
Le script Bash final :
Voilà donc notre script bash fini, agrémenté de quelques explications :
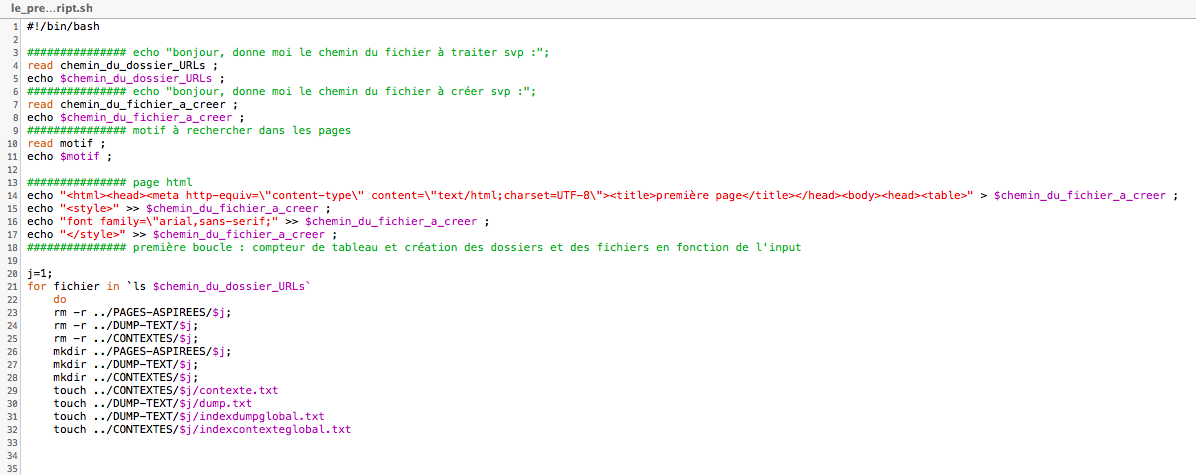
Donc voici le début du script, on commence par récupérer les chemins et le motif dans le input, puis on créer le début de la page html qui recevra les tableaux, et enfin, dans la première boucle, nous créons aussi tous les dossiers et fichiers vide dont nous nous reservirons ensuite.
Notre problème n'était pas tant de créer dès le début du script les fichier, mais surtout d'effacer ceux qui était présent auparavant, car cela fait se concaténer les contenus.
Et si nous utilisons deux commandes pour les dossiers plutôt que 'mkdir -p' qui pour pourrait écraser et recréer, c'est simplement car cela ne marchait pas et que les fichiers cherchaient à s'accumuler.
Nous incrémentons un premier compteur "j", qui correspondra aux 3 langues - 3 tableaux, toujours séparés dans les dossiers.
Un deuxième compteur est incrémenté juste ensuite, pour compter les URLs que l'on a donné en lien, et directement, il est utilisé pour créer la première colonne de notre tableau, qui compte les URLs.
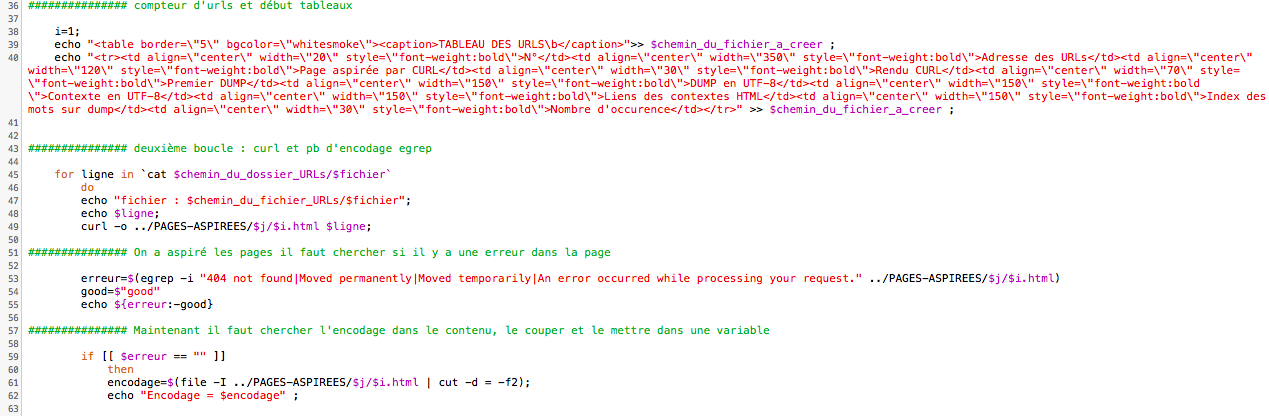
Nous arrivons donc à la deuxième boucle, qui, pour chaque ligne -correspondant à une URL- des fichiers, va aspirer la page au moyen de CURL. Ensuite nous devons vérifier si la page a une erreur, si elle n'en a pas, elle nous renvoie 'good' et continue. Nous récupérons l'encodage au moyen de File -I et le mettons dans un variable.
