

Le choix du terme a été fait en prenant en compte certaines limitations que l'on pourrait trouver lors de l’exécution de nos taches.
Dans ce sens, nous voulions choisir un terme qui nous permettait d'optimiser les résultats qualitatifs et quantitatifs, malgré les possibles limitations des ressources matérielles et intellectuelles dont nous disposions.
Nous avons donc fini par conclure qu'il fallait choisir un terme qui soit plus au moins à la une, et dont le domaine d'utilisation soit très étendu. Tout cela nous permettrait de vérifier que notre terme apparaisse dans des situations diverses. En outre, il fallait ne pas oublier que ce même terme serait traduit et utilisé pour faire la même recherche dans d'autres langues (ce qui implique aussi le choix des bonnes traductions, etc).
C'est pour toutes ces raisons que nous avons choisi le terme "mariage homosexuel" pour notre étude.
Notre projet compte trois langues différentes : l'anglais, le portugais et le français. Mais pour valoriser ce choix et mieux exploiter toutes les possibles différences sociales et culturelles concernant le sujet du mariage homosexuel, nous avons décidé d'élargir la liste d'URL à récolter pour notre projet en incluant différents pays où le français, le portugais et l'anglais sont parlés.
Une fois la liste élargie, la probabilité de trouver des problèmes a augmenté. Par exemple, parmi les difficultés rencontrées, on peut citer l'impossibilité de trouver des sites pour un pays choisi. Cela a été le cas du Timor Oriental, l'un des pays de langue portugaise que nous avions initialement choisi pour le projet.
Malheureusement, nous n'avons pas réussi à trouver des sites timorais à inclure dans le projet. Les seuls sites que nous avons trouvé avec le domaine .tl étaient les sites officiels et un blog d’actualités. D'ailleurs ce n'est pas le simple fait que le site aie le domaine .tl qui pourrait nous assurer qu'il contienne des infos sur le Timor Oriental. Nous avons essayé de chercher des journaux, des portails d'actualités, sans obtenir aucun résultat.
Enfin, cela a servi à nous montrer que le monde n'est pas totalement "connecté".
Vu ces difficultés, nous avons décidé de poursuivre le projet en utilisant la liste de pays suivante :
Pour ces pays nous n'avons pas eu de problèmes à trouver des sites sur le sujet.
La recherche des sites a été partiellement automatisée. Le système d'alerte de Google nous a permis de trouver certains sites automatiquement. Pour les autres, nous avons utilisé les moteurs de recherche Google et Bing, ainsi que les systèmes de recherche proposés par certains sites. En revanche le tri des sites a été fait majoritairement à la main.
Comme il s'agit d'une recherche linguistique diachronique, notre travail a été restreint aux sites d'actualités. Le choix de ces sites influence le résultat de notre travail. S'agissant d'une recherche linguistique, ce choix équivaut plus ou moins à déterminer le genre textuel sur lequel on veut travailler. Dans notre cas, on a choisi travailler sur des textes de la presse, des blogs et certains sites officiels (sites des gouvernement, des ministère, etc).
Cette variabilité des genres textuels a pour but d'optimiser les résultats.
Peut-être que notre code peut vous paraître un peu complexe au premier regard. Mais nous allons essayer d'expliquer les fonctionnalités qui justifient nos choix lors de sa construction.
Le programme a été écrit en bash. Le bash - ainsi que d'autres langages de programmation comme Perl, C++, Java, etc. - dispose de fonctions prêtes à être utilisées. Cela nous permet par exemple de réaliser des traitements textuels, effectuer des calculs ou même réaliser des opérations plus complexes, comme changer notre système d'exploitation de configurations.
Cependant, malgré la variété des fonctions existantes en bash, nos besoins sont parfois plus spécifiques et nous sommes obligés de créer les fonctions qui répondent à nos exigences.
Dans notre code vous allez trouver trois fonctions. Ces fonctions évitent la répétition d'un morceau du programme et facilitent l'entretien du code. Faciliter l'entretien du code a été très utile au long de ce projet, car il s'agissait d'un programme qui n'a pas cessé d'évoluer au long des quatre mois. De plus, il était entretenu par deux personnes différentes.
Au début du cours quand il s'agissait juste de télécharger des sites et créer un dump à partir des fichers .html, la tache était plus simple. Mais lorsque nous avons dû classer les sites selon leur encodage, exécuter un script en Perl pour créer de beaux contextes en html, compter les occurrences du terme motif, générer un tableau HTML contenant toute ces informations, etc., nous avons été obligés de construire un code plus robuste.
Pour mieux suivre les évolutions du code et maintenir le projet organisé, nous avons créé plusieurs dossiers où nous avons enregistré les différentes versions de notre script au fur et à mesure que celui ci se complexifiait.
Un autre point à remarquer sur notre code et ses fonctions est que nous avons essayé de séparer les différentes opérations à effectuer. C'est-à-dire, la construction du tableau HTML et les traitements textuels.
