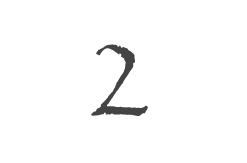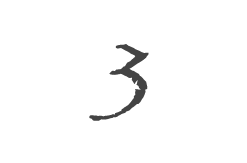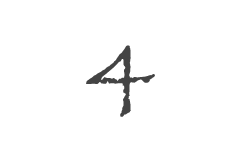Boîte A Outils 3
Cette étape est l'extraction de patrons syntaxiques à partir des sorties de la BAO2. Il y a de nombreuses méthodes pour le faire, et voici plusieurs d'entre elles :
Il y a deux sortes de sortie pour la BAO2 :
- Des sorties TXT, produites par Cordial, avec les 3 colonnes (forme, lemme, catégorie syntaxique)
- Des sorties XML, à partir de Treetagger, avec 3 balises données par mot (catégorie syntaxique, lemme, forme)
Et les patrons syntaxiques visés sont :
- Toutes les séquences nom commun + préposition + nom commun
- Toutes les séquences nom commun + nom commun
- Toutes les séquences nom commun + adjectif
Sur les sorties XML
L'intégration du programme TreeTagger dans la Boîte à Outils 3 permet d'identifier les catégories syntaxiques de chaque mot, et la sortie est transformée en format XML. Pour conditionner le sélectionnement des noeuds, on se sert de XPATH.
XPATH exprime des chemins via la barre oblique et peut aussi contenir des predicats (entre crochets) pour imposer des conditions aux noeuds sélectionnés. Par exemple, pour chercher le premier nom du patron NOM PRP NOM il faut identifier : un élément qui contient dans son premier noeud 'data', la catégorie 'NOM', et qui a pour élément frère suivant un élémént qui contient dans son premier noeud 'data' la catégorie 'PRP', qui a pour élément frère suivant un élément qui contient dans son premier noeud 'data' la catégorie 'NOM'. De cet élément-là, le troisième noeud 'data' est renvoyé - c'est à dire la forme du mot. (ci-dessous)
Séparément, les chemins XPATH sont les suivants pour chaque séquence :
- NOM PRP NOM
- (//element[contains(./data[1],'NOM')][following-sibling::element[1][contains(./data[1],'PRP')]][following-sibling::element[2][contains(./data[1],'NOM')]]/data[3])
|
(//element[contains(./data[1],'PRP')][preceding-sibling::element[1][contains(./data[1],'NOM')]][following-sibling::element[1][contains(./data[1],'NOM')]]/data[3])
|
(//element[contains(./data[1],'NOM')][preceding-sibling::element[1][contains(./data[1],'PRP')]][preceding-sibling::element[2][contains(./data[1],'NOM')]]/data[3])
- NOM NOM
- (//element[contains(./data[1],'NOM')][following-sibling::element[1][contains(./data[1],'NOM')]]/data[3])
|
(//element[contains(./data[1],'NOM')][preceding-sibling::element[1][contains(./data[1],'NOM')]]/data[3])
- NOM ADJ
-
(//element[contains(./data[1],'NOM')][following-sibling::element[1][contains(./data[1],'ADJ')]]/data[3])
|
(//element[contains(./data[1],'ADJ')][preceding-sibling::element[1][contains(./data[1],'NOM')]]/data[3])
Pour faire une requête sur les trois patrons, il fait mettre un tube (|) entre chaque patron. Les chemins peuvent être évalués par un éditeur XML, tel que XMLCopyEditor ou EditX, pour produire une séquence des noeuds qui correspondent à la requête. Mais c'est une séquence de mots individuels comme suit :
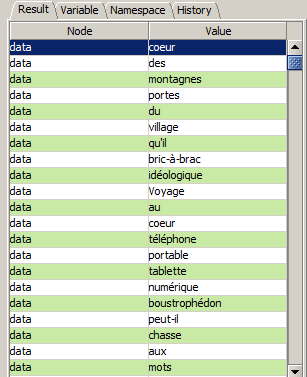 [ Cliquer sur l'image pour l'ouvrir ]
[ Cliquer sur l'image pour l'ouvrir ]
XPATH s'utilise avec d'autres langages pour manipuler les informations et permet d'afficher les patrons ligne par ligne au lieu de chercher les mots individuels de tous les patrons. Je propose deux méthodes qui intègrent XPATH : Un script perl (qui utilise XML::XPATH) et une feuille de styles XSLT :
Méthode Perl + XML::XPATH (proposée par R. Belmouhoub)
La module XML::XPATH fournit un moyen d'intégrer des requêtes XPATH dans un script perl.
Ce script, fourni par R. Belmouhoub prend en entrée une sortie étiquetée (en format XML) et un fichier de patrons.
-
Lecture du fichier de patrons (correspondant à un motif chaque fois.)
-
Pour chaque ligne du fichier (correspondant à un motif), un appel à la procédure &extract_pattern, avec le motif comme argument.
-
La procédure &extract_pattern prend le motif actuel et produit une sortie pour ce motif. Il produit donc autant de fichiers de sortie qu'il y a de motifs dans le fichier de motifs. Il comporte deux étapes principales : la construction du chemin XPATH correspondant au motif et l'extraction de ces noeuds via un objet XML::PATH.
- La construction du chemin se fait via la procédure &construit_XPath qui prend comme argument la ligne du patron, qu'elle transforme en liste pour pouvoir la parcourir. Le chemin est initialisé pour le premier élément et ensuite des prédicats sont ajoutés un par un. Ces prédicats imposent une condition sur les éléments qui doivent suivre ce premier. Ensuite, il faut fermer les crochets de ces prédicats, ce qui correspond au crochet fermant multiplié par le nombre de catégories dans le motif moins 2.
