
Le script pas à pas
1. Nos premières commandes Bash :
Lors des premiers cours nous avons fait connaissances avec les premières commandes Bash.
/ : correspond à la racine pour un chemin absolu et sépare les dossier et les fichiers au sein d'un même chemin. Un chemin relatif affiche le contenu d'un répertoire alors qu'un chemin absolu affiche le fichier de destination. Un chemin absolu commence par "/", il part de la racine, un chemin relatif, non, il part du dossier où l'on se trouve déjà.
. : correspond au répertoire courant, où de manière imagée à celui dans lequel nous nous trouvons. Dans un Unix, ".." est une manière de dire que l'on quitte son répertoire courant.
pwd : print working direct : affichage du chemin absolu du répertoire courant.
mkdir : make directory : création d'un dossier.
touch : touch : création d'un fichier.
cd : change directory : changer/sortir du dossier.
ls : list : afficher le contenu d'un dossier.
APPLICATION ( exercices tirés de "Unix for the Beginning Mage") :
1)

2)

# Cela nous permet de quitter ce répertoire courant qui était projetencadré pour rentrer dans spells. Cela fonctionne car c'est un chemin relatif.

# Cela fonctionne bien, le premier indique de sortir du répertoire courant par un chemin relatif, il n'y a pas de slash au début, et les deux fois deux points indiquent le dossier 'home' en repassant par 'projetencadré', et c'est bien là où nous arrivons.
Le deuxième indique de quitter le dossier projetencadré puis d'y retourner, ce qui est vérifié.

# Cela ne fonctionne pas car il y a un "/" au début qui indiquerait un chemin absolu, qui renverrait à la racine, or ce n'est pas le cas, nous sommes dans un chemin relatif, il ne faut donc pas mettre de '/'.
3)

# Le déplacement n'est pas possible car il n'y a pas de dossier à ce nom.
2. Et les commandes Bash se succèdent :
man : accès à la documentation d'autres commandes.
ls -lrt : list - use a long listing format, reverse order while sorting, sort by modification time : liste des noms de tout les fichiers du répertoire courant en long format et en inversant l'ordre chronologique.
ls -a : list -all : liste tout les fichiers, même cachés.
cp : copy : copie d'un fichier, et peut écraser le contenu d'un autre.
-i : interactive : permet d'avoir une question avant d'effectuer la commande demandée.
cp -i : copy -interactive : permet que Bash demande la confirmation avant d'écraser la contenu d'un fichier.
mv : move : déplacer et renommer des fichiers.
rm : remove : supprimer des fichiers
rmdir : remove directory : supprimer un dossier entier
cat : concatenate : affiche le contenu d'un fichier sur le terminal.
echo : affichage de l'argument sur le terminal.
echo >; : affichage de l'argument dans un fichier, en écrasant le contenu préalable.
echo >>; : affichage de l'argument dans un fichier en s'ajoutant au contenu préalable.
grep : affichage d'un objet recherché dans un fichier.
egrep = grep -E : affichage d'un objet recherché dans un ficher en expression régulière.
| : pipe : avec le pipe, le résultat de la première commande est envoyé à celle qui suit.
ex : cmd1|cmd2|cm3 : le résultat de cmd1 est envoyé à cmd2, etc...
cut : cut : couper
ex : ls -lrt|cut -d":"f2|cut -d" " -f2
3.La recherche des URLs, la constition du corpus et nos premiers problèmes :
Nous commençons donc à rechercher des URL pour la constitution de notre corpus, basé sur les langues française, anglaise et allemande. Le fait est que notre sujet porte sur un phénomène et sur sa perception dans différents pays. Le premier problème rencontré est celui des URL qui débouchent sur des pages rédigées en langue anglaise, mais qui parlent du phénomène dans des pays qui ne sont pas anglophones, comme la chine :
Exemple
Que faire de ces URLs? Si nous les intégrons, nous devrons changer les critères de notre analyse, en ne prenant pas en compte les pays, mais juste les langues, or est-ce que les langues sont ici un critère pertinent et suffisant? De la même façon, l'Inde est un pays qui parle anglais, mais d'un point de vue culturel, peut-on l'amalgamer à la culture américaine, représentée par la majeure partie du corpus anglophone?
Exemple
Doit-on aussi amalgamer Angleterre et Etats-Unis? Etats-Unis / Canada? Australie /Etats-Unis? Doit-on mettre tout les articles sur le même plan?
