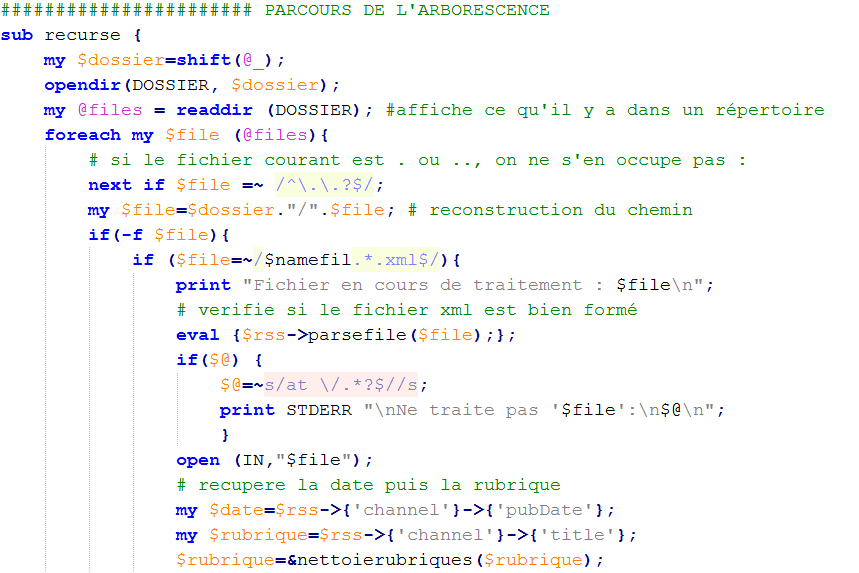
Pour commencer, nous avons travaillé sur une arborescence beaucoup moins gourmande en mémoire, concernant l’année 2008. Cela nous a permis de lancer nos premiers scripts rapidement pour les tester.
Nous avons ensuite téléchargé l’arborescence 2013 complète (beaucoup plus lourde !) fournie par nos professeurs, et nous avons renommé les répertoires des mois par le numéro du mois correspondant, afin d’obtenir un traitement croissant par le programme. Ceci est commode pour savoir où en est le programme dans son travail.
Les scripts :
Nous avons deux scripts : un qui utilise la bibliothèques de Perl pour traiter les fichiers XML ; l’autre qui utilise les expressions régulières. ces deux méthodes permettent de récupérer les informations qui nous intéressent.
Globalement, nos deux scripts doivent parcourir notre arborescence de fichiers, et ne traiter que les fichiers XML en entrée (soit les fils RSS). Ils récupèrent la date du fichier ainsi que le nom de la rubrique :
Pour des soucis de temps de traitement, (et aussi, avouons-le, pour éviter de relancer un programme de plusieurs heures/jours en cas de problème) nous avons choisi de lancer les scripts pour chacune des rubriques, en donnant en argument une partie du nom de celles-ci, par exemple : perl bao1-script_xmlrss.pl 2013 3208, le "3208" correspondant à une rubrique. Nous avons fait en sorte que les fichiers soient nommés par le nom des rubriques concernées. Pour cela, nous avons récupéré le nom de la rubrique dans les fichiers XML, que nous avons inséré dans une variable $rubrique, réutilisée pour nommer ces fichiers. Nous avons pris soin de « nettoyer » les noms des rubriques pour supprimer les parties du type « le monde.fr », les espaces, les caractères accentués, et nous les avons transformées en majuscules pour plus de lisibilité. Ainsi "le monde.fr : à la une" devenait "ALAUNE". Voici la fonction à laquelle nous faisons appel :

Ensuite, nous préparons les sorties. Il faut faire en sorte que le programme crée une sortie dès qu'il rencontre une nouvelle rubrique, et qu'il concatène les informations dans ce même fichier si celui-ci a été créé. Pour cela, nous utilisons la fonction -e dans une boucle if, permettant de créer un fichier ou de concaténer les informations selon si le fichier de sortie a été créé ou non :
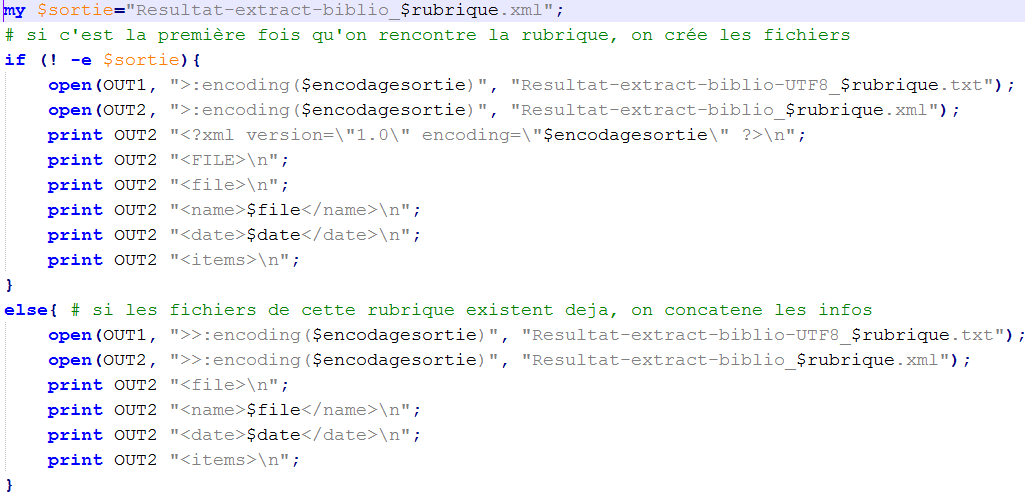
Les scripts doivent donner deux types de fichiers en sortie : un en XML et un en TXT, qui seront traités ultérieurement par des logiciels d’étiquetage morpho-syntaxique. Nos scripts récupèrent les informations qui nous intéressent, c'est-à-dire les titres et les descriptions de chaque fils RSS. Puis ils invoquent une fonction « nettoietexte », permettant d’obtenir des fichiers propres en sortie, en remplaçant, par exemple, les codes d’accents HTML par le bon caractère :

C'est à ce moment où nos deux scripts divergent : ils n'utilisent pas la même méthode pour récupérer les informations. Dans ce qui suit, nous présentons les deux méthodes utilisées.
