA UNE, puis détection de l'encodage avec la commande file -i.
• On fait en sorte de n'avoir qu'une seule ligne pour chaque fichier à traiter. Pour cela, on supprime les éventuels caractères séparateurs présents en fin de ligne, puis on procède à la concatenation de toutes les lignes (on règle ainsi le problème des différences de forme entre les fichiers!).
• Usage d'une expression régulière pour le filtrage du texte. Cette partie du script (encadrée en rouge) sera modifiée dans les deux autres méthodes utilisées que nous présenterons par la suite.
• Enfin, on lance la procédure de nettoyage du texte (sub nettoietexte).
• Pour visualiser le script en entier cliquez ICI
b) Bibliothèque XML::RSS
• On utilise ici une librairie de perl, efficace et adaptée, pour la récupération des éléments dans un fichier RSS. Pour ce faire il est nécessaire de la déclarer au préalable en début de script. Puis il faudra instancier un nouvel objet RSS...
• ...et le parser!
• Pour visualiser le script en entier cliquez ICI
c) Bibliothèque XML::libXML
• Cette librairie de perl permet d'accéder aux données stockées dans des documents XML. Les documents sont traités comme un arbre de noeuds et les données de ces noeuds sont accessibles en appelant des méthodes sur les objets, eux-mêmes noeuds. On n'oubliera pas, là encore, de déclarer la bibliothèque au début du script.
• Initialisation du module XML::libxml, puis extraction du titre et du contenu à partir des noeuds.
• Pour visualiser le script en entier cliquez ICI
• Présentation des résultats:
Quelque soit la méthode utilisée pour la tâche de filtrage, les fichiers récupérés en sortie sont identiques. On notera, tout de même, que la méthode utilisant une expression régulière est un peu plus longue en terme de temps de traitement que les deux autres.
SORTIE TXT
Pour voir le fichier, cliquez sur l'image.
SORTIE XML
Pour voir le fichier, cliquez sur l'image.