#===== Construction du chemin XPath =====
# Ce chemin correspond au premier noeud "element" de l'arbre XML qui répond au motif cherché
my $search_path="//element[contains(data[\@type=\"type\"],\"$tokens[0]\")]";
# Ajouter les prédicats qui correspondent au motif (de la 2ème catégorie à l'avant-dernière)
my $i=1;
while ($i < $#tokens){
$search_path.="[following-sibling::element[1][contains(data[\@type=\"type\"],\"$tokens[$i]\")]";
$i++;
}
# Suffix du chemin
my $search_path_suffix="]";
$search_path_suffix=$search_path_suffix x $i;
# le chemin XPath final (avec le dernier élément ajouté)
$search_path.="[following-sibling::element[1][contains(data[\@type=\"type\"],\"".$tokens[$#tokens]."\")]".$search_path_suffix;
- Ce chemin est récupéré dans la procédure &extract_pattern. L'exploration de l'arborescence XML nécessite la création d'un nouvel objet XML::XPATH et il est possible de récupérer les noeuds qui correspondent au chemin créé en faisant une requête sur cet objet via 'findnodes', qui renvoient tous les noeuds concernés. Une fois ce premier noeud trouvé, il faut chercher les noeuds suivants, qui se fait par une boucle sur ces éléments suivants et 'find' qui récupère les noeuds spécifés dans le chemin relatif $following_elmt. Chaque fois qu'un noeud est trouvé, que cela soit le premier noeud ou les noeuds suivants, il est écrit directement dans le fichier, suivi d'un espace. A la fin de chaque séquence, un retour à la ligne permet d'afficher une seule séquence par ligne.
# création de l'objet XML::XPath pour explorer le fichier de sortie tree-tagger XML
my $xp = XML::XPath->new( filename => $tag_file ) or die "big trouble";
# Parcours des noeuds du ficher XML correspondant au motif, au moyen de la méthode findnodes
# qui prend pour argument le chemin XPath construit précédement
foreach my $noeud ( $xp->findnodes($search_path)) {
# chemin XPATH pour identifier la valeur 'string' (i.e. la forme du mot)
my $form_xpath="";
$form_xpath="./data[\@type=\"string\"]";
my $following=0; # compteur pour la boucle d'éxtraction des formes suivantes
# Recherche du noeud data contenant la forme correspondant au premier élément du motif
# au moyen de la fonction "find" qui prend pour arguments:
# 1. le chemin XPath relatif du noeud "data"
# 2. le noeud en cours de traitement dans cette boucle foreach
# la fonction "find" retourne par défaut une liste de noeuds, dans notre cas cette liste
# ne contient qu'un seul élément que nous récupérons avec la fonction "get_node"
# enfin nous en imprimons le contenu textuel au moyen de la méthode string_value
print MATCHFILE $xp->find($form_xpath,$noeud)->get_node(1)->string_value," ";
# Boucle d'éxtraction des formes correspondants aux éléments suivants du motif
while ( $following < $#tokens) {
$following++;
# Construction du chemin XPath du noeud "data" contenant
# la forme correspondant à l'élément suivant du motif
# Notez bien l'utilisation du compteur $folowing tant dans la condition de la boucle ci-dessus
# que dans la construction du chemin relatif XPath
my $following_elmt="following-sibling::element[".$following."]";
$form_xpath=$following_elmt."/data[\@type=\"string\"]";
# Impression du contenu textuel du noeud data contenant la forme correspondant à l'élément suivant du motif
print MATCHFILE $xp->find($form_xpath,$noeud)->get_node(1)->string_value," ";
}
print MATCHFILE "\n";
}
Le script complet se trouve ci-dessous :
#/usr/bin/perl
<<DOC;
Nom : Rachid Belmouhoub
Avril 2012
usage : perl bao3_rb_new.pl fichier_tag fichier_motif
DOC
use strict;
use utf8;
use XML::XPath;
# Définition globale des encodages d'entrée et de sortie du script
binmode STDIN, ':encoding(utf8)';
binmode STDOUT, ':encoding(utf8)';
# On vérifie le nombre d'arguments de l'appel au script ($0 : le nom du script)
if($#ARGV!=1){print "usage : perl $0 fichier_tag fichier_motif";exit;}
# Enregistrement des arguments de la ligne de commande dans les variables idoines
my $tag_file= shift @ARGV;
my $patterns_file = shift @ARGV;
# Ouverture du fichier de motifs
open(PATTERNSFILE, $patterns_file) or die "can't open $patterns_file: $!\n";
# lecture du fichier contenant les motifs, un motif par ligne (par exemple : NOM ADJ)
while (my $ligne = <PATTERNSFILE>){
# Appel à la procédure d'extraction des motifs
&extract_pattern($ligne);
}
# Fermeture du fichier de motifs
close(PATTERNSFILE);
# routine de construction des chemins XPath
sub construit_XPath{
my $local_ligne=shift @_; # récupérer la ligne du motif recherché
my $search_path=""; # initialiser le chemin XPath
chomp($local_ligne); # supprimer avec la fonction chomp un éventuel retour à la ligne
$local_ligne=~ s/\r$//; # éliminer un éventuel retour chariot hérité de windows
# Construction d'un tableau dont chaque élément a pour valeur un élément du motif recherché
my @tokens=split(/ /,$local_ligne);
#===== Construction du chemin XPath =====
# Ce chemin correspond au premier noeud "element" de l'arbre XML qui répond au motif cherché
my $search_path="//element[contains(data[\@type=\"type\"],\"$tokens[0]\")]";
# Ajouter les prédicats qui correspondent au motif (de la 2ème catégorie à l'avant-dernière)
my $i=1;
while ($i < $#tokens){
$search_path.="[following-sibling::element[1][contains(data[\@type=\"type\"],\"$tokens[$i]\")]";
$i++;
}
# Suffix du chemin
my $search_path_suffix="]";
$search_path_suffix=$search_path_suffix x $i;
# le chemin XPath final (avec le dernier élément ajouté)
$search_path.="[following-sibling::element[1][contains(data[\@type=\"type\"],\"".$tokens[$#tokens]."\")]".$search_path_suffix;
# on renvoie à la procédure appelante le chemin XPath et le tableau des éléments du motif
return ($search_path,@tokens);
