Pour cette première BaO, nous allons mettre à profit Perl afin de créer un programme qui va effectuer les opérations suivantes:
- faire une première passe sur le corpus afin de détecter et extraire les noms des différentes rubriques
- permettre à l'utilisateur de choisir la rubrique qu'il veut extraire
- faire une deuxième passe sur le corpus pour extraire les fichiers correspondant à la rubrique choisie
- prévoir différents formats de sortie et d'encodage pour la suite du projet
La contrainte est ici que nous allons employer une façon de coder notre programme à la dure, à la mano, sans employer de "Librairies Perl". Concrètement, celà signifie que (à l'exception de l'usage de
Unicode::String), chaque action que le programme va entreprendre devra être intégralement codée sur le script. C'est plus long, mais pour apprendre Perl, il faut en passer par là!
>>>Détection des rubriques
Il aurait été simple de se contenter d'implémenter en dur les différents noms de rubriques. Cependant, notre corpus de test étant un extrait des fils de 2008 et le corpus final l'intégralité des fils de 2011, nous pouvions aisément prévoir que l'organisation du corpus avait évolué, et nous ne nous sommes pas trompés!
Des rubriques présentes en 2008 ont disparu en 2011 et inversement. Des numéros de rubriques ont par conséquent changé et il nous a été très facile de détecter ces changements subtils grâce à cette passe préliminaire.
| numéro de rubrique | nom de rubrique en 2008 | nom de rubrique en 20011 |
|---|
| 3232 | Opinion | Idées |
|---|
| 0 | Fil Municipales et Cantonales 2008 | Politique |
|---|
| 3244 | Environnement Science | Planète |
|---|
| 3404 | Examens 2008 | A la Une |
|---|
De plus, la représentation des noms de rubriques au sein-même des fichiers
.xml a été altérée (à l'exception de la rubrique "A la Une" que nous avons décidé de mettre de côté). Encore une fois, c'est l'implémentation de cette fonction qui nous a permis d'être rapides et efficaces quand il a fallu adapter nos scripts au corpus de 2011.
#on créé la boucle qui permettra de parcourir l'ensemble du corpus (arborescence de fichiers)
my $path = shift(@_);
opendir(DIR, $path) or die "can't open $path: $!\n";
my @files = readdir(DIR);
closedir(DIR);
foreach my $file (@files) {
next if $file =~ /^\.\.?$/;
$file = $path."/".$file;
#si on tombe sur un dossier, on recommence!
if (-d $file) {
&parcoursArboFichRub($file); #recurse!
}
#si c'est un fichier, et que c'est un .xml, on extrait une suite de chiffre de son nom
if (-f $file) {
if ($file=~/\.xml$/) {
$file=~/^.+?-(\d*),.+?\.xml$/;
my $numRub=$1;
#print "$numRub\n";
#puis on détermine si cette suite a déjà été détectée auparavant. Si ce n'est pas le cas, on l'ajoute au dictionnaire
if (!(exists($dicoDesRubs{$numRub}))) {
$dicoDesRubs{$numRub}++;
my $encodage=`file -i $file | cut -d= -f2`;
chomp($encodage);
$ligne="";
#et on ouvre le fichier afin de récupérer le nom du fichier correspondant au numéro de rubrique
open(FILEIN,"<:encoding($encodage)",$file);
while (my $small_ligne=<FILEIN>) {
chomp($ligne);
$ligne.=$small_ligne;
}
$ligne =~ s/>[[:space:]]</></g; #on supprime tous les blancs entre les balises
if (uc($encodage) ne "UTF-8"){utf8($ligne);} #c'est ici que l'on convertit en UTF-8 la concaténation de toutes les "small_lignes"
#voici la RegEx qui permet de cibler précisément le nom de la rubrique
while ($ligne=~/<channel><title>(.+?) - LeMonde.fr<\/title>/g) {
my $nomRub=$1;
#on la nettoie (casse, caractères spéciaux), puis on associe un numéro à un nom dans un dico
$nomRub=&nettoieRub($nomRub);
$index_rub{$numRub}=$nomRub;
#on affiche dans le terminal le numéro suivi du nom de rubrique associé
print "$numRub\t$nomRub\n";
}
}
}
}
}
}
S'entraîner à la lecture de script, c'est bon pour la santé!
Par la suite, on demande à l'utilisateur de choisir un numéro de rubrique, qui va permettre à la deuxième fonction de ne récupérer QUE les fichiers qui nous intéressent:
print "Choisissez une rubrique:","\n";
my $choiceRub = <STDIN>;
chomp $choiceRub;
print $index_rub{$choiceRub},"\n";
>>>Récupération du contenu
La fonction en charge de récupérer le contenu des fichiers choisis est très semblable dans sa construction à celle chargée de récupérer les rubriques. Cependant, elle est adaptée de manière à cibler les informations que l'on souhaite (titre, résumé, date) et à produire en sortie les deux formats que l'on souhaite (
.txt et
.xml).