Nous rencontrons les mêmes problèmes avec la langue française, la presse française consacrant des articles à ce phénomène mais au Etats-Unis, doit-on les prendre aussi?
Exemple
Exemple
Cela étant dit, c'est une problématique récurrente de la constitution des corpus, et une des limites à l'automatisation de cette opération.
4.Un peu de HTML :
Le problème ici, c'est de vouloir parler du HTML dans une page HTML. Après avoir retourné une bonne partie de tout les forums, tuto, etc.. se trouvant sur le le web, après avoir essayé des balises de type "

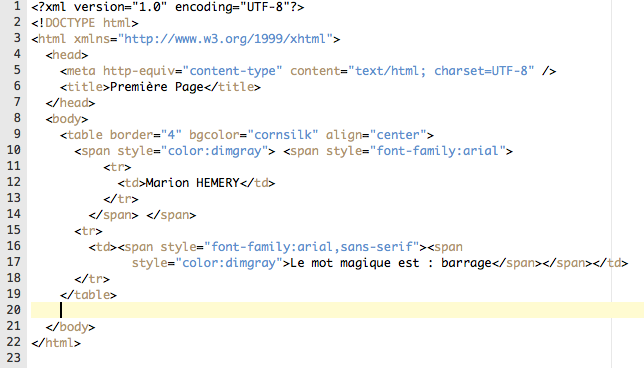


5.Les débuts du programme :
Nous avons commencer à rédiger un script qui nous permettra de créer un tableau, lequel reprenant sur chacune de ses lignes une des URLs, et, pour l'instant, une première colonne numérotant chacune des URLs, une deuxième avec lien de la page sur internet, et une troisième renvoyant à la page stockée sur notre machine, laquelle devra être mise en texte brut.
Nous avons besoin que le programme bash crée lui même les colonnes du tableau, en fonction du nombre de ligne du fichier qui contient les URL : il doit compter les URL et les répertorier dans le tableau qu'il va automatiquement créer.
Le programme bash doit pouvoir compter les URL : Comment lit-on un fichier dans un programme? En bash, il n'y a pas de fonction qui permette d'ouvrir un fichier et de lire les lignes. Il faut que pour chacune des lignes du fichier, le programme écrive une ligne dans le tableau html automatiquement. Cela consiste à dire que chacune des lignes du fichier sont des éléments d'un ensemble : comme une liste d'objet. Il faut que bash voit le fichier comme une liste : la commande "cat nom_d_un_fichier" va afficher les lignes du fichier, puis il faudra appliquer une boucle "for #chacun des éléments in #ensemble do #appliquer un traitement done"
Voyons ce qu'il en est de notre script :
Dans un premier temps :
## Ce programme prend en argument un nom de fichier contenant des urls
## et produit un fichier sortie html avec ces urls sur chaque ligne d'un tableau
## Ces deux fichiers sont indiqués par un autre fichier texte nommé "input.txt"
## Nous n'avons donc plus à répondre à ces questions :
#echo "bonjour, donne moi le chemin du fichier à traiter svp :";
#echo "bonjour, donne moi le chemin du fichier à créer svp :";
## les fichiers sont indiqués dans input.txt
 ## Il faut
inserer la boucle, comme nous l'avons vue plus haut, dans le
fichier html qui va récupérer les URLs sur chaque ligne dans
le fichier et les insérer au tableau html
## Il faut
inserer la boucle, comme nous l'avons vue plus haut, dans le
fichier html qui va récupérer les URLs sur chaque ligne dans
le fichier et les insérer au tableau html## Il faut aussi mettre en place un compteur, par un variable (i), qui numérotera les lignes du tableau et réaparaitra dans certains noms de fichiers créés.
## La définition de l'ensemble se fait en envoyant le résultat de la commande "cat" dans l'ensemble :`cat $chemin_du_fichier`
 ##
création d'une troisieme colonne sur le tableau : le lien
vers une page qui soit la récupération de l'URL dans un
fichier sur la machine personnelle
##
création d'une troisieme colonne sur le tableau : le lien
vers une page qui soit la récupération de l'URL dans un
fichier sur la machine personnelle## donc il faut recuperer l'URL, via curl.
