Le Trameur : statistiques
L’étape finale de notre travail était d’effectuer l’analyse statistique des occurrences et cooccurrences des formes du mot "migrant", à partir d'un outil de textométrie : le Trameur. Il est composé de deux éléments : la Trame et le Cadre. La textométrie permet de calculer les éléments (les contenus textuels) dans certaines zones de texte, ou parmi les unités d’un texte. La Trame est un système de coordonnées sur le texte dans lequel chaque élément est associé à un numéro d’ordre (Fleury 2013)*. Elle permet de repérer des zones textuelles sur un corpus et de décrire les systèmes des zones (parties, paragraphes, phrases, sections, etc.). Les descriptions sur ces systèmes se trouvent dans une structure de données : le Cadre. Précisons aussi que le Trameur intègre le Treetagger (étiquetage des catégories grammaticales et lemmatisation). Nous avons analysé nos corpus par langue en plusieurs sections, que nous expliquons précisément dans la première analyse au fur et à mesure. Pour les analyses qui suivent, nous ne nous contentons que des commentaires sur les résultats.
*Fleury, S. 2013, Le Métier Textométrique aka Le Trameur, Centre de Textométrie – CLA2T
Analyse de l'anglais
Section Forme-lemme :
Premièrement, nous avons chargé la base, c'est-à-dire le texte annoté avec des balises, et la Trame avec le Cadre. Les balises étaient prises en compte sous la forme de type "Lexico". Dans le texte, il y a une Trame et un Cadre (balise de début et de fin) qui délimitent les segments du texte du corpus dans lequel nous allons faire le calcul de fréquence du mot et de ses cooccurrents.
Nous avons ensuite généré les formes de "migrant" en utilisant l’expression régulière \bmigrant\w?\b. Cela nous a fourni non seulement les mots "migrant" et "migrants" mais aussi "migrantâs" (le symbole ‘ n’était pas reconnu) que nous avons corrigé à la main.
Section Ventilation :
Nous avons effectué le calcul de la fréquence absolue des formes \bmigrant\w?\b qui est presque la même dans les sites d’opinion publique (blogs, forums) et sites officiels. La fréquence la plus basse est celle des sites de presse.
Fréquence du motif \bmigrant\w?\b:
- Blogs forums : 258
- Sites Officiels : 257
- Presse : 144
Ensuite, nous sommes passé à la création d’accroissement du vocabulaire. Si nous regardons la fréquence des formes "migrant" et "migrants", nous voyons bien que les mots sont plus fréquents dans les sites d’opinion publique. Concernant la fréquence relative, pour les blogs et les forums : ≈ 19%, la presse : = 34%, les sites officiels : ≈ 15,5% de tous les mots (figure cu-dessous).
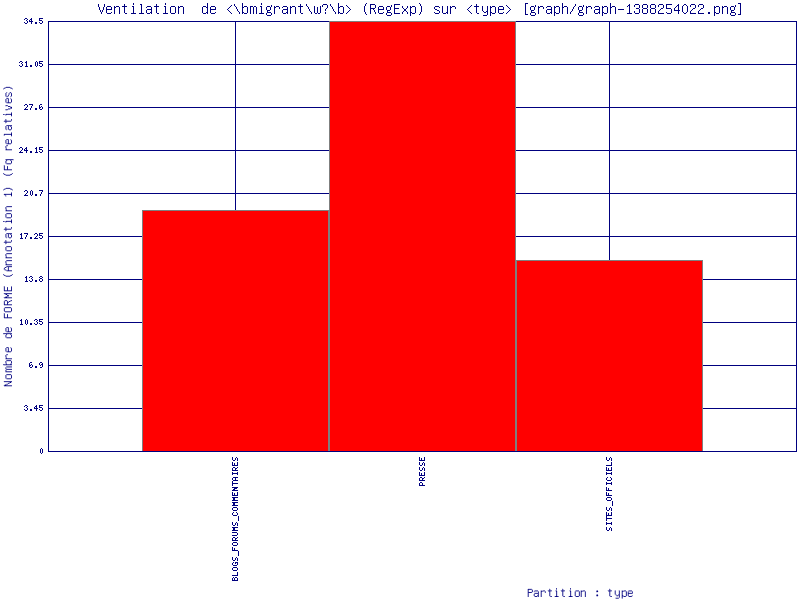
Section Cooccurrence :
C’est une section très importante dans notre analyse car elle permet de rechercher les mots cooccurrents des formes de "migrant" dans l’ensemble des parties annotées. Nous étions obligées d’utiliser et d’éteindre le stoplist pour pouvoir éviter les catégories grammaticales comme les pronoms, les symboles et les prépositions de s’infiltrer dans les résultats des requêtes. Nous avons défini le seuil de co-fréquence et cela a généré l’ensemble des mots définis dans l’expression régulière avec le nombre de leur fréquence. Les formes "migrant" et "migrants" partagent les quatre mots communs (nous avons fait une requête à part dont la co-fréquence est plus petite pour obtenir plus de résultats pour la forme "migrant" au singulier) : people, immigration, think, EU, work, UK, 2013.