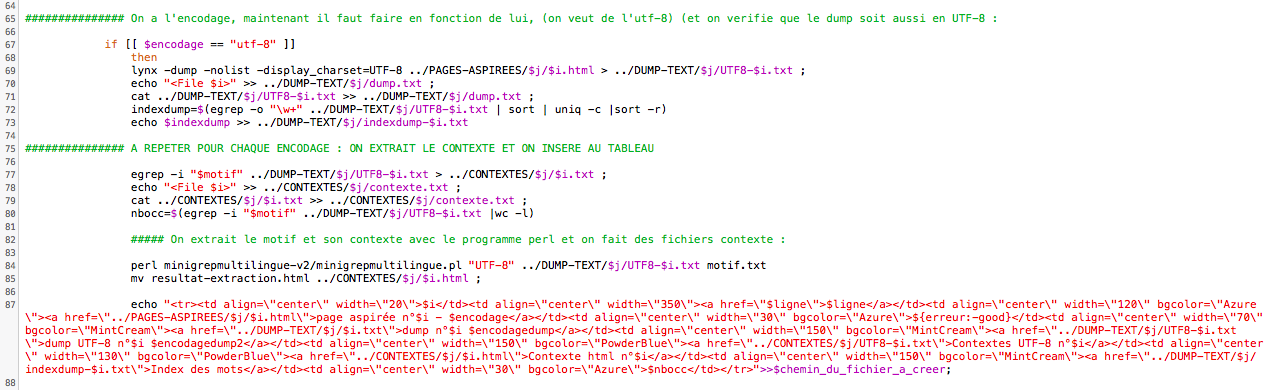
Si la variable contient 'utf-8' alors cela continue ici, avec "lynx -dump -nolist -display_charset", expliquée dans un autre article, nous créons un dump, lequel sera en utf-8. Nous ajoutons aussi la balise séparatrice des fichiers pour le fichier ou se concatènent ensuite les dumps. Puis nous faisons un index sur ces dump, au moyen d'un egrep -o et de l'expression régulière "\w+". L'index sera alors placé dans la dernière colonne de notre tableau. Ensuite, nous passons à l'extraction du motif dans les dumps, qui extrait en fait toute la ligne sur laquelle se trouve le motif, nous créons un fichier contexte individuel et un fichier contexte global, dans lequel la balise de séparation est aussi ajoutée. Nous comptons aussi le nombre d'occurences, même si cela ne marche que sur les pages qui était initialement en UTF-8.
Vient alors l'utilisation du programme perl 'minigrepmultilingue', lequel fera une extraction des motifs et les insérera dans un page html.