}
# routine d'extraction du motif
sub extract_pattern{
my $ext_pat_ligne= shift @_; # récupérer la ligne du motif recherché
# Appel de la fonction construit_XPath pour le motif lu à la ligne courrante du fichier de motif
my ($search_path,@tokens) = &construit_XPath($ext_pat_ligne);
my $match_file = "res_extract-".join('_', @tokens).".txt"; # définition du nom du fichier
open(MATCHFILE,">:encoding(UTF-8)", "$match_file") or die "can't open $match_file: $!\n";
# création de l'objet XML::XPath pour explorer le fichier de sortie tree-tagger XML
my $xp = XML::XPath->new( filename => $tag_file ) or die "big trouble";
# Parcours des noeuds du ficher XML correspondant au motif, au moyen de la méthode findnodes
# qui prend pour argument le chemin XPath construit précédement
foreach my $noeud ( $xp->findnodes($search_path)) {
# chemin XPATH pour identifier la valeur 'string' (i.e. la forme du mot)
my $form_xpath="";
$form_xpath="./data[\@type=\"string\"]";
my $following=0; # compteur pour la boucle d'éxtraction des formes suivantes
# Recherche du noeud data contenant la forme correspondant au premier élément du motif
# au moyen de la fonction "find" qui prend pour arguments:
# 1. le chemin XPath relatif du noeud "data"
# 2. le noeud en cours de traitement dans cette boucle foreach
# la fonction "find" retourne par défaut une liste de noeuds, dans notre cas cette liste
# ne contient qu'un seul élément que nous récupérons avec la fonction "get_node"
# enfin nous en imprimons le contenu textuel au moyen de la méthode string_value
print MATCHFILE $xp->find($form_xpath,$noeud)->get_node(1)->string_value," ";
# Boucle d'éxtraction des formes correspondants aux éléments suivants du motif
while ( $following < $#tokens) {
$following++;
# Construction du chemin XPath du noeud "data" contenant
# la forme correspondant à l'élément suivant du motif
# Notez bien l'utilisation du compteur $folowing tant dans la condition de la boucle ci-dessus
# que dans la construction du chemin relatif XPath
my $following_elmt="following-sibling::element[".$following."]";
$form_xpath=$following_elmt."/data[\@type=\"string\"]";
# Impression du contenu textuel du noeud data contenant la forme correspondant à l'élément suivant du motif
print MATCHFILE $xp->find($form_xpath,$noeud)->get_node(1)->string_value," ";
}
print MATCHFILE "\n";
}
# Fermeture du fichiers de motifs
close(MATCHFILE);
}
J'ai modifié ce script en ajoutant une boucle pour pouvoir traiter tous les fichiers d'un répertoire. C'est ce script qui se trouve dans Téléchargements, mais attention car le temps de traitement est extrêmement long !
Feuille de styles XSLT
Les sorties étant au format XML, un autre moyen de visualiser les informations est avec une feuille de styles XSLT pour transformer le document. La feuille de styles montrée ici transforme la sortie XML en format HTML, avec trois tableaux, chaque tableau correspondant à un des trois patrons syntaxiques décrits en haut de page.
Les trois tableaux se réalisent indépendamment les uns des autres, avec un appel à <xsl:apply-templates... à l'intérieur de chaque tableau. Chaque fois, c'est le chemin jusqu'à 'element' qui est décrit dans le 'select' de <xsl:apply-templates.... Mais les prédicats sur l'élément 'element' changent selon le patron syntaxique souhaité. Par exemple, le chemin exprimé pour appliquer les styles au patron NOM NOM serait comme suit :
<table>
<tr><th><font color="#1732bc">NOM</font><font color="#1732bc"> NOM</font></th></tr>
<xsl:apply-templates select="./PARCOURS/*/file/items/item/*/document/article/element[contains(data[1], 'NOM')][following-sibling::element[1][contains(data[1], 'NOM')]]"/>
</table>
Pour spécifier des styles différents pour chaque patron, il faut aussi répéter ce chemin dans le <template match... (puisqu'il en existe trois pour l'élément 'element' et il faut les distinguer). Par exemple, voici les styles spécifiques appliqués pour l'élément qui est le premier élément dans le motif NOM NOM :
<xsl:template match="element[contains(data[1], 'NOM')][following-sibling::element[1][contains(data[1], 'NOM')]]">
<tr>
<td>
<font color="#1732bc"><xsl:value-of select="./data[3]"/></font><xsl:text> </xsl:text><font color="#1732bc"><xsl:value-of select="following-sibling::element[1]/data[3]"/></font>
</td>
</tr>
</xsl:template>
S'il y a un match pour l'élément en question (c'est un nom, suivi d'un nom), cet élément plus l'élément suivant (qui est forcément un nom) sont affichés, avec des styles css différents.
La feuille de styles complète se trouve ci-dessous :
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="2.0">
<xsl:output method="html"/>
<xsl:template match="/">
<xsl:variable name="rubrique" select="local-name(./PARCOURS/*[preceding-sibling::NOM])"/>
<html>
<head>
<meta charset="utf-8"/>
<title>BAO 3 - <xsl:value-of select="$rubrique"/></title>
<link rel="icon" type="image/ico" href="../Images/bao.ico"/>
<link rel="stylesheet" type="text/css" href="3_extractpatterns.css"/>
</head>
<div id="header"><h1>Extraction de patrons de la rubrique <xsl:value-of select="$rubrique"/></h1></div>
<body>
<table>
<tr>
<th>
<font color="#1732bc">NOM</font><font color="#891f1f"> PRP </font> <font color="#1732bc">NOM</font>
</th>
</tr>
<xsl:apply-templates select="./PARCOURS/*/file/items/item/*/document/article/element[contains(data[1], 'NOM')][following-sibling::element[1][contains(data[1], 'PRP')]][following-sibling::element[2][contains(data[1], 'NOM')]]"/>
</table>
<table>
<tr>
<th>
<font color="#1732bc">NOM</font><font color="#0e6022"> ADJ</font>
</th>
</tr>