figure 2 :
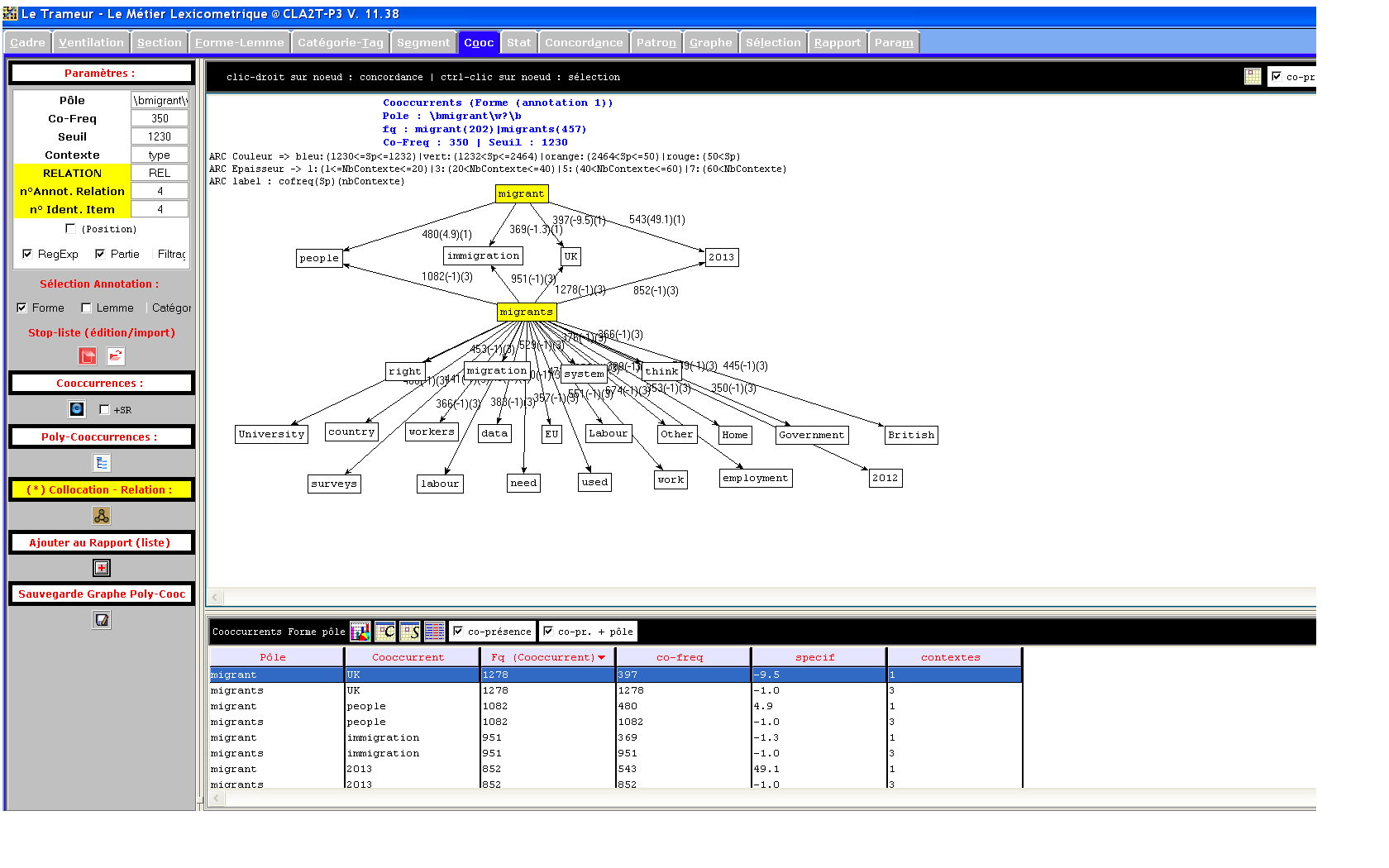
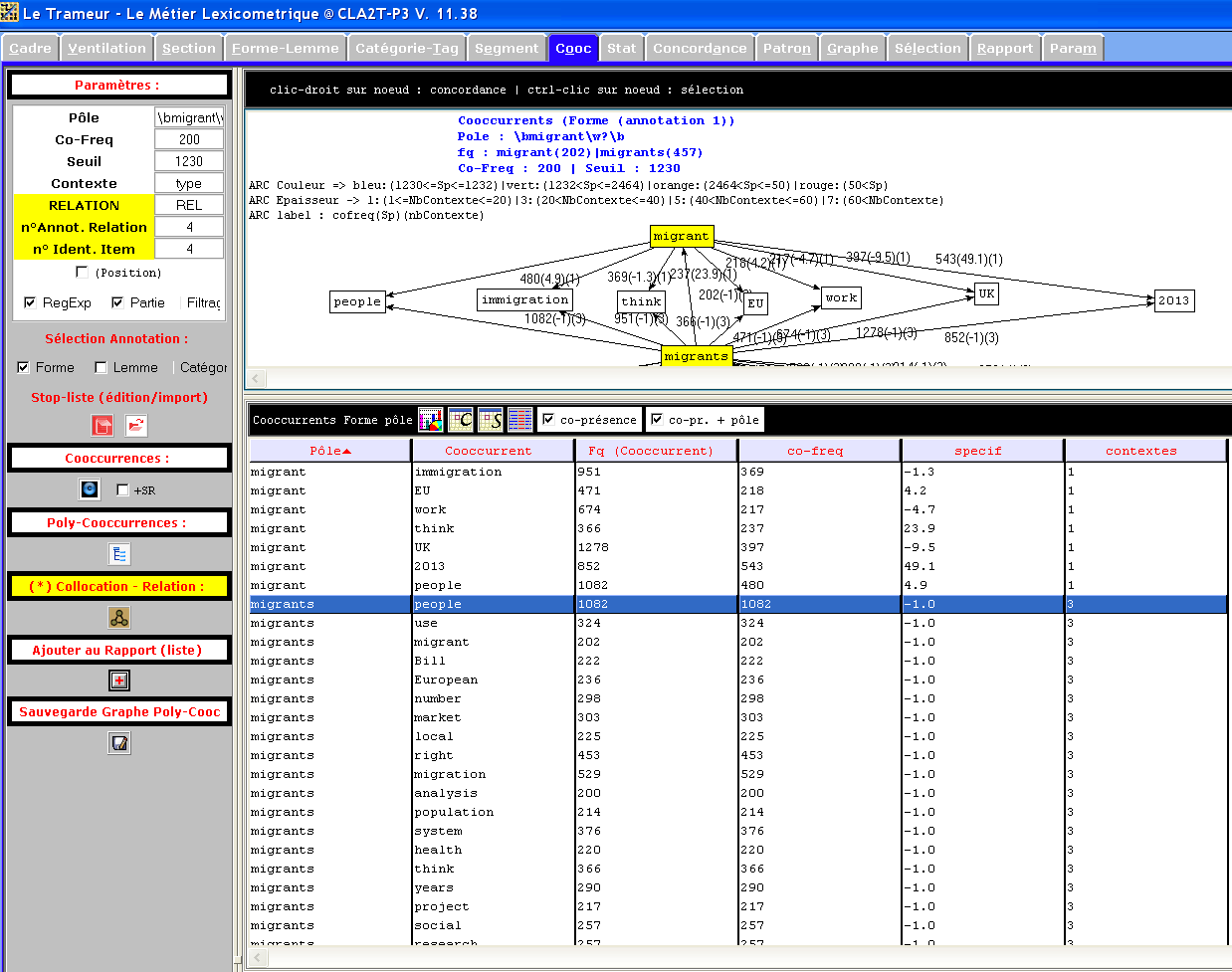
figure 3 :
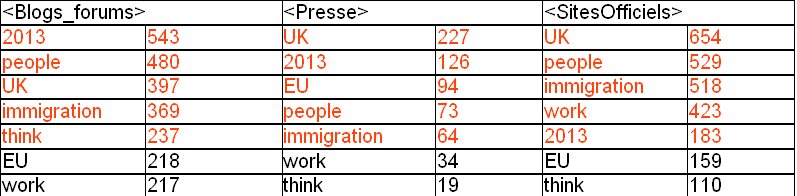
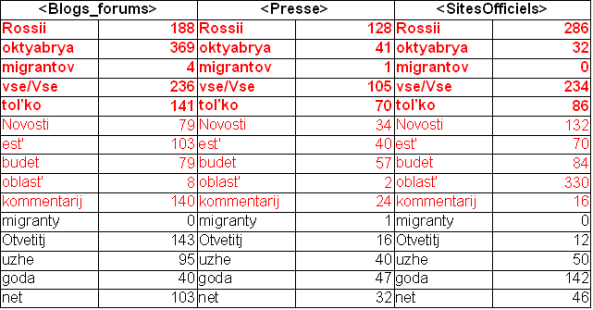
Ensuite, nous avons généré la ventilation des formes cooccurrentes sélectionnées pour donner la présentation graphique la plus lisible des formes cooccurrentes. Lors du chargement de la partie des formes cooccurrentes, nous avons dressé un tableau avec les fréquences par rapport au type de texte (tableau ci-dessous).
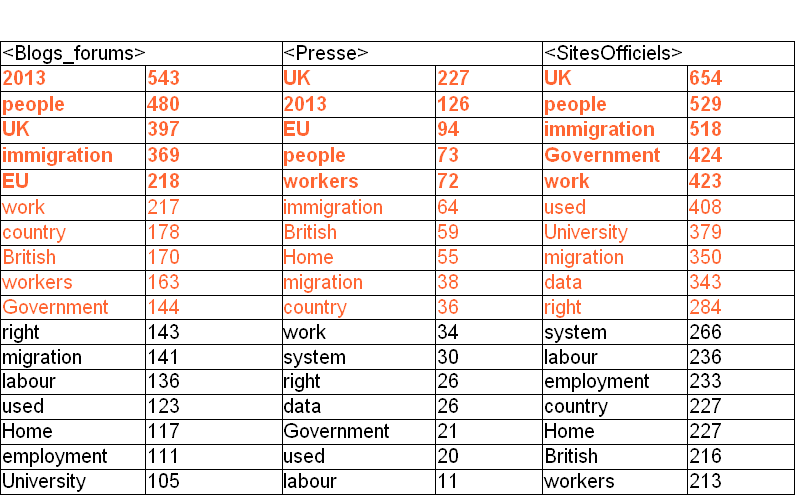
Dans le graphe ci-dessous, nous pouvons voir les cinq premières formes les plus fréquentes avec la forme "migrant(s)", par ordre décroissant:
- Sites officiels :UK, people, immigration, Government, work, used
- Blogs et Forums : 2013, people, UK, immigration, EU
- Sites de presse : UK, 2013, EU, people, workers, work
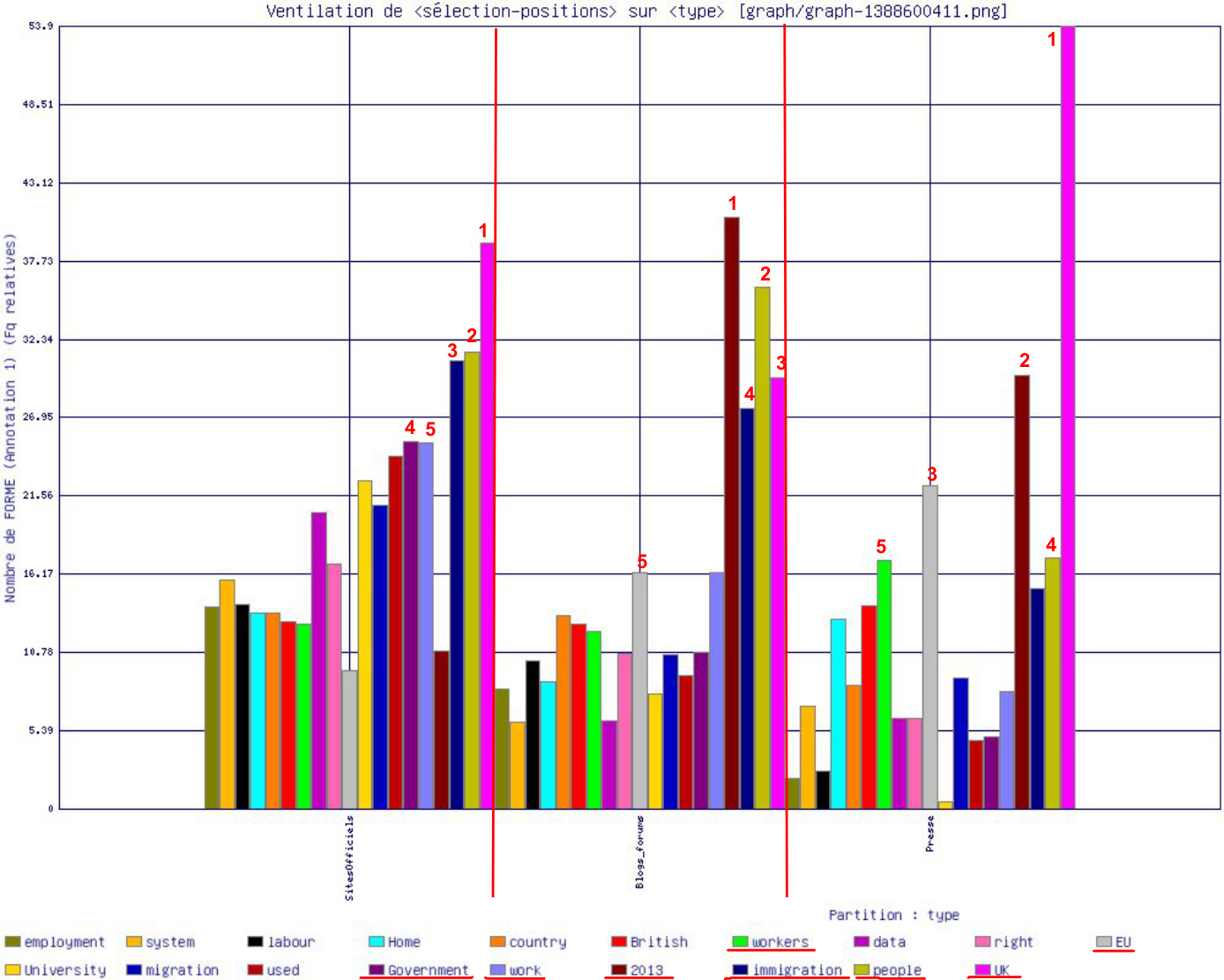
