Boîte à outils 3
Grâce à la BOA2 nous possédons désormais des fichiers étiquetés syntaxiquement. Dans cette BAO3, nous allons extraire les patrons syntaxiques générés par la BOA2. Rappelons qu'Il y a deux types de sortie de la BAO2:
- Des sorties TXT (générées à l'aide de Cordial) possédant 3 colonnes.
- Des sorties XML (générées à l'aider de Treetagger) contenant 3 balises données par mot.
Les patrons syntaxiques qu'on cherche sont les suivants:
- NOM ADJ
- NOM PREP NOM
Nous possedons deux scripts: le premier pour les patrons NOM ADJ et le deuxième pour les patrons NOM PREP NOM.
Ci-dessous le script détectant les patrons NOM ADJ :
my @lignes=<FILE>; close(FILE); while (@lignes) { my $ligne=shift(@lignes); chomp $ligne; my $sequence=""; my $output1="SORTIE/SORTIE-extract-txt-".$sequence."txt"."\n"; my $longueur=0; if ( $ligne =~ /^([^\t]+)\t[^\t]+\tNC.*/) { my $forme=$1; $sequence.=$forme; $longueur=1; my $nextligne=$lignes[0]; if ( $nextligne =~ /^([^\t]+)\t[^\t]+\tADJ.*/) { my $forme=$1; $sequence.=" ".$forme; $longueur=2; } } if ($longueur == 2) { print $sequence,"\n"; } }
Voici quelques resultats pour la rubrique "Europe":
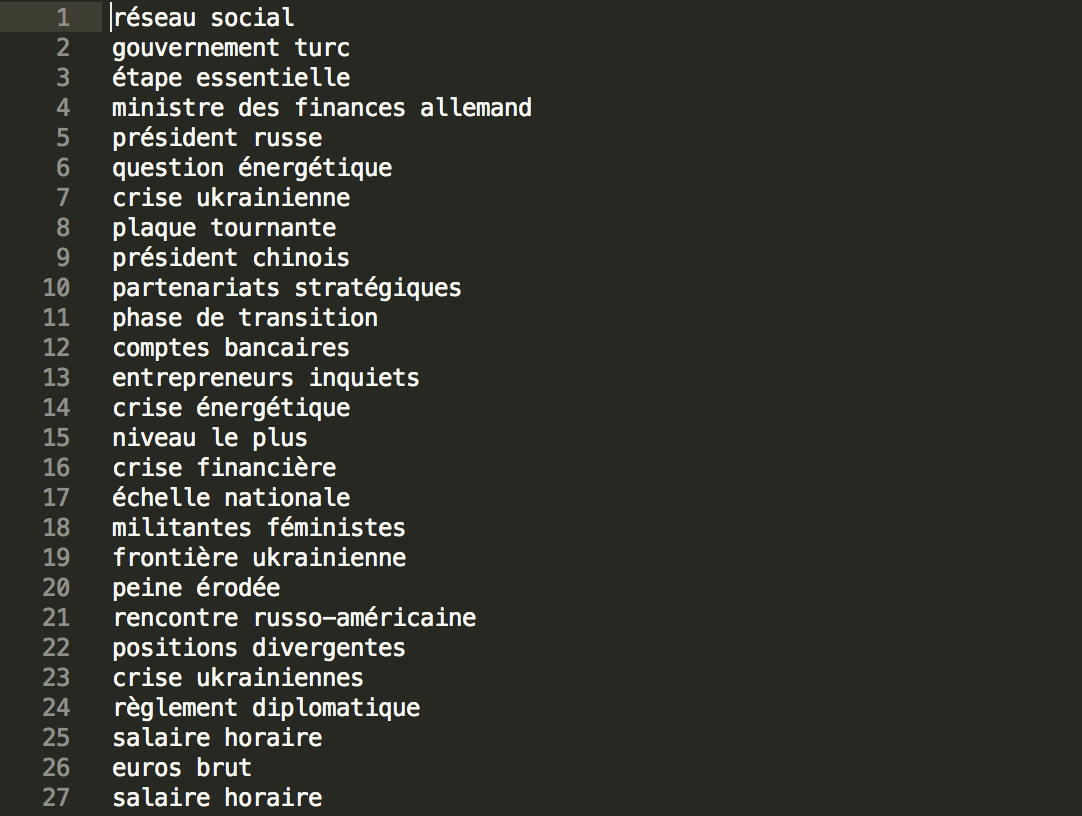
Pour extraire les patrons NOM-PREP-NOM, il sufit de modifier le patron et ajouter dans la boucle while "if ( $nextligne =~ /^([^\t]+)\t[^\t]+\tPREP/)".