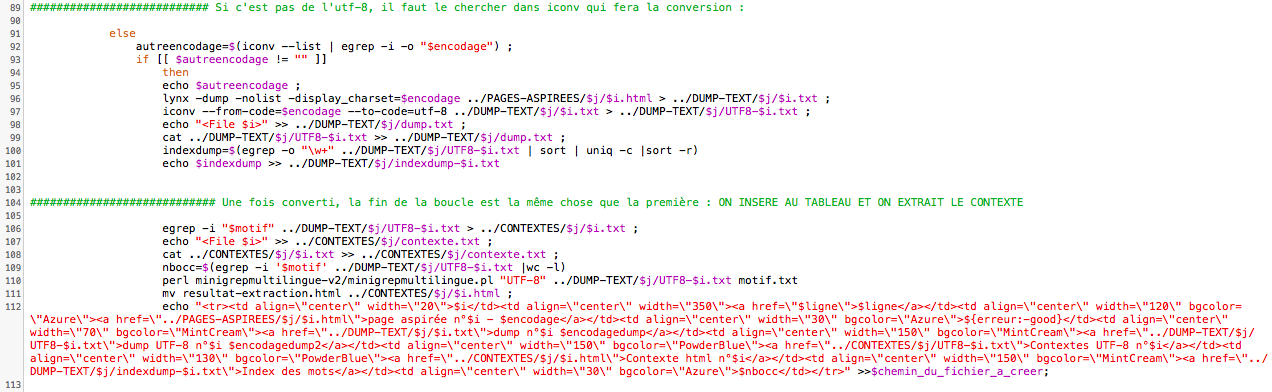
Nous passons à la suite, si la condition selon laquelle l'encodage serait de l'utf-8 n'est pas respectée, nous arrivons ici, nous prenons la valeur de la variable encodage, nous regardons si elle se trouve dans la liste de iconv, si elle y est, alors iconv fait la conversion, puis nous retraitons le fichier comme nous l'avons fait sur ceux directement en utf-8.
A noter, la plupart des pages traitées ici sont initialement en iso-8859, et le comptage des occurences ne fonctionne pas sur ces fichiers, cela nous renvoie un valeur 0. Cela parait étrange étant donné le fait que l'extraction du motif et du contexte au moyen de egrep fonctionne exactement de la meme façon que sur les autres pages par contre. Nous pas su trouver la réponse à ce problème.
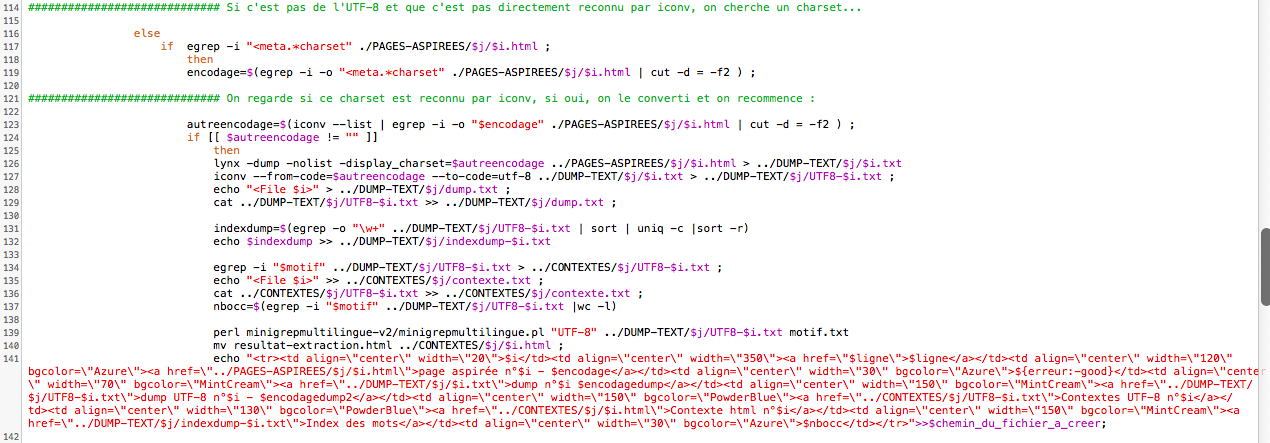
Nous en venons au point où les pages ne seraient pas en utf-8 ou en tout cas, pas reconnaissables par ce que file -I à renvoyer à iconv. Donc nous chersons un charset, Si il y en a un, nous prenons la valeur qui le suit, nous la mettons dans notre variable envodage, et nous traitons le fichier comme les autres!