L’analyse montre que les trois sites de la Grande Bretagne étaient axés sur la notion de migrant comme faisant partie de l’état, et plus globalement, de l’Union Européenne. Toutes les formes représentant les mots sont au registre neutre, nous pouvons supposer qu’elles indiquent un phénomène que fait partie des affaires intérieures de la Grande Bretagne. Concernant la forme "migrant" (singulier), nous avons généré le graphe à part, car le nombre des mots cooccurrents était assez bas par rapport à celle de la forme "migrants" au pluriel (figure et tableau ci-dessous).
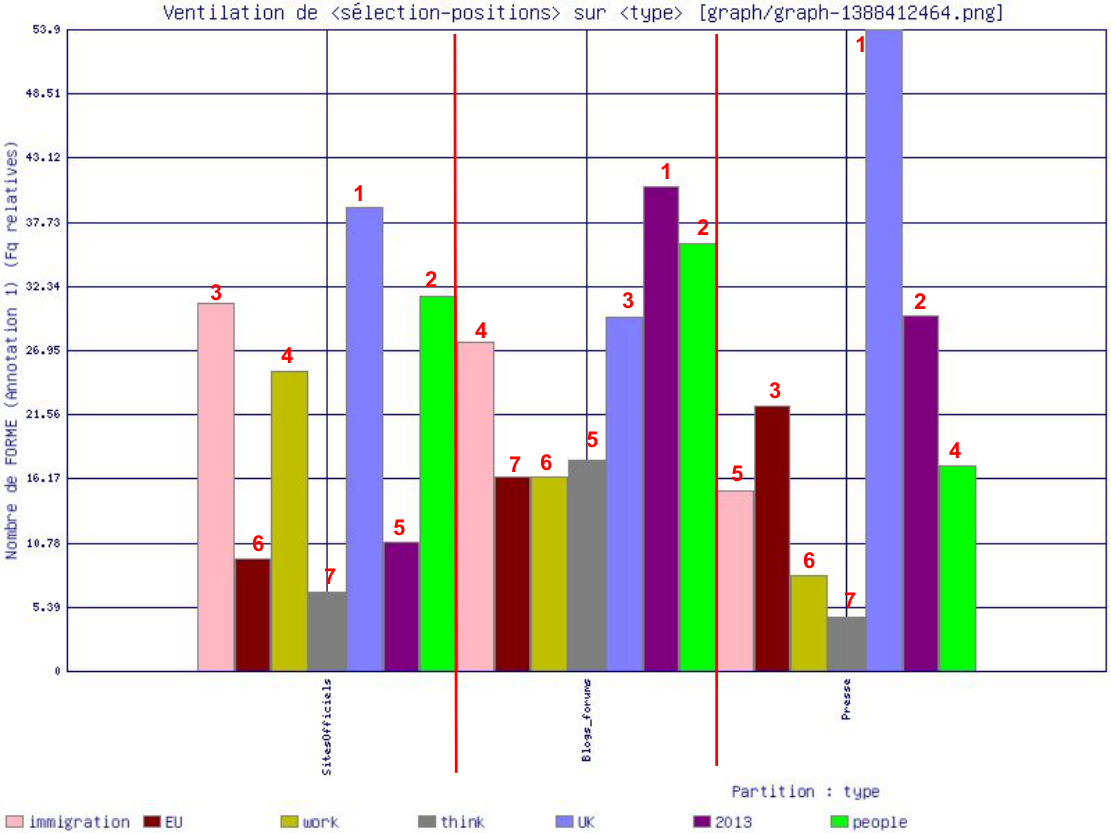
Section Segmentation :
Nous avons recherché les segments les plus répétés avec des adjectifs situés à gauche de la forme, afin de trouver des L1-collocates indiquées dans l’étude faite par l’Observatoire d’Immigration (voir Rapport 2010-2012) :

Nous avons ensuite relevé les contextes du segment migrants have afin de préciser le complément du verbe have :

Conclusions :
Nos résultats obtenus à l’aide du Trameur se diffèrent des résultats des nuages des mots. Les mots cooccurrents les plus fréquents avec la forme "migrant(s)" sont les noms UK, people, immigration, EU, Government, work, workers et le numéral 2013. Ils sont neutres dans leur registre et évoquent les notions de l’espace politique (UK, EU), des notions sociales (immigration, work, workers, Government), et générales (2013, people). Il faut aussi remarquer que "migrant" au singulier est beaucoup moins fréquent que sa forme correspondante au pluriel. Par ailleurs, notre analyse des segments montre que les sites d’opinion publique et de presse utilisent le plus couramment EU migrants alors que les sites officiels se réfèrent aux illegal migrants. La forme migrants have (suivi d’un verbe au participe passé (made, entered, left, abandoned) ou d'un nom (access)) sont présents dans tous les types de sites. Economic migrants et illegal migrants n’étaient pas utilisés dans les textes des sites de presse. A la fin, nous avons décidé d’éliminer le numéral 2013 des résultats des formes cooccurrentes, car les pages des sites datent de 2012– 2013, et sa fréquence ne dépend pas forcément des contextes contenant les formes "migrant(s)".
