Boîte à outils 2
La boîte à outils 1 a permis de générer deux sorties textuelles (XML et TXT). Désormais, les données des fichiers RSS sont nettoyées et regroupées par rubrique. Cette deuxième boîte à outils (BOA2) a pour fonction de reprendre le parcours de la BOA1 et de segmenter le contenu textuel en tokens, pour enfin étiqueter morpho-syntaxiquement chaque mot. Pour cela, on va utiliser deux programmes différents: Cordial et Treetagger. Treetagger génère un fichier XML incluant l'analyse structurée selon nos critères. Quant à Cordial, il génère l'étiquetage avec la même structure d'analyse en format CNR propre au logiciel.
Cordial
Cordial est un logiciel qui permet de corriger et analyser les données textuelles. Certaines contraintes spécifiques à son fonctionnement obligent que le format des fichiers en entrée soit ISO-8859-1 plutôt que UTF-8. Notons que Cordial doit prendre en entrée nos fichiers textes au format ".txt", c'est donc pour cette raison que ces derniers ont été encodés au format ISO-8859-1. Rappelons aussi que ce logiciel ne supporte pas des fichiers de tailles importantes, c'est ainsi que la répartition de nos sorties en rubriques à servi à assurer que nos fichiers en entrée ne soient pas trop volumineux.• Pour changer l'encodage de nos fichiers, nous avons utilisé ce site-web. Il suffit de télécharger les fichiers et de choisir l'encodage voulu.
• Pour utiliser le logiciel, il faut ouvrir le fichier texte à étiqueter et sélectionner syntaxique --> étiquetage. Les paramètres qu'il faut choisir sont les suivants:
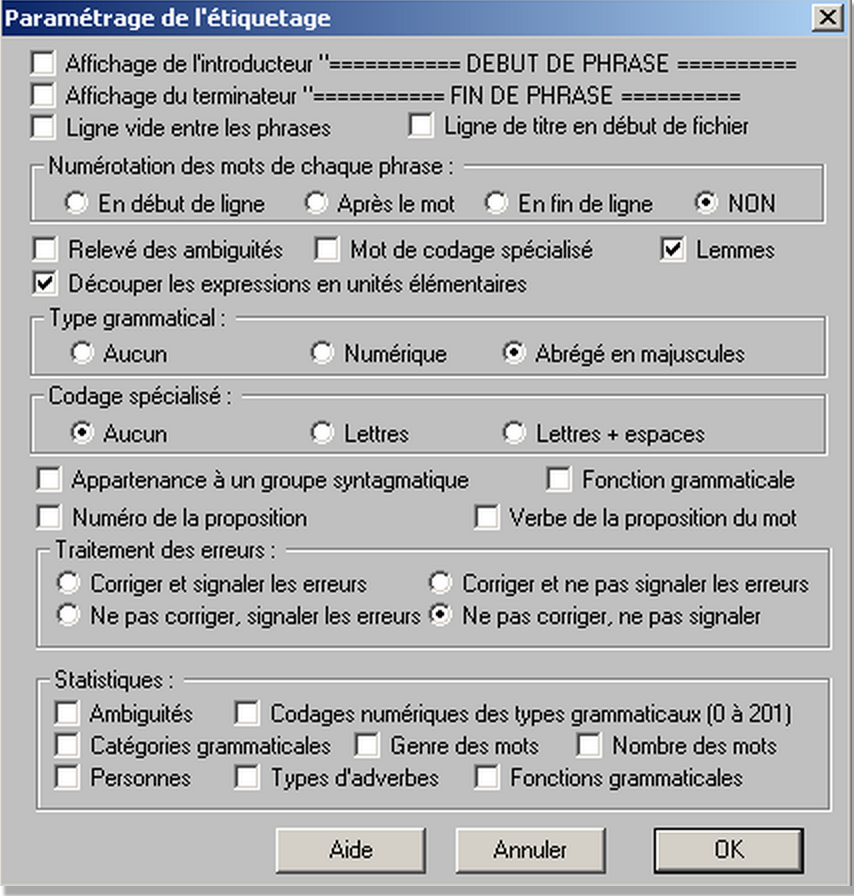
La tâche d'étiquetage se fait manuellement, il faut répéter l'opération pour chaque fichier. Les sorties sont au format ".cnr". Voici un example de sortie pour la rubrique "Cinema":
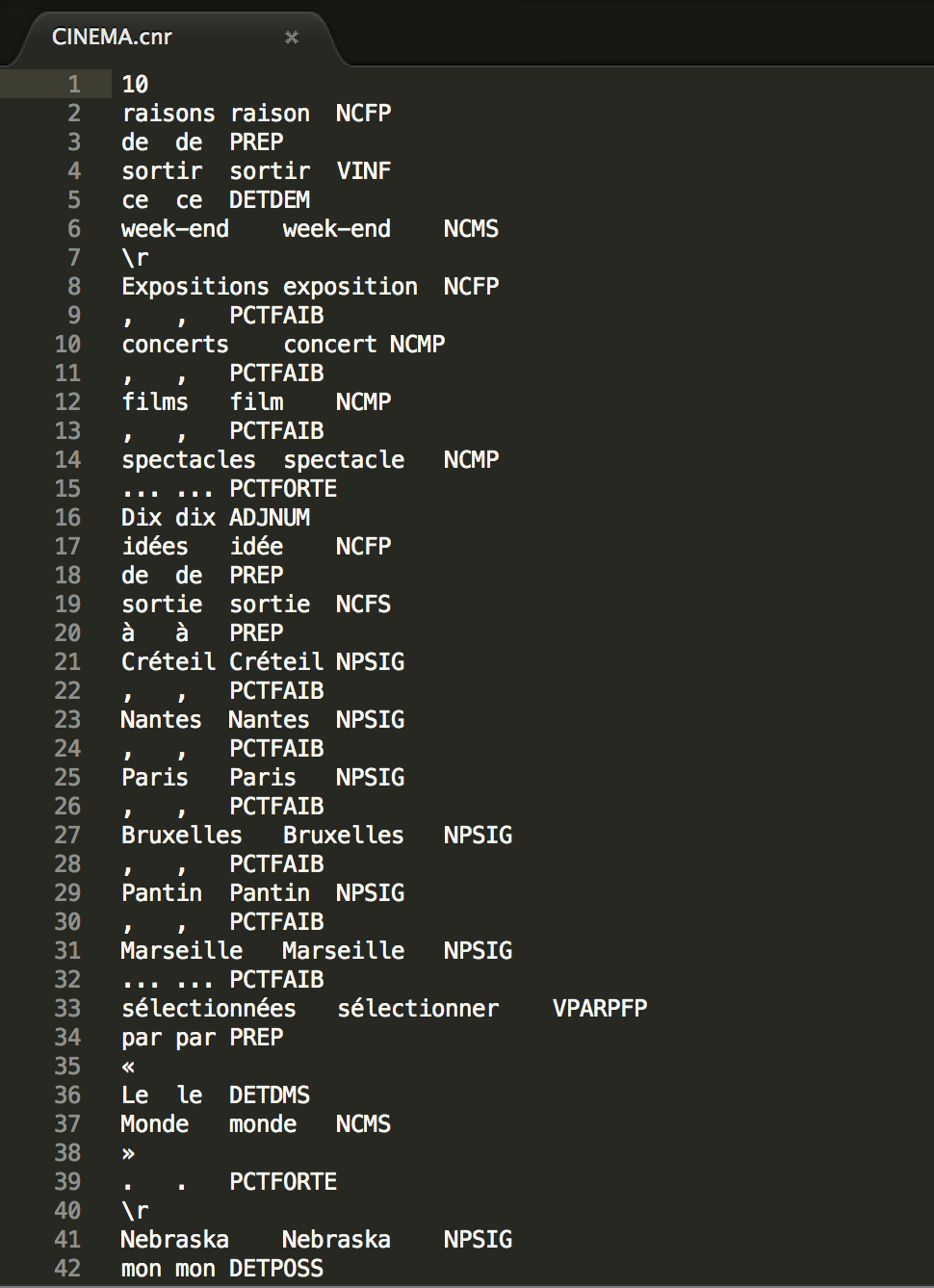
On peut voir que dans les étiquetages de Cordial, il y a 3 colonnes: la première contient la liste des tokens, la seconde leur lemme et la dernière leur étiquette morphosyntaxique, incluant la catégorie grammaticale, le nombre, le genre, et la personne pour les verbes.
Veuillez telecharger ici un examplaire de resultat pour la rubrique Idées
Treetagger
Treetagger est plus pratique que Cordial car il peut être utilisé en ligne de commande, donc il est possible d'intégrer l'étiquetage du corpus dans le programme du BAO1. C'est un programme de lemmatisation qui réalise aussi de la "tokenisation". La syntaxe de treetagger en ligne de commande est la suivante:
treetagger.exe [options]
Pour étiqueter les textes, il faut segmenter en utilisant le programme tokanise-fr.pl :
perl tokenise-fr.pl fichier.txt > fichier_segmente.txt
Par la suite, il faut etiqueter le fichier segmenté dans l'ordre:
tree-tagger[fichier lib] [options] [fichier segmenté]:tree-tagger french-utf8.par -lemma -token -no-unknown -sgml fichier_segmente.txt > fichier_etiquete.txt
TreeTagger peut prendre plusieurs options, l'option "-lemma" permet d'afficher le lemme en sortie, l'option "-token" permet d'afficher les tokens, et "sgml" est utilisé pour ne pas traiter les balises.
