Objectif : étiquetage morpho-syntaxique
Cette étape consiste à appliquer un étiquetage morpho-syntaxique aux fichiers créés précédemment :- Les fichiers textes codés en ISO-Latin1 seront étiquetés par le logiciel Cordial
- Les fichiers XML codés en UTF-8 seront étiquetés avec TreeTagger.
Avec Cordial
Cordial ne fonctionne pas en ligne de commande, il faut passer par une interface graphique sous Windows, en conséquence, cette étape n'est pas automatisable. Comme nous avons choisi de travailler par rubrique, nous avons dû charger et étiqueter chaque fichier texte afin d'obtenir des fichiers tabulaires de type csv. Une sortie Cordial (rubrique "Economie") ressemble à ceci :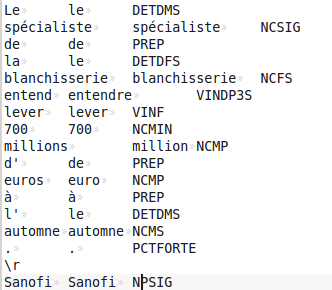
Voici un exemple de fichier obtenu pour la rubrique "Economie" : fichier étiqueté par Cordial.
On a dans l'ordre : le terme original, son lemme et son étiquette, dans trois colonnes séparées par des tabulations. On observe que la reconnaissance des noms propres et des entités nommées n'est pas parfaite ; par contre, l'étiquetage inclut genre, nombre et temps des verbes.
Avec TreeTagger
TreeTagger est un étiqueteur morpho-syntaxique développé à l'université de Stuttgart. Nous l'avons utilisé sur les fichiers produits au format XML et encodés en UTF-8. Il est téléchargeable librement et s'utilise en ligne de commande : nous pouvons donc l'intégrer à une chaîne de traitement. Trois étapes de traitement ont été appliquées à chaque fichier (un par rubrique) extrait :- Tokenisation : avec l'outil de Paris 3 tokenise-utf8.pl
- Etiquetage avec TreeTagger
- Ecriture du résultat dans un fichier au format XML grâce au programme de Paris3 treetagger2xml.pl. Une sortie tokenisation => TreeTagger => treetagger2xml (rubrique "Technologies") ressemble à ceci :
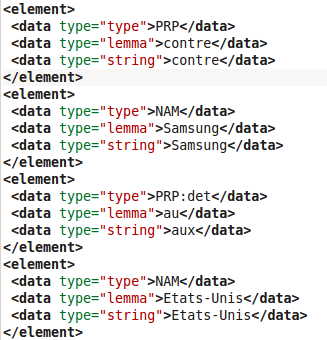
Voici un exemple de fichier obtenu pour la rubrique "Cinéma" : fichier étiqueté par TreeTagger.
Manuel ou auto ?
Comme TreeTagger et ses acolytes tokenise et treetagger2xml se lancent en ligne de commande, il semblait rapide et naturel de les intégrer au script d'extraction et d'étiquetage pour obtenir un traitement automatisé du corpus. Le script principal étant en perl, il suffit d'utiliser la commande "system" pour lancer une commande bash depuis l'intérieur du script. Avant de nous lancer dans la modification d'un script qui fonctionne, nous décidons d'écrire et de tester juste la suite de commandes nécessaire, sur un seul des fichiers extraits. Nous lançons donc :Test_Tree_Tag
Trois petites lignes pas si simples à mettre au point, mais très efficaces et rapides.
Encouragées par ce succès, nous "emballons" ces instructions dans un mini-script Perl qui a l'avantage de parcourir la liste des fichiers de chaque rubrique et de donner automatiquement un nom différent à chacun. Il s'agit de notre modeste Trait_Tree_Tag. Bluffant : sur un PC d'entrée de gamme où le système Ubuntu est configuré à la va-comme-je-te-pousse, tous les fichiers du corpus 2014 sont tokenisés, étiquetés et ré-écrits en xml en une vingtaine de minutes! En échangeant avec nos camarades, nous apprenons que pour la plupart d'entre eux, l'intégration de la chaîne des traitements a produit un script dont l'exécution prend de 10 à 18 heures...Notre choix est donc de ne pas tenter d'écrire un tel script, qui ne nous semble pas justifié en terme d'efficacité au regard de nos résultats.