Analyse du français
L'expression régulière qui nous a servi pour relever les formes est \bmigrant\w?\b.
Section Forme-Lemme :
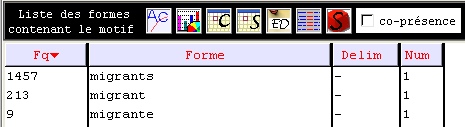
Nous avons généré une liste des formes contenant le motif :
Section Ventilation :
Fréquence absolue du motif : \bmigrant\w?\b
- Blogs_forums : 1422
- Presse : 146
- SitesOfficiels : 111
Fréquence relative du motif : \bmigrant\w?\b :
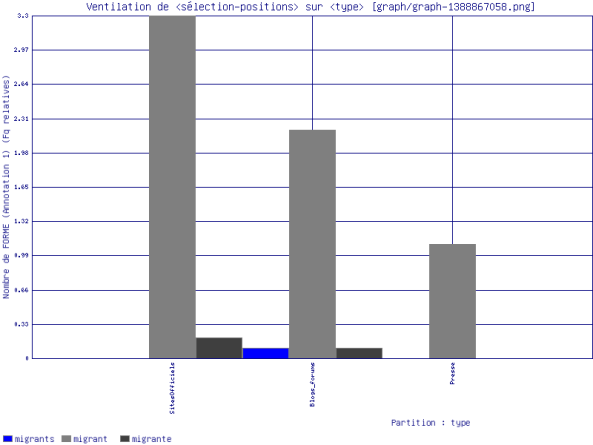
Sur la figure ci-dessus, nous voyons que notre motif apparaît plus fréquemment dans les sites officiels, puis dans les sites d'opinion publique, et en dernier, la presse. Nous constatons aisément que c'est le mot "migrant" au singulier qui ressort.
Section Co-ocurence :
Dans cette section nous avons généré les mots co-occurents avec les formes \bmigrant\w?\b les plus fréquentes : migrants, migrant. Nous avons rajouté le fichier stoplist.fr pour éviter les mots grammaticaux. Nous avons décidé de ne pas prendre en compte les formes des verbes être et avoir. Pour le pluriel,\bmigrants\b :
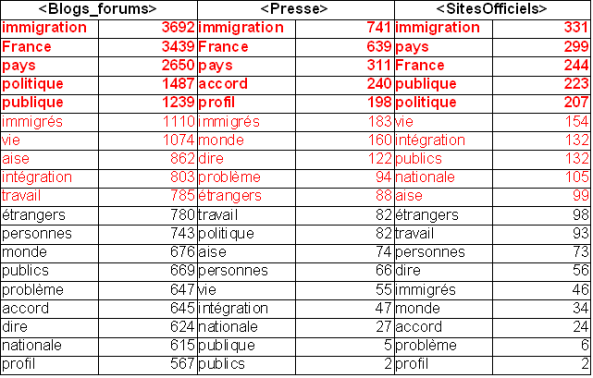
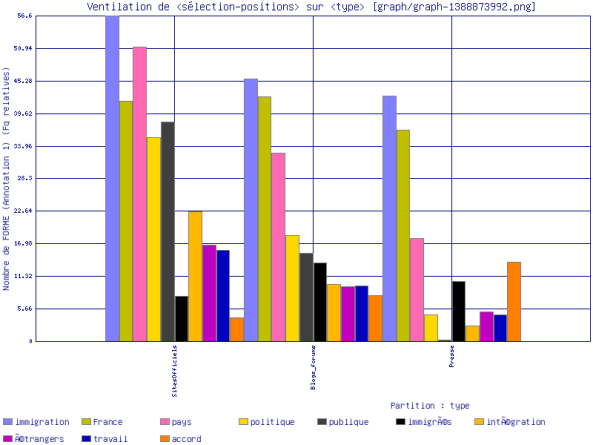
Nous voyons que les premiers cooccurents de notre motif au pluriel pour les sites officiels sont (du plus fréquent au moins fréquent) : "immigration, France, pays, intégration" et "politique". Pour les sites d'opinion publique, les premiers cooccurrents sont les suivants : "immigration, France, pays, intégration, politique". Concernant les sites de presse, les premiers cooccurrents sont les suivants : "immigration, pays, France, publique" et "politique". Le cooccurrent "publique" est beaucoup plus fréquent dans la presse que dans les autres types de sites.
