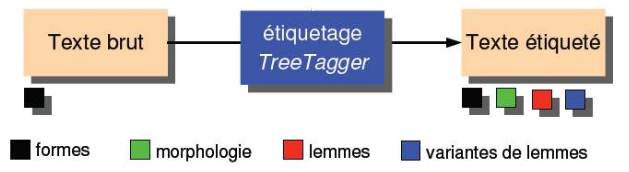
Cordial est un correcteur grammatical et étiqueteur morpho-syntaxique développé par Synapse Développement, un éditeur de logiciels, spécialisé dans la linguistique informatique. Le programme ne peut pas être piloté en ligne de commande, il a fallu utiliser l'interface graphique pour lancer l'étiquetage. Cette technologie permet d'obtenir, à partir d'un texte donné en Ascii Unicode, une sortie texte fournissant pour chacun des mots du texte son lemme et sa catégorie grammaticale. Il a fallu aussi, avant d'importer le fichier texte, convertir ses caractères encodés UTF-8, en ISO-8859-1. Pour ce faire, je me suis basée sur iconv, un utilitaire permettant de modifier l'encodage des fichiers texte.

La taille du fichier texte importé ne doit pas dépasser, au moins, 1500 Ko. Si le fichier est volumineux, le programme se bloque et l'étiquetage s'arrête. Il semble donc que soit la taille du fichier soit les caractères spéciaux qui gênent l'avancement du programme. Il faut, dans ce cas, couper le fichier texte en parties, repérer le caractère qui pose problème, puis le supprimer. Après avoir lancé l'étiquatage, une boîte de dialogue s'affiche et propose de régler les paramètres de l'étiquetage.
Résultats
Les unités documentaires obtenues sont au format CNR. Le programme fournie, pour chaque forme, son lemme et sa catégorie grammaticale.
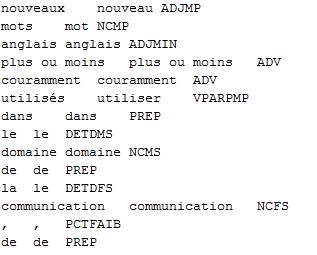
Résultat_Cordial_Culture
Résultat_Cordial_Europe