open(FILE,"$ARGV[0]"); #-------------------------------------------- # le patron cherchÈ ici est du type NOM ADJ"; # le modifier pour extraire NOM PREP NOM #-------------------------------------------- my @lignes=<FILE>; close(FILE); while (@lignes) { my $ligne=shift(@lignes); chomp $ligne; my $sequence=""; my $longueur=0; if ( $ligne =~ /^([^\t]+)\t[^\t]+\tNC.*/) { my $forme=$1; $sequence.=$forme; $longueur=1; my $nextligne=$lignes[0]; if ( $nextligne =~ /^([^\t]+)\t[^\t]+\tPREP.*/) { my $forme=$1; $sequence.=" ".$forme; $longueur=2; my $nextnextligne=$lignes[1]; if ( $nextnextligne=~ /^([^\t]+)\t[^\t]+\tNC.*/){ my $forme=$1; $sequence.=" ".$forme; $longueur=3; } } } if ($longueur == 3) { print $sequence,"\n"; } }
voici quelques resultats pour la rubrique "SPORT":

Vous pouvez télécharger ici le script NOM-ADJ
Vous pouvez télécharger ici le script NOM-PREP-NOM
Vous pouvez voir ici un examplaire de l'extraction des patrons NOM-ADJ pour la rubrique Livres.
Vous pouvez télécharger ici un examplaire de l'extraction des patrons NOM-PREP-NOM pour la rubrique Sciences.
XPATH
Par la suite, on intégre des requêtes Xpath dans un scrypt Perl, via le module XML:: Xpath. Le script prend en entrée un fichier XML de BAO2 et un autre fichier contenant les patrons à extraire. En sortie, on aura deux fichiers d'extraction pour NOM ADJ et NOM PREP NOM. Ci-dessous, le script utilisé:
#/usr/bin/perl use strict; use utf8; use XML::LibXML; binmode STDIN, ':encoding(utf8)'; binmode STDOUT, ':encoding(utf8)'; if($#ARGV!=1){ print "usage : perl $0 fichier_tag fichier_motif";exit; } my $tag_file= shift @ARGV; my $patterns_file = shift @ARGV; my $xp = XML::LibXML->new(XML_LIBXML_RECOVER => 2); $xp->recover_silently(1); my $dom = $xp->load_xml( location => $tag_file ); my $root = $dom->getDocumentElement(); my $xpc = XML::LibXML::XPathContext->new($root); open(PATTERNSFILE, $patterns_file) or die "can't open $patterns_file: $!