Pour le singulier, \bmigrant\b :
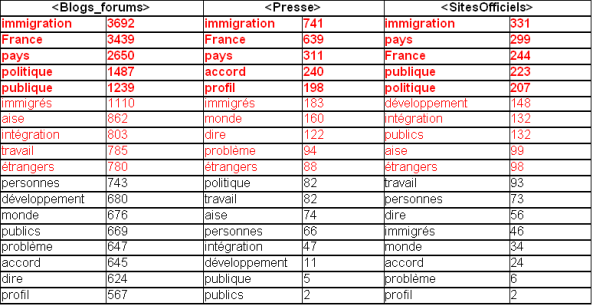
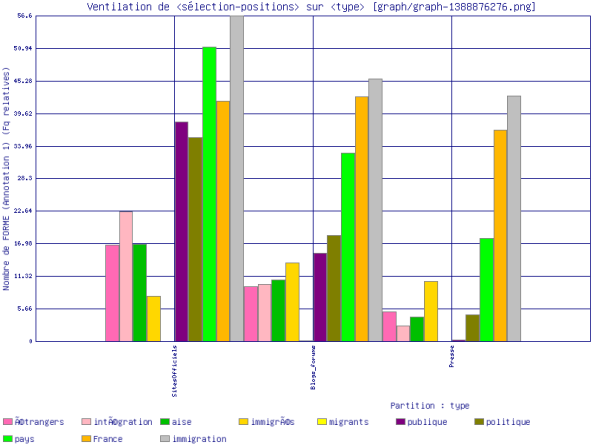
Concernant les sites officiels, les premiers cooccurents de notre motif au singulier sont : "immigration, pays, France, publique". ce dernier apparaîssait moins fréquemment avec le motif au pluriel. Pour les sites d'opinion publique, nous relevons : "immigration, France, pays, politique". Pour les sites de presse, nous remarquons : "immigration, pays, France publique et politique".
Section Segment :
Pour le pluriel, \bmigrants\b :

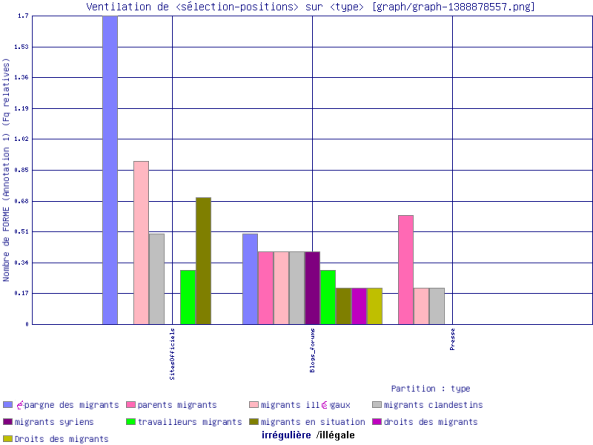
Les segments les plus courants sont les suivants:
- Blogs/forums : "épargne des migrants, droits des migrants, parents migrants, migrants syriens, migrants illégaux".
- Presse : "parents migrants, migrants clandestins, migrants illégaux".
- SitesOfficiels : "épargne des migrants, migrants illégaux, migrants clandestins, travailleurs migrants".
Pour le singulier, \bmigrant\b :

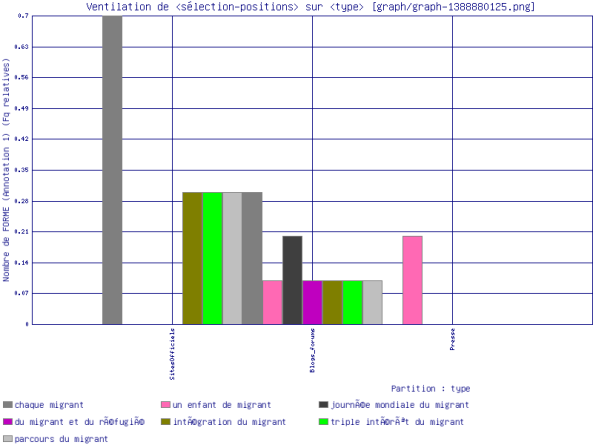
Les segments les plus courants sont les suivants:
- Blogs/forums : "chaque migrant, journée mondiale du migrant, du migrant et du réfugié, un enfant de migrant, intégration du migrant".
- Presse : "un enfant de migrant".
- SitesOfficiels : "chaque migrant, intégration du migrant, triple intérêt du migrant, parcours du migrant".
Conclusion :
Globalement, les cooccurrents les plus fréquents de notre motif (singulier ou pluriel) sont "immigration", "France", "pays", "publique", "politique", avec de petites variations de fréquences selon le type de site analysé. Les termes relevés relèvent du registre courant, dans un champ sémantique autour de la société. Contrairement aux nuages de mots où nous travaillions sur les contextes, les dump nous révèlent ici que le motif est plus fréquent au singulier. Avec le Trameur, les analyses du motif au pluriel et au singulier montrent des différences, notamment pour les segments : au pluriel, nous retrouvons "épargne des migrants" ou "parents de migrants"; au singulier, des termes différents tels que "chaque migrant", "un enfant de migrant" ou "intégration du migrant". Notons que quel que soit le type d'analyse, l'idée d'intégration revient très souvent dans la langue française.
Analyse du russe
L’expression régulière qui nous servira pour relever les formes est \bmigrant\w*\b. Etant donné que nous utilisions le corpus russe translittéré, nous avons remplacé tous les symboles " ‘ " par "j" pour éviter la confusion avec la détection des frontières des mots par le Trameur.
Section Forme-Lemme :
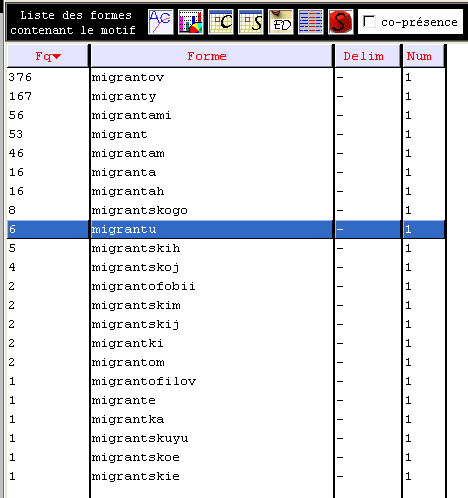
Nous avons généré une liste de formes contenant le motif :
Section Ventilation :
Fréquence absolue du motif \bmigrant\w*\b :
- Blogs_forums : 421
- Presse : 247
- SitesOfficiels : 202
Nous observons la fréquence absolue la plus élevée des formes \bmigrant\w*\b sur les sites d’opinion publique (blogs, forums). La fréquence la plus basse est celle des sites officiels (voir les chiffres ci-dessus).