## curl : renvoie le contenu en output, il faut des chevrons pour renvoyer le contenu
## curl -o file : permet aussi de spécifier le nom de fichier qui comportera le contenu
## let "i=i+1" permet de faire augmenter la variable à chaque ligne
Pour l'instant, le programme marche bien, mais le fait est que nous ne faisons qu'un tableau, or, il en faudra un pour chaque langue, soit pour chaque fichier d'URLs, et dans ce cas, il nous faudra essayer de mettre un compteur de tableau tout en gardant un même compteur pour les URLs, pour qu'elles concordent avec les pages aspirées.
Qui plus est, même si nous avons récupéré le HTML sans le CSS et le paramétrage, il va falloir nettoyer les fichiers des balises HTML..
Mais voici quelques illustrations de notre travail, avec en premier le rendu sur bash, et enfin le tableau HTML final:
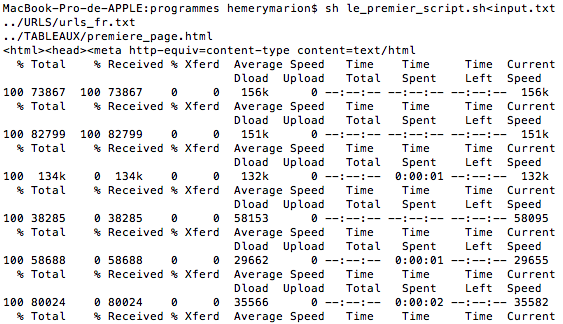
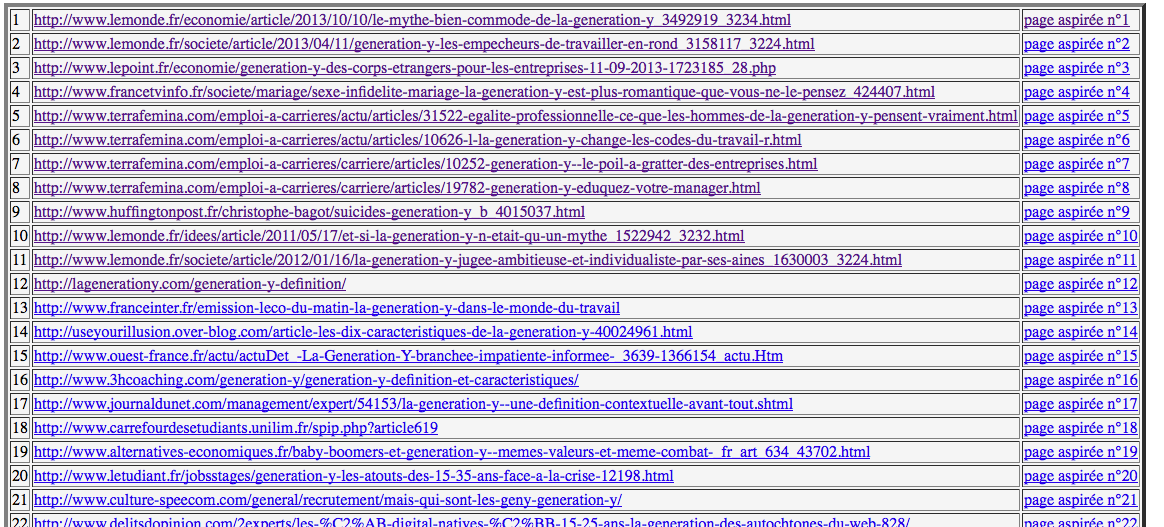
6.Un peu plus de programme :
Nous nous étions arrêter sur un script qui nous permettait d'avoir un tableau, ce qui, pour les trois langues sur lesquelles nous travaillons, était insuffisant. Alors voilà notre solution :
D'une part, nous avons trois tableaux bien séparés avec un titre indiquant la langue, d'autre part, le compteur pour les URLs continu sur les 3, ce qui permet de ne pas avoir de problèmes avec les pages aspirées.
