BAO1
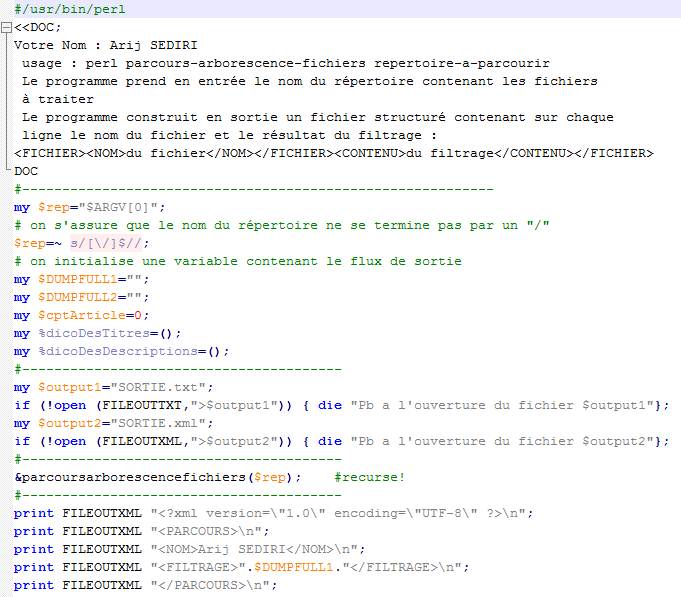
Cette étape consiste à parcourir le corpus "fils rss du journal Le Monde 2011" pour extraire, filtrer et nettoyer les contenus textuels des balises des rubriques RSS proposées par le site LeMonde.fr. J'ai choisi les rubriques CULTURE et EUROPE. Le but de cette étape est de réaliser un traitement permettant d’extraire le titre et le résumé de chaque article, contenus dans les balises < title > et < description > de chaque balise < item > des fils RSS, de remplacer les entités HTML et les caractères spéciaux, de nettoyer les doublons, et de créer plusieurs sorties : le texte brut des fils RSS, une version structurée en XML de ce contenu textuel, des versions destinées à être étiquetées par TreeTagger et Cordial.. J'ai mis en place un script Perl qui réalise :
Suppression des contenus videsLa structure d'un document XML est marquée, comme par des balises ouvrantes et des balises fermantes, par des balises auto fermantes qui se terminent par « /> », avertissant l’utilisateur qu’il n’y a pas de résumé pour le titre du fil en question.
Les doublons d’articles, qui apparaissent parfois d’une journée à l’autre, doivent être supprimés afin d'obtenir des résultats raffinés et non biaisés. Pour cela, j'ai placé chaque titre des résumés récupérés en sortie dans une table de hachage de façon à tester, avant l’écriture en sortie, avec les fonctions unless et exists, si le traitement de l’article a déjà été effectué. Le script formule avec la fonction unless ladite condition, de façon que chaque article soit sélectionné une seule fois, en l’ajoutant au dump final si jamais il n’a pas encore été traité.
Suppression des balises images
Le contenu des balises < description > des fils RSS contient des liens, permettant d'insérer des images dans la page HTML. Ces liens sont supprimés grâce à une simple expression régulière.
Décodage des caractères codés sous la forme d'entités HTML
Le langage HTML utilise un jeu d'entités pour incorporer des caractères spéciaux dans le document. Donc, naturellement, certains caractères dans les fils RSS ont été codés sous la forme d'entités HTML (& # 3 9 ; pour l'apostrophe, & n b s p ; pour l'espace insécable, & a m p ; pour le et commercial..). Il a fallu alors les décoder grâce au module HTML::Entities, qui convertit tous les caractères éligibles en entités HTML et permet en particulier l'affichage des caractères accentués.
Un point a été automatiquement ajouté à la fin des titres et des résumés qui n’en possèdent pas, afin d’éviter des erreurs d’étiquetage que peut engendrer l’absence de ponctuation.