Cela a été extrêmement avantageux, surtout à la fin du projet lorsque nous avons voulu changer le code HTML pour inclure des codes CSS, en vue d'améliorer la présentation de notre tableau de résultats. Comme la création de toutes les lignes du tableau est faite en appelant la même fonction create_table_line(), nous avons dû changer un seul morceau du code pour réaliser tous ces changements.
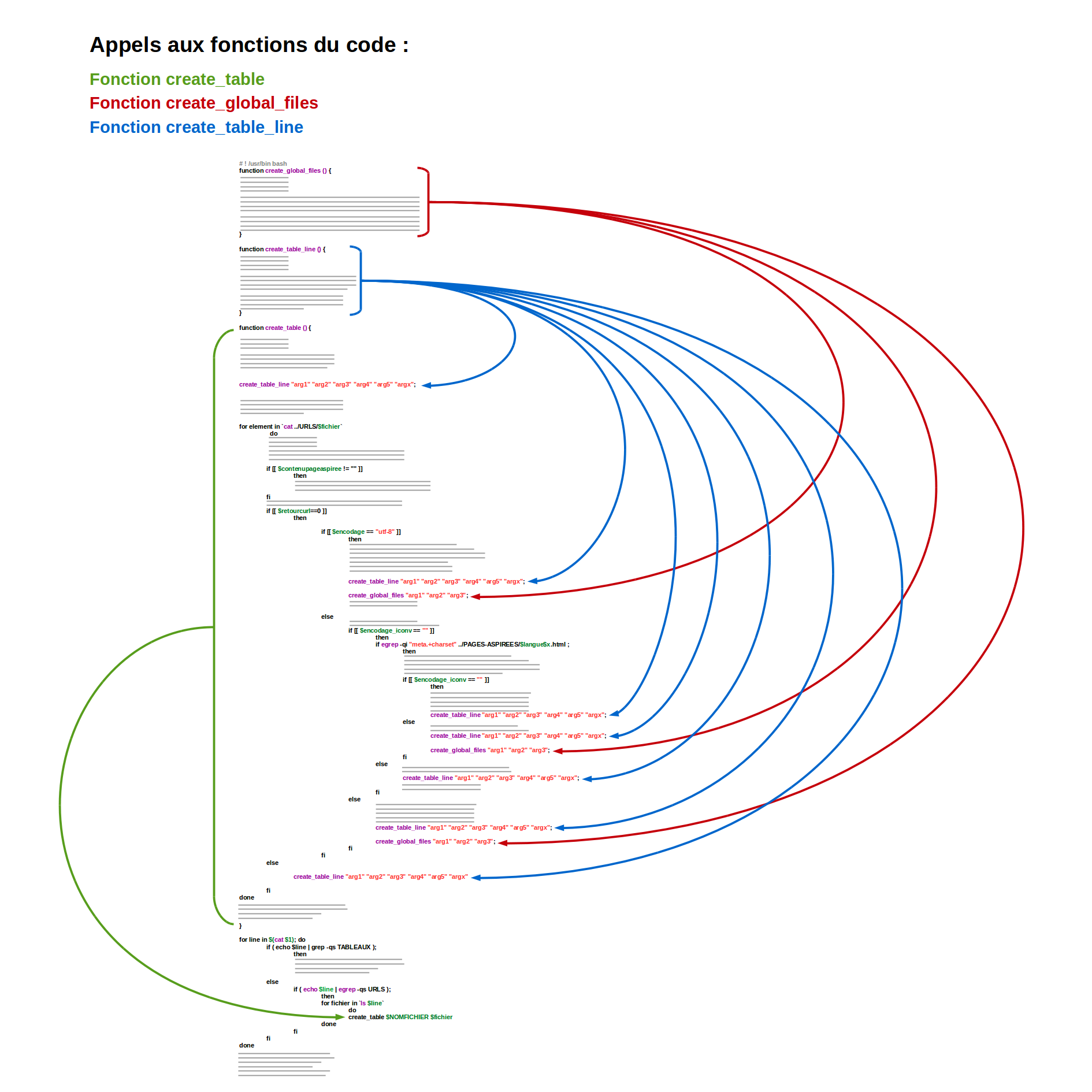
Comme nous pouvons voir dans le diagramme ci-dessus notre script se déroule dans l'ordre suivant :
Le Trameur est un outil d'analyse textométrique que nous avons utilisé pour interpreter les résultats de tous les tableaux que notre script a généré. Vous pouvez trouver plus d'informations sur cette partie de notre anayse dans l'onglet "Trameur".
Nous avons créé des nuages de mots avec le programme WordItOut pour visualiser nos résultats. Ce programme prend un texte en entrée et fait des regroupements de mots individus de ce texte. Nous avons fait un nuage de mots avec nos fichiers de "contexte global" (celui qui contient notre terme et ses contextes dans tous les sites differents pour une même langue) pour chaque pays (deux nuages par langue).