Fréquence relative du motif \bmigrant\w*\b :
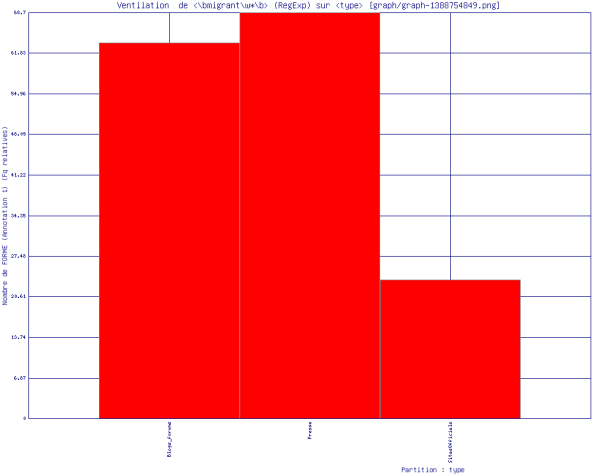
Concernant la fréquence relative du motif \bmigrant\w*\b, elle est de 63% environ pour les blogs et les forums, 68% pour la presse, et de 25,5% environ pour les sites officiels (voir figure ci-dessus).
Section Cooccurrence :
Dans cette section nous avons généré les mots co-occurrents avec les formes les plus fréquentes : "migrantov" (migrants =génitif), "migranty" (migrants = nominatif), "migrantami" (migrants =instrumentals).
Dans le tableau et le graphe ci-dessous, nous pouvons voir les cinq premières formes les plus co-fréquentes avec la forme \bmigrantov\b par ordre décroissant:
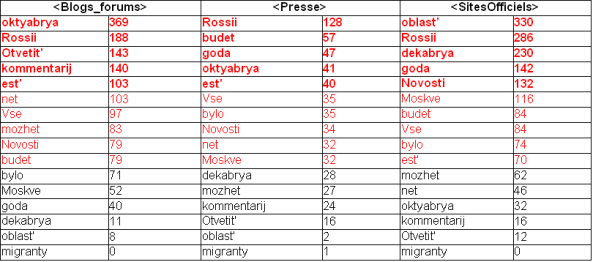
- Sites officiels : oblast’ (région), Rossii (Russie), dekabrya (décembre), goda (année), Novosti (des nouvelles).
- Blogs et Forums : oktyabrya (octobre), Rossii (Russie), Otvetit’ (répondre), kommentarij (commentaire), est’ (il, elle existe).
- Sites de presse : Rossii (Russie), budet (il, elle existera), goda (année), oktyabrya (octobre), est’ (il, elle, existe).
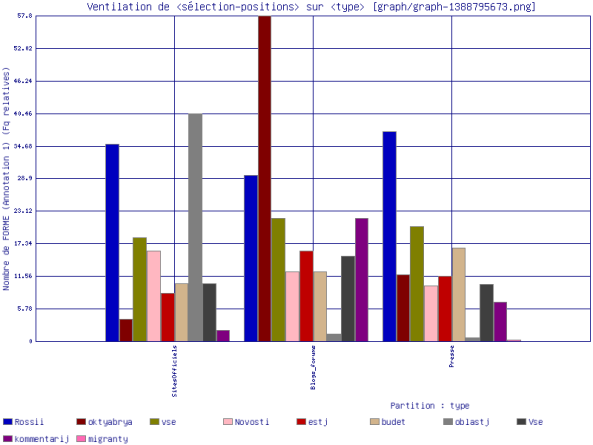
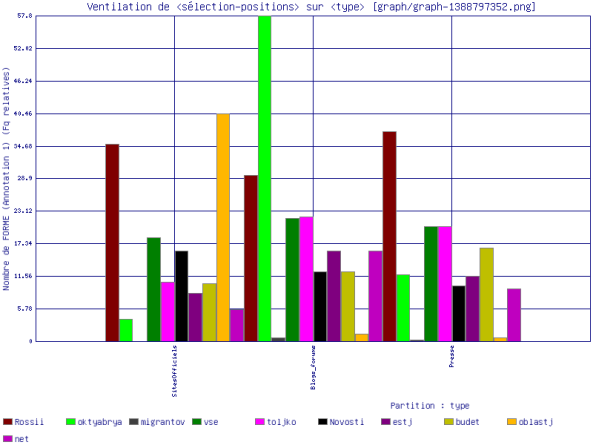
Dans le tableau et le graphe ci-dessous, nous pouvons voir les cinq premières formes les plus co-fréquentes avec la forme \bmigranty\b par ordre décroissant:
- Sites officiels : oblast’ (région), Rossii (Russie), vse/Vse (tout le monde), goda (année), Novosti (des nouvelles).
- Blogs et Forums : oktyabrya (octobre), vse/Vse (tout le monde), Rossii (Russie), Otvetit’ (répondre), toljko (seulement, uniquement).
- Sites de presse : Rossii (Russie), vse/Vse (tout le monde), toljko (seulement, uniquement), budet (il, elle existera), goda (année).