Pour étiquetter nos textes, on a ajouté dans BAO1 le code suivant:
sub etiquetage { my $texte=shift; my $temp="fichier_temp.txt"; open(TEMP, ">:encoding(utf-8)", $temp); # fichier temporaire pour stocker le texte print TEMP $texte; close(TEMP); system("perl tokenise-utf8.pl $temp | tree-tagger.exe french-utf8.par -lemma -token -no-unknown -sgml > $reper-etiquetage.txt"); # treetagger2xml system("perl treetagger2xml.pl $reper-etiquetage.txt"); open(TaggedOUT,"<:encoding(utf-8)","$reper-etiquetage.txt.xml"); my $texte_tag=""; while (my $ligne=<TaggedOUT>) { $texte_tag.=$ligne; } close(TaggedOut); return $texte_tag; }
Avec TreeTagger, nous avons des sorties XML. Voici la sortie pour la rubrique “international”:
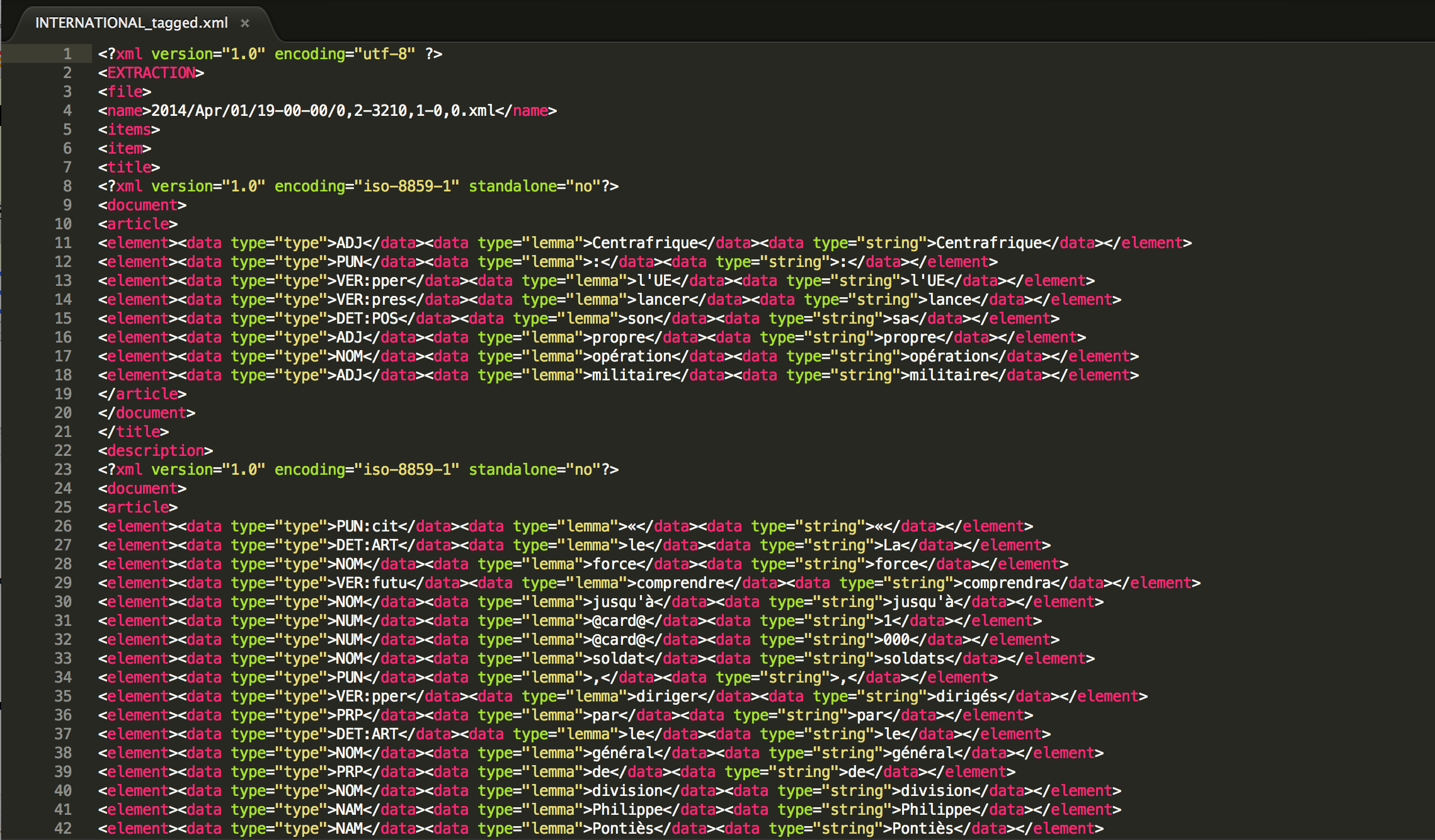
Dans les résultats de BAO2, le dossier BAO1 contient pour chaque rubrique sa version texte brut et xml, tandis que BAO2 contient les fichiers xml produits par le programme Treetagger. Une fois nos fichiers étiquetés, nous pouvons passer désormais à l'étape suivante: la recherche de motifs syntaxiques!
Vous pouver télécharger ici le script complet
Vous trouvez aussi ici un exemplaire de résultat pour la rubrique CULTURE