Boîte à outils #2
• Objectifs
Dans cette seconde boîte à outils est présenté un traitement d'etiquetage morphosyntaxique sur les fichiers, txt et xml, récupérés en sortie de la boîte à outils 1. A la suite de ce traitement, chaque token est associé à une catégorie syntaxique ainsi qu'à un lemme. Pour réaliser cette tâche, nous avons utilisé deux types d'étiqueteurs:
• Cordial: logiciel payant qui posséde une interface graphique, mais qui ne s'utilise que sous windows.
• Treetagger : programme d'étiquetage syntaxique qui s'utilise uniquement en ligne de commande ou via un script.
• Etiquetage avec Cordial :
L'interface graphique de ce logiciel rend son utilisation assez simple pour les utilisateurs (du moins pour la tâche que nous avions à réaliser) . Néanmoins, ne supportant que l'ISO-8859-1, nous avons dû procéder à une conversion d'encodage avant de lui soumettre notre fichier en texte brut. Pour ce faire nous avons utilisé "la commande magique" i conv, en ligne de commande, comme suit:
![]()
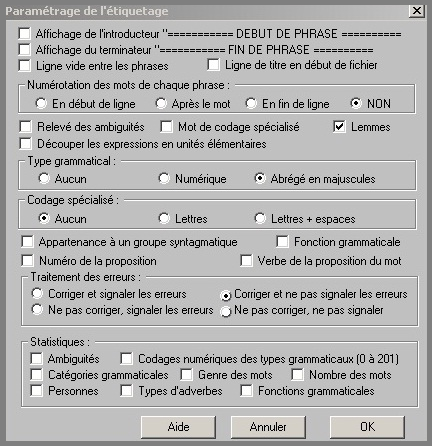
• Une fois la transformation réalisée, nous pouvons paramétrer Cordial pour l'étiquetage:
• Nous lançons l'étiquetage....Et làaaaaaaa......"C'EST LE DRAME"!!!!!!!!!
Cordial n'est pas content et s'arrête en cours de traitement. Malgré le nettoyage du texte effectué dans la première bao, il semblerait que quelques petits caractères récalcitrants aient décidés de perturber le logiciel. Le fichier étant bien trop volumineux pour effectuer une recherche manuelle, nous avons procédé au découpage du fichier en petits morceaux, en utilisant la commande split, en ligne de commande. Nous relancions systématiquement les morceaux de fichiers dans Cordial, jusqu'à que la partie contenant l'erreur soit démasquée!
Une fois les problèmes réglés, nous avons pu relancer Cordial avec succès! Ce dernier fournit en sortie un fichier portant l'extension .cnr.
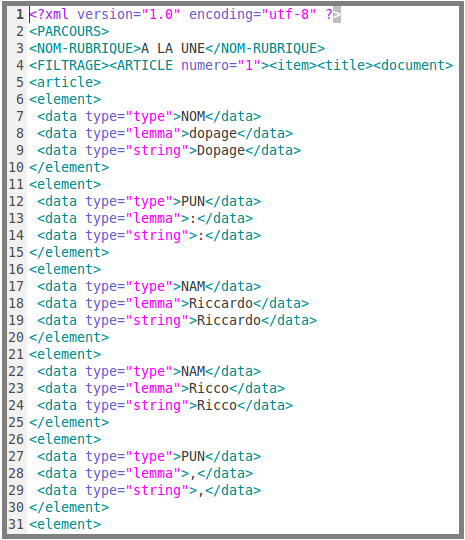
Résultat de l'étiquetage
Pour voir le fichier, cliquez sur l'image
• Etiquetage avec Treetagger :
Pour procéder à un étiquetage avec Treetagger, nous avons ajouté quelques lignes de code dans le script issu de bao 1 (méthode rustique) . Nous avons défini un sous programme qui est lancé uniquement à la fin du programme principal. En effet, cette fonction est appelée juste après le nettoyage du texte. On récuperera à la fin du traitement un fichier au format txt, et un autre étiqueté au format xml.
• On commence par définir notre sous programme :
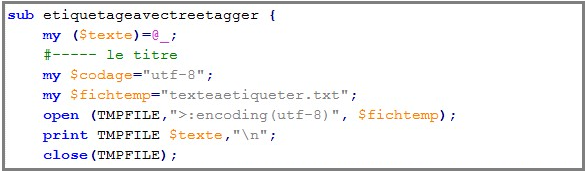
• La commande system nous permet de lancer le script perl de tokenisation,tokenise-fr.pl, sur le fichier temporaire, texteaetiqueter.txt. Le résultat généré par ce programme est ensuite envoyé à treetagger. Afin d'obtenir un étiquetage conforme à nos attentes, nous utilisons les options -lemma et -token pour qu'il affiche le lemme et la forme à côté de la catégorie syntaxique, ainsi que -no-unknow qui permet de remplacer les lemmes qui ne sont pas reconnus par treetagger par leur token. L'option -sgml quant à elle, empéche qu'il n'étiquette les balises xml.

• Lancement du sous programme...Par la suite nous transformerons le fichier txt généré par le programme, en un fichier XML. Pour cela nous aurons recours à un autre script perl.

• Pour visualiser le script en entier cliquez ICI
• Pour visualiser le script en version XML::RSS, cliquez ICI
• Pour visualiser le script en version XML::libXML, cliquez ICI
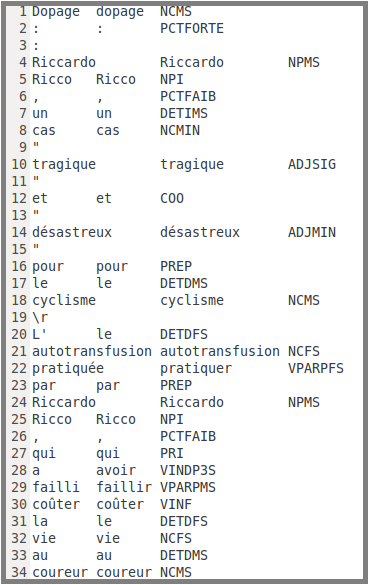
Résultat de l'étiquetage
Le fichier XML étant trop volumineux pour être ouvert avec le navigateur Mozilla, nous vous proposons un aperçu de son rendu lorsqu'on l'ouvre avec un éditeur de texte.