\n"; while (my $ligne = <PATTERNSFILE>) { &extract_pattern($ligne); } close(PATTERNSFILE); sub construit_XPath{ my $local_ligne=shift @_; my $search_path=""; chomp($local_ligne); $local_ligne=~ s/\r$//; my @tokens=split(/ /,$local_ligne); $search_path="//element[contains(data[\@type=\"type\"],\"$tokens[0]\")]"; my $i=1; while ($i < $#tokens) { $search_path.="[following-sibling::element[1][contains(data[\@type=\"type\"],\"$tokens[$i]\")]"; $i++; } my $search_path_suffix="]"; $search_path_suffix=$search_path_suffix x $i; $search_path.="[following-sibling::element[1][contains(data[\@type=\"type\"],\"".$tokens[$#tokens]."\")]" .$search_path_suffix; return ($search_path,@tokens); } sub extract_pattern{ my $ext_pat_ligne= shift @_; my ($search_path,@tokens) = &construit_XPath($ext_pat_ligne); my $match_file = "res_extract-".join('_', @tokens).".txt"; open(MATCHFILE,">:encoding(UTF-8)", "$match_file") or die "can't open $match_file: $!\n"; my @nodes=$root->findnodes($search_path); foreach my $noeud ( @nodes) { my $form_xpath=""; $form_xpath="./data[\@type=\"string\"]"; my $following=0; print MATCHFILE $xpc->findvalue($form_xpath,$noeud); while ( $following < $#tokens) { $following++; my $following_elmt="following-sibling::element[".$following."]"; $form_xpath=$following_elmt."/data[\@type=\"string\"]"; print MATCHFILE " ",$xpc->findvalue($form_xpath,$noeud); } print MATCHFILE "\n"; } close(MATCHFILE); }
Voici les resultats qu'on a obtenu pour la rubrique "culture":
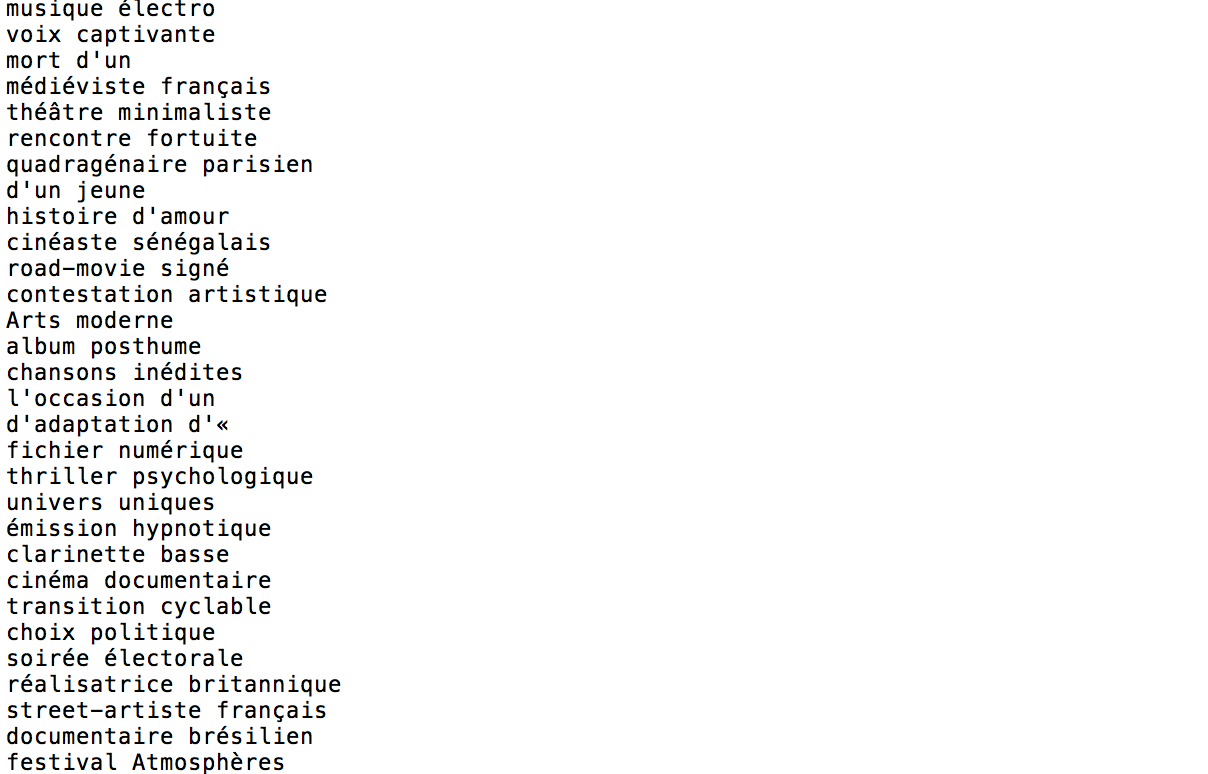
Vous pouvez télécharger le script XPath
Vous pouvez voir un examplaire du résultat pour la rubrique "Culture" NOM ADJ
Vous pouvez voir un examplaire du résultat pour la rubrique "International" NOM PREP NOM