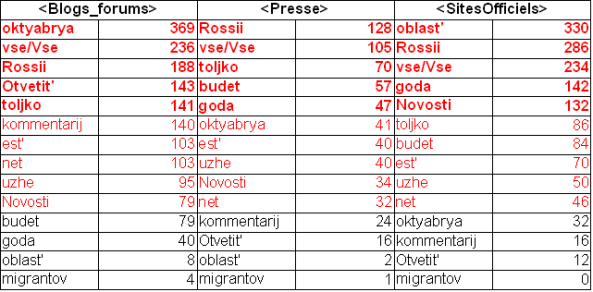
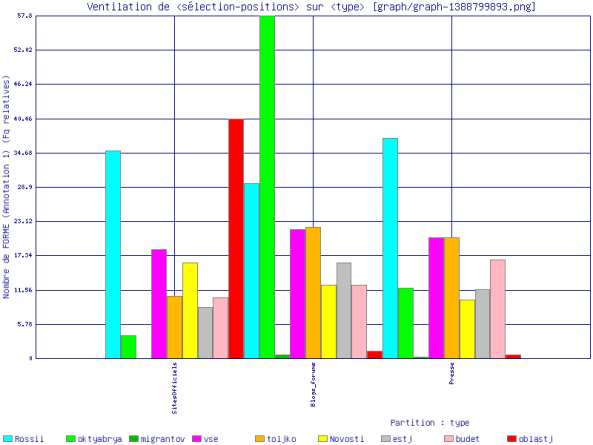
Dans le tableau et le graphe ci-dessous, nous pouvons voir les cinq premières formes les plus co-fréquentes avec la forme \bmigrantami\b :
- Sites officiels : oblast’ (région), Rossii (Russie), vse/Vse (tout le monde), goda (année), Novosti (des nouvelles).
- Blogs et Forums : oktyabrya (octobre), vse/Vse (tout le monde), Rossii (Russie), Otvetit’ (répondre), toljko (seulement, uniquement).
- Sites de presse : Rossii (Russie), vse/Vse (tout le monde), toljko (seulement, uniquement), budet (il, elle existera), goda (année).
Section Segmentation :
Nous avons recherché les segments les plus répétés avec des adjectives situés à gauche et à droite de la forme "migrantov" (voir figure ci-dessous). Il semble intéressant de souligner que les segments les plus fréquents situés à gauche de la forme "migrantov" (migrants) sont : nelegaljnyh (illégaux), trudovyh (actifs), skoljko (combien) (voir figure ci-dessous).
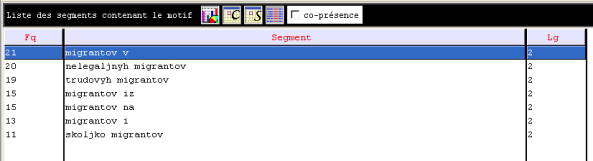
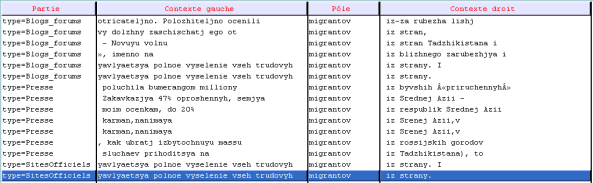
En ce qui concerne les contextes situés à droite de la forme "migrantov" + préposition iz (depuis, en provenance de), nous pouvons citer : migrantov iz blizhnego zarubezhjya (migrants en provenance des pays limitrophes), migrantov iz Tadzhikistana (migrants en provenance de Tadzhikistan), migrantov iz Srednej Azii (migrants en provenance d’Asie centrale).
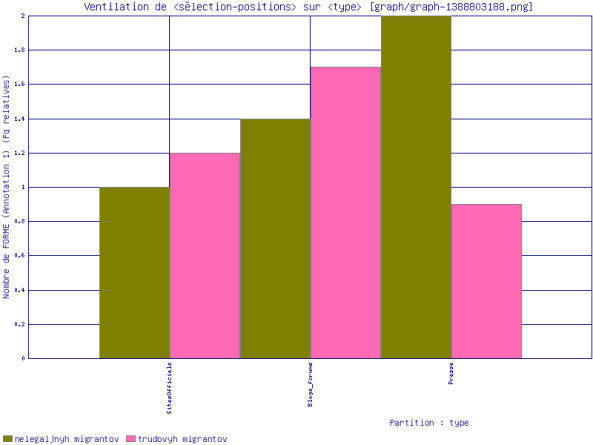
La figure ci-dessus nous montre les fréquences relatives d’apparition des segments trudovyh migrantov (migrants actifs) et nelegaljnyh migrantov (migrants illégaux) au sein de chaque corpus étudié. Nous voyons que : 1) dans les sites officiels et sur les blogs la cooccurrence de deux segments "migrants actifs" est plus fréquente que celle de "migrants illégaux". 2) dans la presse, nous observons la tendance inverse.
Conclusion
Nous avons vu que les formes les plus fréquentes contenant le motif \bmigrant\w*\b sont migrantov (=génitif), migranty (=nominatif), migrantami (instrumental). Ces résultats correspondent à ceux obtenus à l’aide des nuages. La liste des mots co-occurrents avec les formes les plus fréquentes ne semble pas être particulièrement intéressante. Il s’agit des mots neutres : "Russie, région, année, répondre, nouvelles, exister"… Ces résultats diffèrent de ceux obtenus avec les nuages où les mots cooccurrents avec le mot "migrant" relevaient des champs sémantiques tels que : "travail, droit, politique, législation, intégration, criminalité". Par ailleurs, notre analyse des segments montre que les sites d’opinion publique et les sites officiels utilisent le plus couramment le mot "migrants actifs" alors que la presse réfèrent aux "migrants illégaux" (voir dernière figure). En conclusion générale, rappelons que nos trois langues fonctionnant différemment, nous ne les avons pas traitées de la même manière. Cependant, nous pouvons dire que nous remarquons une différence entre le russe et les deux autres langues. Concernant les cooccurrences par exemple, les champs sémantiques du russe sont plus globaux (uniquement, tout le monde,...), alors que nous rencontrons des termes beaucoup plus politiques du côté français et anglais. En effet, nous rencontrons chez ces deux dernières langues des termes tels que "immigration, gouvernement, ou politique. Ainsi, la notion de société et de politique est plus présente.