Alors, dans un premier temps, nous avons modifié notre fichier input.txt, qui comprend maintenant:
../URLS/urls_fr.txt
../URLS/urls_en.txt
../URLS/urls_de.txt
../TABLEAUX/premiere_page.html
Ensuite, il fallait que le programme prenne ces trois fichiers en compte :
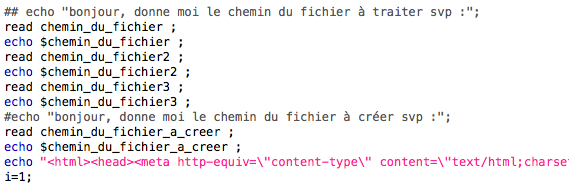
Ce qu'il fait, nous mettons le contenu dans trois variables différentes, que nous réutiliserons après, pour chacun des tableaux :

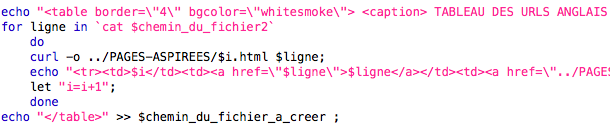
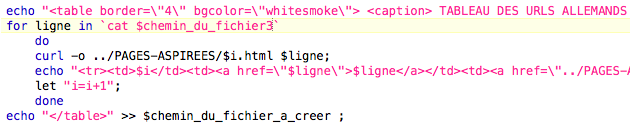
La variable reprise change donc à chaque tableau, et nous changeons le titre. Voilà le résultat :

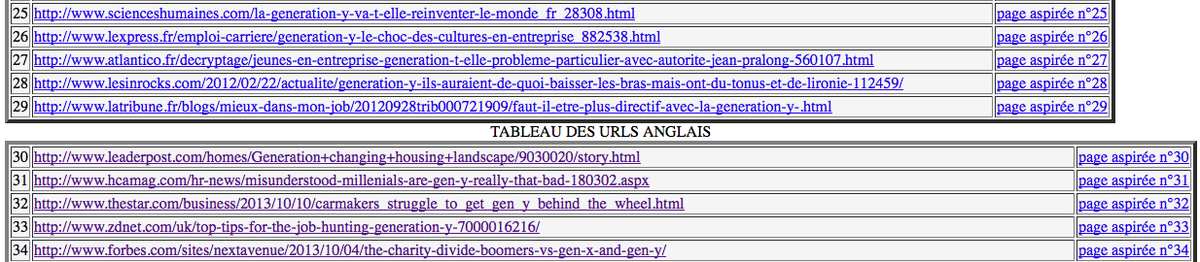

Bon, le résultat est ce que nous attendions... Et le copié/collé, c'est pas très long étant donné que nous n'avons que 3 tableaux et que seulement deux éléments sont à changer à chaque fois. Mais le fait est que si nous voulions avoir plus de tableaux, cela pourrait vite devenir long et fastidieux et il existe peut-être une manière de dire à Bash de nous refaire un tableau sur le modèle de celui qui existe déjà et de mettre un compteur au tableau...
Et puis, il est aussi temps pour nous de remplir ces jolis tableaux d'URLs...
7.Les principales commandes :
Pour récapituler les principales commandes utilisées dans notre script bash :
CURL
LYNX
ICONV (et file -I)
EGREP
Voici donc la présentation de chacune d'entre-elles :
CURL :
C'est l'équivalente à wget pour travailler dans un environnement mac.
Elle nous permet la navigation en ligne et donc d'aspirer des pages web, le tout de manière non interactive, le curl peut tourner en arrière-plan. Voici une ligne l'utilisant :
curl -o ../PAGES-ASPIREES/$j/$i.html $ligne;
L'option -o (--output) permet d'indiquer le fichier qui servira a recueillir l'output de la commande, laquelle aspire l'url qui correspond à la variable $ligne (renvoyant aux lignes des listes d'URL).
LYNX :
Cette commande s'installe pour nos cas via Xcode et Macport, ce qui nous avait fait prendre un léger retard, mais une fois installée, la commande lynx est un navigateur en ligne de commande : elle permet de naviguer avec l'URL soumis.
Nous l'utilisons avec plusieurs options :
-dump : cela permet la suppresion des balises de manière automatique.
-nolist : cela permet de supprimer les liste de liens dans le dump.
ET SURTOUT :
-display_charset=$encodage : permet de prendre en compte l'encodage de la page aspirée pour garder le même dans le dump.
Cette dernière option a été oubliée pendant un moment et a été ajoutée après, elle a résolu de nombreux problèmes d'encodage jusqu'alors incompris... Des pages aspirées en UTF-8 était réencodée en ISO-8859 pour les dump, ce qui nous paraissait déroutant au premier abord..