<xsl:apply-templates select="./PARCOURS/*/file/items/item/*/document/article/element[contains(data[1], 'NOM')][following-sibling::element[1][contains(data[1], 'ADJ')]]"/>
</table>
<table>
<tr>
<th>
<font color="#1732bc">NOM</font><font color="#1732bc"> NOM</font>
</th>
</tr>
<xsl:apply-templates select="./PARCOURS/*/file/items/item/*/document/article/element[contains(data[1], 'NOM')][following-sibling::element[1][contains(data[1], 'NOM')]]"/>
</table>
</body>
</html>
</xsl:template>
<xsl:template match="element[contains(data[1], 'NOM')][following-sibling::element[1][contains(data[1], 'PRP')]][following-sibling::element[2][contains(data[1], 'NOM')]]">
<tr>
<td>
<font color="#1732bc"><xsl:value-of select="./data[3]"/></font><xsl:text> </xsl:text><font color="#891f1f"><xsl:value-of select="following-sibling::element[1]/data[3]"/></font><xsl:text> </xsl:text><font color="#1732bc"><xsl:value-of select="following-sibling::element[2]/data[3]"/></font><xsl:text> </xsl:text>
</td>
</tr>
</xsl:template>
<xsl:template match="element[contains(data[1], 'NOM')][following-sibling::element[1][contains(data[1], 'ADJ')]]">
<tr>
<td>
<font color="#1732bc"><xsl:value-of select="./data[3]"/></font><xsl:text> </xsl:text><font color="#0e6022"><xsl:value-of select="following-sibling::element[1]/data[3]"/></font>
</td>
</tr>
</xsl:template>
<xsl:template match="element[contains(data[1], 'NOM')][following-sibling::element[1][contains(data[1], 'NOM')]]">
<tr>
<td>
<font color="#1732bc"><xsl:value-of select="./data[3]"/></font><xsl:text> </xsl:text><font color="#1732bc"><xsl:value-of select="following-sibling::element[1]/data[3]"/></font>
</td>
</tr>
</xsl:template>
</xsl:stylesheet>
Et en-dessous quelques exemples de sorties :
RENDEZVOUS
| NOM PRP NOM |
| coeur des montagnes
|
| portes du village
|
| Voyage au coeur
|
| chasse aux mots
|
| fourneaux en atelier
|
| maison de ventes
|
| vente à l'occasion
|
| tarifs des vétérinaires
|
| cuisine pour bouts
|
| bouts de chou
|
| NOM ADJ |
| village qu'il |
| bric-à-brac idéologique |
| téléphone portable |
| tablette numérique |
| boustrophédon peut-il |
| mots rares |
| accords trompeurs |
| chef haut |
| cuisinier breton |
| recettes magiques |
| NOM NOM |
| atelier d'art |
| Plan vélo |
| catégorie poids |
| version auto |
| tables soupes |
| western spaghetti |
| goût grâce |
| vocable pastinaca |
| atelier diktée |
| objet d'études |
[ Cliquez sur le tableau pour le visualiser ]
VOYAGE
| NOM PRP NOM |
| monde a part
|
| vernissage des emblèmes
|
| vie du quartier
|
| réputation du photographe
|
| paparazzi des âmes
|
| bête de trait
|
| toundra à l'espace
|
| terrain de jeux
|
| l'image du style
|
| villes à l'architecture
|
| NOM ADJ |
| l'écrivain turc |
| l'heure new-yorkaise |
| l'ancien conservatoire |
| gastronomie belge |
| symboles culinaires |
| génération d'hôteliers |
| mode qu'elle |
| musées français |
| âmes perdues |
| Bibendum céleste |
| NOM NOM |
| Soirée music-hall |
| souvenirs d'enfance |
| l'expérience d'une |
| l'hippopotame pygmée |
| pandas géants |
| Scène rock |
| Scène rock |
| pays suite |
| dates parisiennes |
| Histoire d'eaux |
[ Cliquez sur le tableau pour le visualiser ]
Sur les sorties TXT
Méthode Pure Perl - proposée par Jean-Michel Daube
Ce programme écrit entièrement en Perl utilise des listes pour extraire les patrons voulus. Après quelques modifications, il prend en entrée le dossier de fichiers à traiter (les fichiers .cnr produit par Cordial), l'emplacement du dossier de sortie et un fichier de patrons syntaxiques. Le script peut alors traiter toutes les rubriques selon trois patrons. Contrairement à la méthode précédente, je choisis de produire un unique fichier de sortie pour chaque rubrique (comportant tous les motifs spécifiés dans le fichier de patrons syntaxiques). Ceci pourrait être intéressant pour la BAO 4 où ces patrons seront visualisés - un ensemble de patrons décrits par un même graphe.
NC[A-Z]+ PREP NC[A-Z]+
NC[A-Z]+ NC[A-Z]+
NC[A-Z]+ ADJ[A-Z]+
On commence par parcourir le dossier en entrée et pour chaque fichier .cnr effectuer le traitement.
Le programme lit le fichier ligne par ligne (chaque ligne contient les 3 informations (forme, lemme et catégorie syntaxique). En utilisant l'étiquette "PCTFORTE" comme indicateur de la fin d'une phrase, on traite le fichier phrase par phrase, en stockant dans trois tableaux différents (@tokens, @lemmes et @catégories) les informations pour chaque mot de la phrase. Quand on rencontre une "PCTFORTE", on effectue le traitement sur les trois listes, et ensuite on les reinitialise pour traiter la phrase suivante.
Le traitement des trois listes se fait dans une sous-fonction &traiter_liste_categories. La fonction harmonise le format des catégories syntaxiques extraites en les mettant sur une seule ligne, séparées par un espace (i.e. le même format que le patron dans le fichier de patrons). Après il suffit de tester si pour chaque patron, le patron (une chaîne de caractères) est compris dans la liste de catégories (maintenant une chaîne de caractères aussi). S'il l'est, les lemmes corespondants sont écrits dans le fichier de sortie.
Le script se trouve ci-dessous :
#!/usr/bin/perl
<<DOC;
Votre Nom : Bawden, Rachel
MARS 2013
usage : perl BAO3_rustique.pl repertoire_en_entree repertoire en sortie fichier_de_patrons
Le programme prend en entrée le nom du répertoire contenant les fichiers
à traiter (fichiers textes étiquetés par Coridal) et un fichier txt contenant les patrons syntaxiques à extraire.
Le programme produit en sortie une liste contenant les patrons pour chaque fichier du dossier fourni.
