Cette BaO va aller assez vite. Nous avions effectué un grand nombre de traitements préliminaires sur la BaO#1, ce qui nous a permis d'adapter cette nouvelle BaO sans trop de difficultés.
Petit rappel des traitements de la BaO#1:
- choix des rubriques
- extraction d'un fichier .txt encodé en
ISO-8859-1
- extraction d'un fichier .xml encodé en
UTF-8
Notre objectif est maintenant, d'appliquer TreeTagger sur les sorties .xml que nous avons obtenues précédemment.
TreeTagger est un outil librement accessible, développé par l'université de Stuttgart, disponible à cette adresse:
TreeTagger
Rapidement, nous avons pensé intégrer à la BaO#1 une simple fonction system pour invoquer TreeTagger. Vous pouvez voir les différentes lignes ci-dessous:
sub treeTagger {
system("perl ../TreeTagger/cmd/utf8-tokenize.pl -f $outputTMP | ../TreeTagger/bin/tree-tagger ../TreeTagger/french-utf8.par -lemma -token -no-unknown -sgml > SORTIE_RSS_TreeTagger_BAL_$pathRubName.txt");
system("perl ../TreeTagger/cmd/treetagger2xml-utf8.pl SORTIE_RSS_TreeTagger_BAL_$pathRubName.txt utf-8");
system("mv SORTIE_RSS_TreeTagger_BAL_$pathRubName.txt.xml SORTIE_RSS_TreeTagger_BAL_$pathRubName.xml");
system("rm SORTIE_RSS_TreeTagger_BAL_$pathRubName.txt");
system("rm SORTIE_RSS_TreeTagger_$pathRubName.txt");
}
Encore une fois, coder à l'aide de fonctions se révèle pratique et économique. Il nous a suffit de copier/coller ce morceau de code d'une BaO à l'autre pour les adapter à TreeTagger.
Trop facile me direz-vous? Vous avez raison. Si vous observez attentivement les lignes de codes, vous constaterez que nous appliquons TreeTagger sur une variable nommée
$outputTMP.
En effet, TreeTagger doit prendre en entrée un fichier .txt. Il ne peut appliquer ses traitements directement sur une variable contenant le résultat d'une concaténation, elle-même contenue dans la mémoire de votre machine. Il faut donc passer par un fichier .txt temporaire dans lequel on va extraire le contenu que l'on veut étiqueter.
Les lignes
mv et
rm sont destinées à renommer la sortie obtenue et supprimer les fichiers crées temporairement.
Ci-dessous, déclaration de la variable
$outputTMP, identique dans les deux versions de la BaO#2.
my $outputTMP="SORTIE_RSS_TreeTagger_$pathRubName.txt";
open (TMP,">:encoding($encSortieXML)","SORTIE_RSS_TreeTagger_$pathRubName.txt");
Notez la variable
$pathRubName qui permet de créer des fichiers différents en fonction de la rubrique choisie. Si vous n'ajoutez pas ce genre d'artifices dans les noms de vos fichiers de sortie, à chaque fois que vous relancez votre programme, le fichier précédant sera écrasé.
Ci-dessous, la variable contenant le texte dumpé qui va être redirigée vers le fichier .txt temporaire destiné à TreeTagger.
Notez que ce qui sera dumpé est sous la forme d'une arborescence .xml mais dans un fichier .txt. C'est cette petite astuce qui permettra, finalement d'obtenir le fichier .xml souhaité.
$DUMPTMP.="<article>\n<date>$date</date>\n<title>$titre</title>\n<abstract>$desc</abstract>\n</article>\n";
Le fichier obtenu va d'abord passer par la moulinette de
utf8-tokenize.pl, afin de le... tokeniser, puis ce fichier sera envoyé à TreeTagger en prenant en argument d'entrée
french-utf8.par, un fichier permettant l'étiquetage en langue française de fichiers .txt précédemment tokenisés.
A l'issue de ces traitements successifs, le fichier .txt obtenu (contenant le texte étiqueté) va passer par une dernière moulinette,
treetagger2xml-utf8.pl afin de reconvertir le .txt en .xml. OUF!
A ce titre, le fichier
treetagger2xml-utf8.pl a été légèrement modifié de manière à pouvoir appliquer une feuille de style .xsl directement au fichier .xml obtenu.
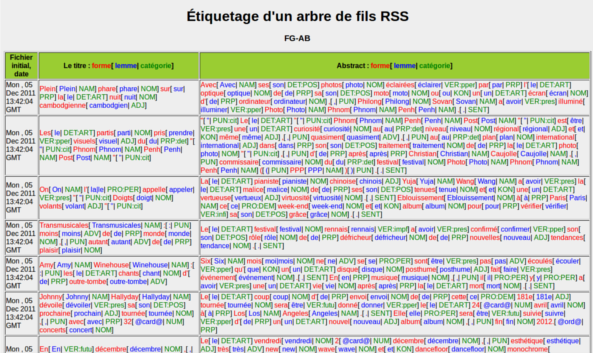
Vous pouvez voir le résultat ci-dessous (cliquez sur l'image pour afficher le fichier dans le navigateur):
Pour les téléchargements, cliquez sur la disquette à gauche.
Le saviez-vous?
Sony a stoppé sa production de disquette au format 3,5" en 2011.