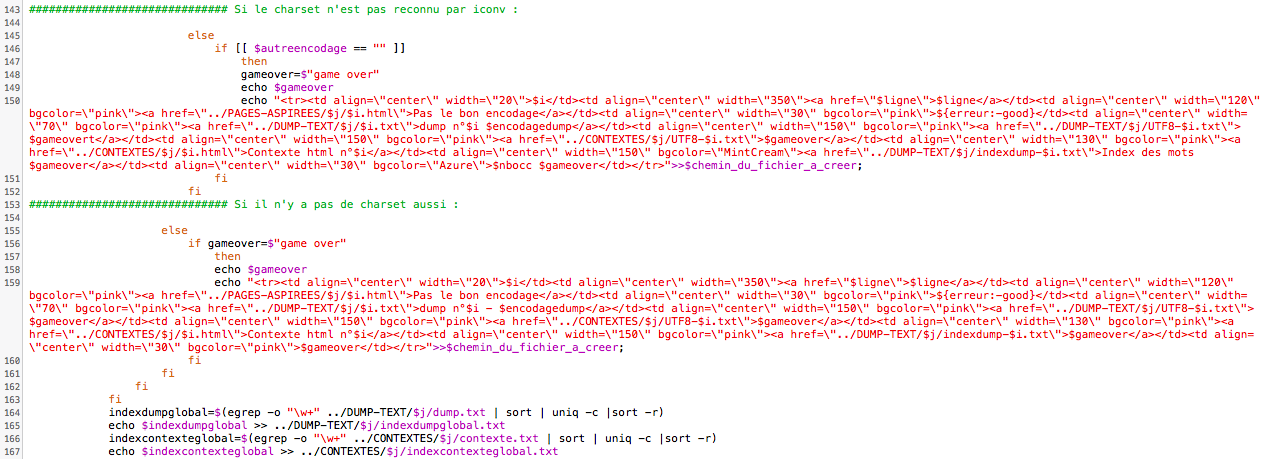
Et là par contre, si le charset n'est pas reconnu par iconv, alors nous ne traitons pas ce fichier.
De la même façon, si il n'y a pas de charset de trouvé, nous ne traitons pas le fichier.
Nous refermons alors tout nos 'if' par 'fi' et alors nous prenons pour les fichier traités, les dumps globaux et les contexte globaux, et nous créons les index globaux sur ceux-ci.
Il reste alors les pages des URLs qui contenaient des erreurs :
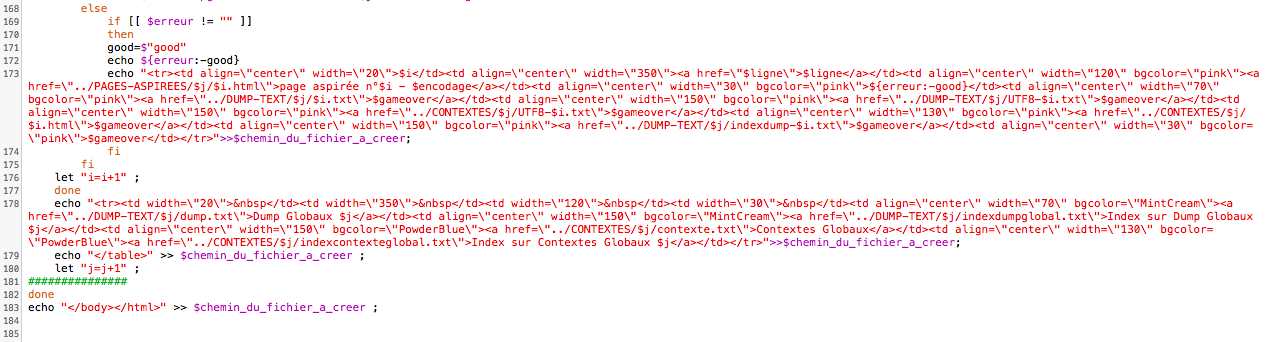
Ces pages contenant des erreurs ne seront pas traitées, leur ligne dans les tableaux html sera marquée en rose comme celles de ceux qui ont un encodage non reconnu par iconv ou pas de charset et dont nous ne savons quel est l'encodage.
Nous incrémentons le compteur de fichiers de +1, fermons la deuxième boucle, et ajoutons la dernière ligne de chacun des tableaux avec les dumps et contextes globaux et leurs index.
Nous fermons ensuite la première boucle, les tableaux et la page html et c'est ainsi que se termine notre programme.