DOC
#====================================>
# Initialisations et Déclarations
#====================================>
my $res=$ARGV[0];
my $dossier_de_sortie=$ARGV[1];
$res=~s/\/$//;
$dossier_de_sortie=~s/\/$//;
my $patron=$ARGV[2];
my @tokens=();
my @lemmes=();
my @categories=();
opendir(DIR, $res) or die "Erreur d'ouverture de repertoire: $!\n";
my @files_a_traiter = readdir(DIR);
print "FOUND : @files_a_traiter\n";
closedir(DIR);
foreach my $file(@files_a_traiter) # pour chaque fichier dans le dossier
{
if ($file=~/(.+?)\.cnr$/)
{
my $filetxt=$1.".txt";
print "Fichier : $file\n";
open(FILE_IN, "<:encoding(iso-8859-1)", "$res/$file");
while(my $line=<FILE_IN>)
{
if ($line!~/PCTFORTE/) # traitement jusqu'à une ponctuation forte
{
chomp($line);
$line=~s/\r//;
my @row=();
@row=split("\t", $line); # liste (lemme, forme, catégorie) pour chaque mot
push(@tokens, $row[0]);
push(@lemmes, $row[1]);
push(@categories, $row[2]);
}
else #quand on arrive à une ponctuation forte
{
#------ Traitement sur les tokens ------>
&traiter_liste_categories($filetxt);
#---- réinitialisation des tableaux ---->
@tokens=();
@lemmes=();
@categories=();
}
}
}
}
close(FILE_IN);
#====================================>
# SUB : Traitement des catégories
#====================================>
sub traiter_liste_categories{
$filetxt=shift;
open(FILE_PATRONS, "<:encoding(iso-8859-1)", $patron);
my $chaine_de_cats=join(" ",@categories); # faire un scalaire du tableau de catégories afin de les comparer
if (! -e "$dossier_de_sortie/$filetxt") #si la première fois qu'on rencontre cette rubrique
{
if (!open (FILEOUT,">:encoding(iso-8859-1)","$dossier_de_sortie/$filetxt"))
{
die "Probleme a l'ouverture du fichier : $dossier_de_sortie/$filetxt $!\n";
}
}
else
{
if (!open (FILEOUT,">>:encoding(iso-8859-1)","$dossier_de_sortie/$filetxt"))
{
die "Probleme a l'ouverture du fichier : $dossier_de_sortie/$filetxt $!\n";
}
}
while(my $line_patron=<FILE_PATRONS>) # pour chaque patron syntaxique
{
chomp($line_patron);
$line_patron=~s/\r//g;
my $compteur=0;
while ($chaine_de_cats=~/$line_patron/g)
{
$compteur++;
my $avant=$`;
my $apres=$';
my $nombre_de_separateurs_dans_patron=0;
my $nombre_de_separateurs_dans_possible_match=0;
while ($avant=~/ /g) # compter le nombre de séparateurs dans la liste de catégories à traiter
{
$nombre_de_separateurs_dans_possible_match++;
}
while ($line_patron=~/ /g) # compter le nombre de séparateurs dans le patron
{
$nombre_de_separateurs_dans_patron++;
}
#----------- Chercher les correspondances ---------->
for (my $i=$nombre_de_separateurs_dans_possible_match; $i<=$nombre_de_separateurs_dans_possible_match+$nombre_de_separateurs_dans_patron; $i+=1)
{
print FILEOUT $tokens[$i], " ";
}
print FILEOUT "\n";
}
}
close(FILE_PATRONS);
close(FILEOUT);
}
Méthode Alternative Pure Perl
Une solution un peu plus courte, utilise des expressions régulières et une seule liste. Le programme suit la même méthode que la précédente, mais au lieu de séparer les trois colonnes en trois listes séparées, chaque mot (avec toutes ses informations) est stocké dans une seule liste @phrase :
[[En en PREP],
[battant battre VPARPRES],
[Toulouse toulouse NCSIG],
[dimanche dimanche NCMS],
[à a PREP],
[domicile domicile NCMS],
[grâce à grâce à PREP],
[une un DETIFS],
[nouveau nouveau ADJMS],[
[festival festival NCMS]...]
La fonction &traiter_liste_categories fait cette conversion, et parcourt la liste de patrons pour les tester. Pour chaque patron, la fonction parcourt la liste de mots de la phrase (où le compteur et le nombre de mots dans la liste).
for (my $i=0; $i<$compteur; $i+=1)
Une première condition vérifie si le patron est possible à partir du mot actuel (s'il y a assez de mots entre le mot actuel et la fin de la phrase) :
if ($i+$patron_size<=$compteur)
Ensuite, une boucle permet de parcourir la liste de mots à partir du mot actuel pour autant de mots qu'il y a de catégories dans le patron et tandis que les mots correspondent au patron :
for (my $j=0; ($j<$patron_size) && ($found!=0); $j+=1)
Chaque mot est comparé à l'élément correspondant dans le patron à l'aide des expressions régulières (N.B. la catégorie syntaxique est située dans la troisième colonne) :
if ($phrase[$k]=~/(.+?)\t(.+?)\t$patron[$j]/)
Si l'élément est trouvé, le compteur '$found' est augmenté par 1. La boucle qui parcourt la phrase continue seulement quand ce compteur n'est pas à zéro (la valeur étant fixé à zéro pour la premère mot). Ensuite, si la valeur de $found est égale à la taille du motif, le résultat est imprimé dans le fichier de sortie.
Le script complet se trouve ci-dessous :
#!/usr/bin/perl
use strict;
<<DOC;
Votre Nom : Bawden, Rachel
MARS 2013
usage : perl BAO3Rachel2.pl repertoire_en_entree fichier_de_patrons
Le programme prend en entrée le nom du répertoire contenant les fichiers
à traiter (fichiers textes étiquetés par Coridal) et un fichier txt contenant les patrons syntaxiques à extraire.
Le programme produit en sortie...