Ce qui donne :
lynx -dump -nolist -display_charset=UTF-8 ../PAGES-ASPIREES/$j/$i.html > ../DUMP-TEXT/$j/UTF8-$i.txt ;
Pour les pages qui ne sont pas encodée en UTF-8, nous utilisons une variable (dont la valeur est celle récupérée par un file -I) pour garder l'autre encodage qui est utilisé dans un premier dump et puis ensuite nous réencodons dans un autre fichier (dump en UTF-8), tout cela au moyen de -iconv.
ICONV :
Voici une vue d'ensemble pour comprendre le cheminement :
else
autreencodage=$(iconv --list | egrep -i -o "$encodage") ;
if [[ $autreencodage != "" ]]
then
echo $autreencodage ;
lynx -dump -nolist -display_charset=$encodage ../PAGES-ASPIREES/$j/$i.html > ../DUMP-TEXT/$j/$i.txt ;
iconv --from-code=$encodage --to-code=utf-8 ../DUMP-TEXT/$j/$i.txt > ../DUMP-TEXT/$j/UTF8-$i.txt ;
Dans cette partie nous nous regardons avant tout que l'autre encodage repéré au moyen du file -I fait partie de la liste de iconv (en faisant passer la variable par egrep), c'est à dire que nous cherchons si c'est un encodage que iconv va pouvoir réencoder.
La syntaxe de iconv :
iconv --from-code='encodage de départ' --to code='encodage voulu'
aussi formalisable de cette façon iconv -f "" -t ""
suivi de 'fichier de input' > 'fichier de output'
Certains des encodages de nos pages ne sont pas supportés par iconv, comme 'binary'.
NB : La commande file -I nous sert à récupérer l'encodage de la page aspirée (et seulement cela grâce au pipe coupant le reste) :
encodage=$(file -I ../PAGES-ASPIREES/$j/$i.html | cut -d = -f2)
Le seul petit problème rencontré sur cette commande a été de ne pas savoir que sur Mac la syntaxe changeait et qu'il fallait un -I majuscule et non minuscule, mais au moins on très bien compris l'importance que pouvait prendre un changement d'environnement!
EGREP :
Elle est utilisée avant et après les autres énumérées plus haut qui en dépendent dans notre programme .
Elle affiche à l'écran toutes les lignes du '$fichier' qui contiennent une chaine désignée par patron '$motif'
L'interêt de Egrep : elle accepte les expression régulières (variante de grep -E)
Ses options notables :
-n : permet de faire affichier le numero de la ligne qui est retenue
-c : (count) : permet non pas d'afficher les lignes qui contiennent le motif mais de les compter
-v : (reverse) : affiche les lignes qui ne contiennent pas le motif
-i : (ignore case) : en majuscules, minuscules, où le mix des deux
-o : (occurence) : permet d'afficher les occurences
-C 1 : permet de prendre 1 ligne avant et une ligne après
-A 2 -B 5: prend 2 lignes avant et 5 après
...
Et on peut cumuler : -ic
Ses utilisations :
1) Elle repère si il y a des erreurs dans les pages que nous avons aspirées :
erreur=$(egrep -i "404 not found|Moved permanently|Moved temporarily" ../PAGES-ASPIREES/$j/$i.html)
good=$"good"
echo ${erreur:-good}
Si il y a une erreur, elle les stock dans $erreur, qui est ensuite retranscrite dans notre terminal, si il n'y en a pas, c'est la valeur par défaut '$good' est retranscrite. Cela apparait aussi dans la colonne 'rendu curl' de nos tableaux.
2) Elle repère les encodages
autreencodage=$(iconv --list | egrep -i -o "$encodage")
Elle nous sert à récupérer la valeur de $encodage pour la vérifier dans la liste d'iconv avant de la remettre dans une autre variable qui servira au réencodage.
3) Elle repère le motif
egrep -i "$motif" ../DUMP-TEXT/$j/UTF8-$i.txt > ../CONTEXTES/$j/$i.txt ;
cat ../CONTEXTES/$j/$i.txt >> ../CONTEXTES/$j/contexte.txt ;
Elle sert aussi à rechercher notre motif dans les dump pour extraire nos contextes. (Les contextes individuels sont ensuite concaténés dans un fichier les regroupant pour chaque langue.)
