Objectif : extraction de texte
A partir de l'ensemble des fils RSS du journal Le Monde, nous voulons extraire uniquement le titre et le résumé de chaque article. Avec les données extraites, nous allons construire deux fichiers, l'un en texte brut et l'autre en texte balisé en XML. L'extraction est réalisée automatiquement par un script Perl présenté ci-dessous.Le corpus
Les fils RSS sont des fichiers respectant la norme de balisage XML. Pour chaque jour de l'année, nous avons une série de fichiers XML (un fichier par rubrique du journal : Société, Environnement, Politique...) ; chaque fichier contient une série d'items correspondant aux articles ; un item est composé de plusieurs éléments : titre, description, lien, date de publication... Un exemple d'item est donné ci-dessous :
Les balises dont nous voulons extraire le contenu sont <title> et <description>.
Le script
Deux méthodes d'extraction sont proposées : l'une avec des expressions régulières pour repérer les balises <title> et <description>, l'autre qui utilise un module Perl nommé XML::RSS ; ce module est fait pour naviguer dans un document XML de type "fil RSS". La démarche générale du script est la même, la seule différence est la méthode de repérage des balises recherchées.Méthode générale
Le script final est disponible ici.
Après avoir créé un répertoire de sortie et initialisé les variables de sortie qui vont être incrémentées par la suite, on fait appel à une première procédure. Celle-ci permet de repérer toutes les rubriques présentes dans le corpus. Elle parcourt de façon récursive l'arborescence du répertoire de fichiers, repère les fichiers XML qui nous intéressent, en extrait l'encodage. Si un encodage est effectivement détecté, on traite ledit fichier c'est-à-dire qu'on extrait le titre du "canal" (le sous-élément <title> de l'élément <channel>). Une fois le contenu de la balise extrait, on le nettoie pour avoir un simple nom de rubrique (Cinéma, Société, Politique, etc), et on le stocke dans la table de hashage qui contiendra tous les noms de rubriques.
Pour chaque rubrique, on va ensuite créer deux fichiers de sortie : un fichier texte et un fichier XML. C'est dans ces fichiers qu'on collera le contenu des balises <title> et <description>.
On va ensuite faire appel à la procédure centrale qui parcours l'arborescence de fichiers et extrait le contenu des balises <title> et <description>. Comme pour repérer les rubriques, on parcourt récursivement l'aborescence de répertoires, on repère les fichiers qui nous intéressent, et on en extrait l'encodage. S'il y en a un, on va traiter le fichier. On commence par repérer à nouveau la rubrique du fichier XML, pour savoir dans quel fichier on va diriger le flux de sortie : on ouvre ledit fichier.
On procède alors à l'extraction du contenu des balises <title> et <description>, soit avec la méthode des expressions régulières, soit avec celle du module XML::RSS, expliquées dans les parties ci-dessous.
On prendra soin d'appliquer une autre procédure à l'intérieure de la précédente : une procédure de nettoyage du texte extrait, mise en oeuvre avant de rediriger le flux de sortie vers les deux fichiers de sortie.
Variante avec expressions régulières
L'extrait de code Perl ci-dessous repère les balises titre et description et en extrait le contenu textuel vers des variables de stockage. Ces balises sont repérées grâce à une expression régulière ciblant un motif.
Cette méthode est cependant assez rigide. On lui préférera la variante avec le module XML::RSS.
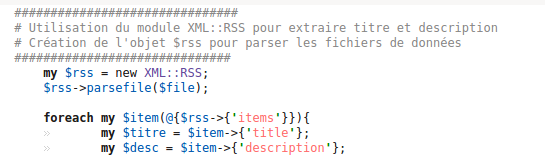
Variante avec le module XML::RSS
L'extrait de code Perl suivant permet de faire appel au module XML::RSS. Le module parse le fil RSS et en repère automatiquement les balises. Nous n'avons plus qu'à récupérer les balises <title> et <description>.