DOC
#====================================>
# Initialisations et Déclarations
#====================================>
my @phrase=();
my $compteur=0;
my $res=$ARGV[0];
my $dossier_de_sortie=$ARGV[1];
my $patron=$ARGV[2];
$dossier_de_sortie=~s/\/$//;
$res=~s/\/$//;
opendir(DIR, $res) or die "Erreur d'ouverture de repertoire: $!\n";
my @files_a_traiter = readdir(DIR);
closedir(DIR);
foreach my $file(@files_a_traiter) # pour chaque fichier dans le dossier
{
if ($file=~/(.+?)\.cnr$/)
{
my $filetxt=$1.".txt";
print "$filetxt";
open(FILE_IN, "<:encoding(iso-8859-1)", "$res/$file");
if (!open (FILEOUT,">:encoding(iso-8859-1)","$dossier_de_sortie/$filetxt"))
{
die "Probleme a l'ouverture du fichier : $dossier_de_sortie/$filetxt $!\n";
}
close(FILEOUT);
while(my $line=<FILE_IN>)
{
if ($line!~/PCTFORTE/) # traitement jusqu'à une ponctuation forte
{
chomp($line);
$line=~s/\r//;
push(@phrase, $line);
$compteur++;
}
else #quand on arrive à une ponctuation forte
{
#------ Traitement sur les tokens ------>
&traiter_liste_categories($filetxt);
#---- réinitialisation des tableaux ---->
@phrase=();
$compteur=0;
}
}
close(FILE_IN);
}
}
#====================================>
# SUB : Traitement des catégories
#====================================>
sub traiter_liste_categories
{
my $file_a_creer=shift;
open(FILE_PATRONS, "<:encoding(iso-8859-1)", $patron);
while(my $line_patron=<FILE_PATRONS>) # pour chaque patron syntaxique
{
chomp($line_patron);
$line_patron=~s/\r//g;
my @patron=split(" ",$line_patron);
#print @patron;
my $patron_size = $#patron+1;
#print "\nLa longueur :",$compteur,"\n";
#print "\nPatron_size : ",$patron_size,"\n";
#print @phrase;
my $found=1;
my $result="";
for (my $i=0; $i<$compteur; $i+=1)
{
#print "$i\n";
if ($i+$patron_size<=$compteur)
{
my $k=$i;
$found=-1;
for (my $j=0; ($j<$patron_size) && ($found!=0); $j+=1)
{
#print "looking for : $patron[$j]";
# initialiser le compteur found la première fois
if ($found==-1)
{
$found=0;
}
if ($phrase[$k]=~/(.+?)\t(.+?)\t$patron[$j]/)
{
#print "\tfound with : $phrase[$k]\n";
#print "result = $1";
$result=$result." ".$1;
$found++;
$k++;
#print "\nphrase k = $phrase[$k]\tpatron j = $patron[$j]\n";
if ($found==$patron_size)
{
#print "$result\n";
if (!open (FILEOUT,">>:encoding(iso-8859-1)","$dossier_de_sortie/$file_a_creer"))
{
die "Probleme a l'ouverture du fichier $dossier_de_sortie/$file_a_creer : $!\n";
}
print FILEOUT "$result\n";
close(FILEOUT);
}
}
else
{
#print"\nrestarting\n";
$result="";
$found=-1;
}
}
}
}
}
close(FILE_PATRONS);
}
Extension (Entrée Utilisateur)
Pour faciliter la tâche de choisir des patrons ou des rubriques (pour l'instant ces paramètres sont fournis à l'exécution), voici un peu de script qui peut s'ajouter aux deux scripts précédents (sur la sortie de Cordial). Il pourrait être facilement écrit aussi pour les sorties de treetagger mais la liste de catégories syntaxiques ne serait pas la même.
Pour choisir les patrons, le script utilise Perl::readlines - !!Sous Windows*!!, qui permet de fournir une liste de suggestions sur la base de ce que tape l'utilisateur.
*Le script marche aussi sous Ubuntu sauf que la fonction tab ne marche pas...
En partan sur le même principe que les autres scripts, les patrons se trouvent dans un fichier de patrons. Ce script permet à l'utilisateur de créer ce fichier via le terminal en ajoutant autant de patrons qu'il/elle veut et autant de catégories par patron (pourvu qu'elles soient dans la liste (qui n'est pas la liste complète pour le côté pratique).
#============== SUB : choisir rubrique ================>
sub choisirrubrique{
print "\nMaintenant vous pouvez choisir la rubrique dans laquelle chercher les patrons";
print "\nVous avez le choix suivant : ";
print "ALAUNE, CINEMA, CULTURE, ECONOMIE, EUROPE, IDEES, INTERNATIONAL, LIVRES, MEDIAS, PLANETE, POLITIQUE, SOCIETE, SPORT, TECHNOLOGIES, VOUS, VOYAGE : ";
chomp(my $rubrique=<STDIN>);
return $rubrique;
}
#============== SUB : définir les patrons ==============>
sub inputpatrons{
my $end=0;
my $patrons="";
my @list=();
my $term = Term::ReadLine->new('Catégories Syntaxiques');
while ($end!=1){
print">>> Voulez-vous creer un nouveau patron ? y/n : ";
my $reponse=<STDIN>;
my $i=1;
if ($reponse eq "y\n"){
print "Ecrivez les categories une apres l'autre. Quand vous aurez fini, tapez FIN.\n";
my $content = '';
my $attribs = $term->Attribs;
$attribs->{completion_function} = sub {
my ($text, $line, $start) = @_;
return grep { /^$text/i } (
"ADJ[A-Z]+","DET[A-Z]+","NP[A-Z]+","NC[A-Z]+","INT","VIND[A-Z1-3]+", "VCONP[A-Z1-3]+", "VIMP[A-Z1-3]+", "VINF[A-Z1-3]+", "VSUB[A-Z1-3]+", "VPAR[A-Z1-3]+", "PP", "PPER[A-Z1-3]*", "SUB", "PREP","ADJ[A-Z]+","ADV","PDP","COO");
};
my $OUT = $term->OUT || \*STDOUT;
while ( defined (my $text = $term->readline("Tapez la categorie syntaxique numero $i : ")) ) {
last unless $text ne "FIN"; # fin de la boucle quand on tape FIN
$content .= "$text\n"; # l'entrée s"ajoute au contenu du patron
$i++;
}
print $content;
@list=split("\n",$content); # séparer sur le saut de ligne
my $content=join(" ", @list); # join sur l'espace
my $goodorbad=&check($content); # vérifier si les catégories sont dans la liste ou non
# si tout va bien
if ($goodorbad eq "good"){
print "Votre patron : $content\n\n";
print "Souhaitez-vous garder ce patron ? y/n : ";
my $garder=<STDIN>;
if ($garder eq "y\n"){
$patrons.="$content\n";
print "Vos patrons :\n$patrons\n";