4) Elle nous sert a créer nos index
indexdump=$(egrep -o "\w+" ../DUMP-TEXT/$j/UTF8-$i.txt | sort | uniq -c |sort -r) >> ../DUMP-TEXT/$j/indexdump-$i.txt
Ici, nous l'utilisons pour créer l'index sur chacun de nos dump, mais nous l'utilisons aussi à la fin du programme pour les autres index :
indexdumpglobal=$(egrep -o "\w+" ../DUMP-TEXT/$j/dump.txt | sort | uniq -c |sort -r |less) > ../DUMP-TEXT/$j/indexdumpglobal.txt
indexcontexteglobal=$(egrep -o "\w+" ../CONTEXTES/$j/contexte.txt | sort | uniq -c |sort -r |less) > ../CONTEXTES/$j/indexcontexteglobal.txt
Elle est utilisée avec l'expression régulière \w+ permettant de prendre en compte les caractères alphanumériques (et les underscores) et de le répéter une fois ou plus.
L'index se fait page par page, dans l'ordre inverse, puis on enlève les doublons, on retrie et on le met dans un fichier output.
5) Elle devrait nous aider à avoir le nombre d'occurence de notre motif...
Dernière utilisation : utilisation problématique :
Nous essayons d'avoir le nombre d'occurences de notre motif par dump :
nbocc=$(egrep -i -f "$motif"../DUMP-TEXT/$j/UTF8-$i.txt|wc -l)
Nous avons essayé différentes options mais nous n'avons pas encore réussi à avoir le nombre d'occurences... La recherche de la solution est en cours..
Dans cette dernière utilisation, l'option -f permet d'indiquer que l'on prend le motif dans un fichier..
Voilà en tout cas les multiples cas où nous utilisons la commande egrep!
8.Les expressions régulières :
Nous avons vu qu'avec egrep, nous utilisons les expressions régulières, faisons donc un point dessus :
Elle nous permettent de repérer un motif dans un texte, lequel pouvant subir des variations (avec un "s" ou sans "s" par exemple), mais aussi de prendre en compte plusieurs mots comme des alternatives l'un à l'autre, ou de laisser un espaces avec des caractères indéterminés, ou bien encore de cherche le mot qui suit un autre mot, quel qu'il soit.. Les utilisations sont multiples. Nous utilisons "\w+" dans la version final de notre script pour faire les index. Cela nous permet de prendre les lettres, les chiffres et les underscore, mais aucun des autres caractères, qui sont alors les limites des mots. Les expressions régulières sont donc un moyen très puissant de rechercher des mots/affixes/segments dans des textes.
Par ailleurs, nous avons utilisé les expressions régulières pour notre motif. La valeur de notre variable "$motif" :
\gen y|generation y|génération y|digital natives?|«generation y»|Yers?|millennials\b
\ et \b déterminent le début et la fin de l'expression régulière pour notre motif dans le minigrep (\b correspond à un espace, un signe de ponctuation, le début ou la fin d'un texte). Mais sinon on utlise aussi ^ et $ pour le début et la fin d'une expression régulière. Dans notre motif, nous utilisons beaucoup de | car cela permet de créer des alternatives. La génération y ayant plusieurs appeltation cela nous permet de toutes les inclurent dans un seul motif.
Nous pouvons aussi voir que nous utilisons le ? qui permet de rendre un caractère facultatif, mais si il est présent, il n'est présent qu'une seule fois, contrairement à une *, qui rendrait le caractère facultatif mais aussi répétable à l'infini.
Avec les problèmes d'accents que nous avons eu, nous avons gardé les deux versions "génération y" pour le français et "generation y" pour l'anglais et l'allemand, mais normalement, cela est formalisable de cette façon "g.n.ration y", le point étant un caractère, n'importe lequel, mais présent une fois.
Mais à part notre motif, le + permet de répéter un caractère une ou plusieurs fois mais non facultatif. Avec des {} nous pouvons déterminer le nombre de fois que l'on attend un caractère ou un ensemble de caractères, car nous pouvons aussi mettre des suites de caractères entre ().
Sinon les expressions comme \w+ sont très pratiques, car très courtes, et plus facilement utilisable que leur correspondance sous la forme de ^A-Za-z0-9_$ avec + indiquand que tout caractère peut être répété à l'infini.
\W indique le contraire de \w, c'est-a-dire tout ce qui n'est pas lettre, chiffre et underscore.
\s permet de rechercher tout les caractères non imprimables : espaces, sauts de lignes... \S définit son contraire.
\d définit les caractères numériques, et \D, son contraire.
Et le \B correspond au contraire de \b, défini plus haut.
9.Pour l'assemblage de tout ça :
Rendez-vous à la section suivante :