Morceaux choisis:
L'encodage est toujours un problème délicat. On réalise deux test pour être certains que tout se passe bien.
file est très pratique pour détecter l'UTF-8, mais sur les autres encodages, il est parfois un peu à la rue. C'est pourquoi on teste une deuxième fois et le cas échant, on extrait l'encodage au scalpel, avec une RegEx.
if ($file=~/$choiceRub/) {
#premier test d'encodage avec file
my $encodage=`file -i $file | cut -d= -f2`;
print "ENCODAGE $i : $encodage";
chomp($encodage); #on supprime l 'éventuel retour à la ligne
$i++;
#print $i++,"\n";
#deuxième test, si le premier a échoué, on récupère l'encodage à l'intérieur du fichier
if ($encodage eq "unknown-8bit") {
open(FILE_ENC,$file);
while (my $ligne_enc=<FILE_ENC>) {
if ($ligne_enc=~m/encoding=\"(.+?)\"/) {
$encodage=$1;
print "ENCODAGE_RegExp : $encodage\n"
}
}
close(FILE_ENC);
}
Ici, on voit la RegEx destinée à extraire le contenu de chaque fil. Notez l'emploi des variables
$1,
$2 et
$3.
while ($ligne=~/<item>.+?<title>(.+?)<\/title>.+?<description>(.+?)<\/description>.+?<pubDate>(.+?)<\/pubDate>/g) {
my $titre=$1;
my $desc=$2;
my $date=$3;
$titre=&nettoieText($titre);
$desc=&nettoieText($desc);
$date=&nettoieText($date);
Allez sur la page des downloads (raccourci à gauche), pour récupérer le script, et des exemples de sortie!
Et en effet, celà nous a permis d'adapter facilement la librairie RSS:XML à cette BaO.
L'utilisation de fonctions permet de modifier des scripts relativement long facilement, sans s'y perdre, puisque vous pouvez copier/coller des morceaux de code sans avoir peur d'en oublier un bout au passage. Leur principe n'est pas forcément évident au premier abord, mais une fois bien compris, il va vous éviter des heures de prise de tête.
>>>RSS:XML
Le principe est le même pour cette version alternative de la BaO#1. Cependant, nous allons faire appel à la puissance d'une librairie de Perl (RSS::XML) pour parser les fichiers
.xml que le programme aura sélectionné.
Nous avons donc une première passe pour l'extraction des noms de rubriques, puis une deuxième pour l'extraction des contenus. Seules les linges concernant l'extraction ont drastiquement changé.
Les lignes suivantes permettent d'invoquer les deux librairies Unicode::String et RSS::XML:
#-----------------------------------------------------------
use Unicode::String qw(utf8);
use XML::RSS;
#-----------------------------------------------------------
Et celles-ci (appréciez la concision du code) d'extraire facilement les éléments contenus dans les balises
pubdate,
title et
description.
eval {$rss->parsefile($file); };
if( $@ ) {
$@ =~ s/at \/.*?$//s; # remove module line number
print STDERR "\nERROR in '$rep':\n$@\n";
}
else {
my $date=$rss->{'channel'}->{'pubDate'};
foreach my $item (@{$rss->{'items'}}) {
my $titre=$item->{'title'};
my $desc=$item->{'description'};
}
}
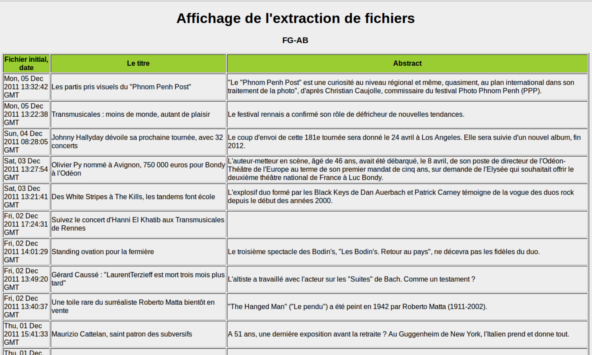
Un exemple de la sortie XML obtenue avec XML:RSS associé à une feuille de style pour plus de lisibilité. Cliquez sur l'image pour l'afficher intégralement. Attention, le fichier est un peu lourd, votre navigateur peut mettre du temps avant de l'afficher.
Encore une fois, rendez-vous sur la page des downloads pour le script et des exemples de sortie!