}
}
}
# Voulez-vous ajouter un autre ?
elsif($reponse ne "n\n"){
print "Je n'ai pas compris votre reponse.\n"
}
# fin des patrons
else{
$end=1;
}
}
my $fichierpatrons=ecrirepatrons($patrons);
return $fichierpatrons;
}
#============= SUB : Ecrire dans un fichier patrons.txt ============
sub ecrirepatrons{
my $patrons=shift;
my $fichieroriginal="patrons";
my $fichier=$fichieroriginal;
my $new=0;
my $k=1;
while ($new==0){
if (-f "$fichier.txt"){
$fichier="$fichieroriginal($k)";
$k+=1;
}
else{
$new=1;
}
}
open PATRONS,">:encoding(UTF-8)", "$fichier.txt" or die "Problème a l'ouverture du fichier - $!";
print PATRONS $patrons;
close PATRONS;
return $fichier.".txt";
}
Ensuite, l'utilisateur rentre le nom d'une rubrique. Cette fois-ci la liste est plus petite donc la liste de suggestions est simplement affichée à l'écran.
#============== SUB : choisir rubrique ================>
sub choisirrubrique{
print "\nMaintenant vous pouvez choisir la rubrique dans laquelle chercher les patrons";
my $found=0;
while ($found==0){
print "\nVous avez le choix suivant : ";
my @choix=qw(ALAUNE CINEMA CULTURE ECONOMIE EUROPE IDEES INTERNATIONAL LIVRES MEDIAS PLANETE POLITIQUE SOCIETE SPORT TECHNOLOGIES VOUS VOYAGE);
print "@choix : ";
chomp(my $rubrique=<STDIN>); # supprimer saut de ligne
$found=0;
# voir si la rubrique est reconnue ou non
foreach my $choice(@choix){
if ($rubrique eq $choice){
$found=1;
print" OK";
return $rubrique;
}
}
print "\nVotre choix n'est pas reconnu.";
}
}
Et avec quelques modifications ces procédures peuvent être intégrées au script Perl précédent :
use strict; use warnings;
use Term::ReadLine;
print "\n=== Bienvenue a l'interface de patrons ===\n
>>> Ici vous pouvez choisir le(s) patron(s) et la/les rubrique(s).\n
>>> Tapez une categorie syntaxique. A n'importe quel moment appuyez sur Tab pour une liste des choix\n
\n";
my $fichierpatrons=&inputpatrons(); # l'utilisateur choisit les patrons
my $rubrique =&choisirrubrique(); # l'utilisateur choisit le rubrique
my $dossier_de_sortie="../Sorties/3_Choisir_patrons";
# Créer dossier de sortie si nécessaire
unless(-d $dossier_de_sortie){
mkdir $dossier_de_sortie or die;
}
# Extraction des patrons
&extractpatterns("../Sorties/2_SortiesDeCordial/$rubrique.cnr","$dossier_de_sortie/$rubrique.txt", $fichierpatrons);
#============== SUB : choisir rubrique ================>
sub choisirrubrique{
print "\nMaintenant vous pouvez choisir la rubrique dans laquelle chercher les patrons";
my $found=0;
while ($found==0){
print "\nVous avez le choix suivant : ";
my @choix=qw(ALAUNE CINEMA CULTURE ECONOMIE EUROPE IDEES INTERNATIONAL LIVRES MEDIAS PLANETE POLITIQUE SOCIETE SPORT TECHNOLOGIES VOUS VOYAGE);
print "@choix : ";
chomp(my $rubrique=<STDIN>); # supprimer saut de ligne
$found=0;
# voir si la rubrique est reconnue ou non
foreach my $choice(@choix){
if ($rubrique eq $choice){
$found=1;
print" OK";
return $rubrique;
}
}
print "\nVotre choix n'est pas reconnu.";
}
}
#============== SUB : définir les patrons ==============>
sub inputpatrons{
my $end=0;
my $patrons="";
my @list=();
my $term = Term::ReadLine->new('Catégories Syntaxiques');
while ($end!=1){
print">>> Voulez-vous creer un nouveau patron ? y/n : ";
my $reponse=<STDIN>;
my $i=1;
if ($reponse eq "y\n"){
print "Ecrivez les categories une apres l'autre. Quand vous aurez fini, tapez FIN.\n";
my $content = '';
my $attribs = $term->Attribs;
$attribs->{completion_function} = sub {
my ($text, $line, $start) = @_;
return grep { /^$text/i } (
"ADJ[A-Z]+","DET[A-Z]+","NP[A-Z]+","NC[A-Z]+","INT","VIND[A-Z1-3]+", "VCONP[A-Z1-3]+", "VIMP[A-Z1-3]+", "VINF[A-Z1-3]+", "VSUB[A-Z1-3]+", "VPAR[A-Z1-3]+", "PP", "PPER[A-Z1-3]*", "SUB", "PREP","ADJ[A-Z]+","ADV","PDP","COO");
};
my $OUT = $term->OUT || \*STDOUT;
while ( defined (my $text = $term->readline("Tapez la categorie syntaxique numero $i : ")) ) {
last unless $text ne "FIN"; # fin de la boucle quand on tape FIN
$content .= "$text\n"; # l'entrée s"ajoute au contenu du patron
$i++;
}
print $content;
@list=split("\n",$content); # séparer sur le saut de ligne
my $content=join(" ", @list); # join sur l'espace
my $goodorbad=&check($content); # vérifier si les catégories sont dans la liste ou non
# si tout va bien
if ($goodorbad eq "good"){
print "Votre patron : $content\n\n";
print "Souhaitez-vous garder ce patron ? y/n : ";
my $garder=<STDIN>;
if ($garder eq "y\n"){
$patrons.="$content\n";
print "Vos patrons :\n$patrons\n";
}
}
}
# Voulez-vous ajouter un autre ?
elsif($reponse ne "n\n"){
print "Je n'ai pas compris votre reponse.\n"
}
# fin des patrons
else{
$end=1;
}
}
my $fichierpatrons=ecrirepatrons($patrons);
return $fichierpatrons;
}
#============= SUB : Ecrire dans un fichier patrons.txt ============
sub ecrirepatrons{
my $patrons=shift;
my $fichieroriginal="patrons";
my $fichier=$fichieroriginal;
my $new=0;
my $k=1;
while ($new==0){
if (-f "$fichier.txt"){
$fichier="$fichieroriginal($k)";
$k+=1;
}
else{
$new=1;
}
}
open PATRONS,">:encoding(UTF-8)", "$fichier.txt" or die "Problème a l'ouverture du fichier - $!";
print PATRONS $patrons;
close PATRONS;
return $fichier.".txt";
}
#============= SUB : vérifier la bonne formation du patron ==============
sub check{
my $content=shift;
my @cats=(
"ADJ[A-Z]+", "ADJFS", "ADJMS", "ADJINT", "ADJSIG",
"DET[A-Z]+", "DETFS", "DETDPIG", "DETDMS", "DETDFS",
"NP[A-Z]+", "NPFS", "NPI","NPSIG",
"NC[A-Z]+", "NCMIN", "NCFS", "NCI","NCMP","NPSIG",
"VIND[A-Z1-3]+", "VINDP3S",
"PREP",
"ADJ[A-Z]+", "ADJINV", "ADJMS",
"ADV",
"PDP");
my @list=split(" ", $content);
foreach my $element(@list){
my $found=0;
foreach my $cat(@cats){
if ($element eq $cat){
$found=1;
}
}
if ($found==0){
print "Probleme avec la categorie $element. Veillez a mettre les categories en majuscules et tapez tab pour avoir une liste des possibilites.\n";
return "bad";
}
}
return "good";
}
#====================================>
# SUB : extract patterns
#====================================>
sub extractpatterns{
my $fichier_entree=shift;
my $fichier_sortie=shift;
my $patron=shift;
print "\n>>> Extraction des patrons\n";
#print $fichier_sortie;
my @phrase=();
my $compteur=0;
if ($fichier_entree=~/(.+?)\.cnr$/)# si c'est le correct format (.cnr)
{
print "\n$fichier_entree\n";
# Créer le fichier de sortie. Pendant le traitement le fichier sera
# rempli par concaténation, donc il est important d'initialiser le fichier
# vide au début.
if (!open (FILEOUT,">:encoding(iso-8859-1)","$fichier_sortie"))
{
die "Probleme a l'ouverture du fichier : $fichier_sortie $!\n";
}
close(FILEOUT);
# Lire le fichier en entrée
open(FILE_IN, "<:encoding(iso-8859-1)", "$fichier_entree") or die "HELP";
while(my $line=<FILE_IN>)
{
if ($line!~/PCTFORTE/) # traitement jusqu'à une ponctuation forte
{
chomp($line);
$line=~s/\r//;
push(@phrase, $line);
$compteur++;
}
else #quand on arrive à une ponctuation forte
{
#------ Traitement sur les tokens ------>
&traiter_liste_categories($fichier_sortie, $patron, $compteur, \@phrase);
#---- réinitialisation des tableaux ---->
@phrase=();
$compteur=0;
}
}
close(FILE_IN);
}
}
#====================================>
# SUB : Traitement des catégories
#====================================>
sub traiter_liste_categories
{
my $file_a_creer=shift;
my $fichier_patrons=shift;
my $compteur=shift;
my $refphrase=shift;
my @phrase=@$refphrase;
# Ouvrir le fichier de sortie (en mode 'append')
if (!open (FILEOUT,">>:encoding(iso-8859-1)","$file_a_creer")) {
die "Probleme a l'ouverture du fichier $file_a_creer : $!\n";
}
# Ouvrir le fichier de patrons
open(FILE_PATRONS, "<:encoding(iso-8859-1)", $fichier_patrons);
while(my $line_patron=<FILE_PATRONS>) # pour chaque patron syntaxique
{
chomp($line_patron);
$line_patron=~s/\r//g; # supprimer CR de Windows
my @patron=split(" ",$line_patron); # convertir le patron en une liste de catégories
my $patron_size = $#patron+1; # calculer la taille du patron (index du dernier élément +1)
my $result="";
# boucle sur les mots dans la phrase ($compteur = nombre de mots)
for (my $i=0; $i<$compteur; $i+=1)
{
#s'il sera possible de trouver le patron à partir de l'endroit actuel
if ($i+$patron_size<=$compteur)
{
my $k=$i; # $k = l'index du mot actuel
my $found=-1; # compteur pour le nbr d'éléments à trouver. Initialisé pour rentrer dans la boucle
#pour chaque élément dans le patron - si à chaque fois la catégorie est trouvée ($found!=0)
for (my $j=0; ($j<$patron_size) && ($found!=0); $j+=1)
{
# si c'est la première fois, intialiser le nbr de cats trouvées à 0
if ($found==-1)
{
$found=0;
}
# s'il y a une correspondance entre la catégorie du mot actuel et la catégorie du patron
if ($phrase[$k]=~/(.+?)\t(.+?)\t$patron[$j]/)
{
$result=$result." ".$1; # ajouter le mot au résultat
$found++; # $found=$found+1
$k++; # enquêter sur le mot suivant
# si le nbr de catégories trouvées est égal au nombre de catégories dans le patron
if ($found==$patron_size)
{
#print "$result\n";
print FILEOUT $result."\n"; # imprimer le résultat dans le fichier
}
}
# s'il n'y a pas de correspondance,on ne continu pas de chercher
#jusqu'à la fin du patron -> la boucle finit et on passe au mot suivant
else
{
#print"\nrestarting\n";
$result="";
$found=0;
}
}
}
}
}
close(FILE_PATRONS);
close(FILEOUT);
}
Un exemple du déroulement du programme :
Le choix des patrons :

Et le choix de la rubrique :

La sortie, comme avec les autres programmes et une sortie texte brut avec les patrons choisis, une séquence par ligne :
NC[A-Z]+ PRP NC[A-Z]+ (Sorties de Cordial) pour la rubrique CINEMA :
Faiseurs de culture
consensus en éclats
oeuvre de politique
mouvement de protestation
Lauréat' pour modèle
terre d' écueil
mal sans cause
lutte sans merci
film de marionnettes
lettres de noblesse
homme de foi
hommes avec Dieu
année de scrutin
modélisations par ordinateur
...

Cliquer sur les liens pour télécharger les fichiers et les scripts.