Le script REGEX
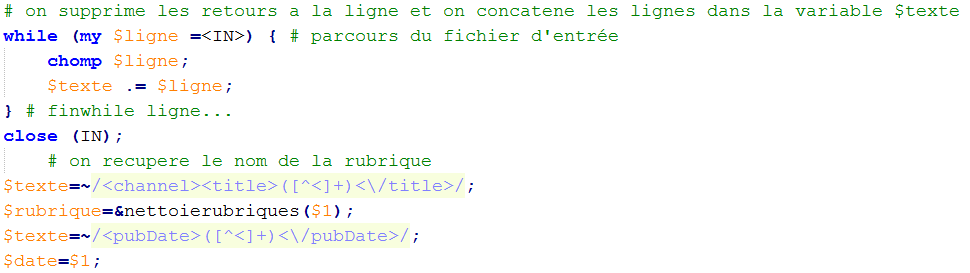
Dans celui-ci, nous récupérons les informations à l'aide d'expressions régulières. Pour que le programme les reconnaissent, nous avons besoin de supprimer les fins de ligne et de concaténer les lignes les unes à la suite des autres. Nous les stockons dans une variable préalablement initialisée que nous appelons $texte. Pour récupérer le nom de la rubrique, nous avons récupéré ce qui se trouve dans la balise "title", qui suit la balise "channel", comme nous pouvons le voir dans la figure ci-dessous. Idem pour récupérer la date :
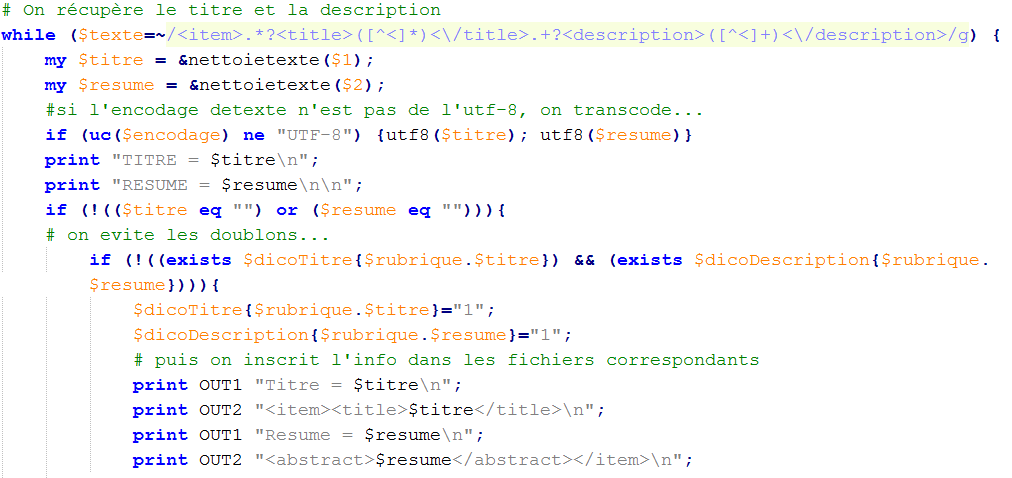
Pour récupérer le titre et la description, nous utilisons une boucle while pour que tout le texte compris dans la variable $texte soit traité (si nous utilisons if, nous n'aurons que la première occurrence pour chaque fichier). Nous demandons ce qui se trouve entre les balises "title", qui suivent la balise "item", afin d'éviter d'avoir comme résultat "le monde.fr" ou "le monde actualités". Pour le résumé, nous demandons ce qui se trouve entre les balises "description" :
Vous pouvez télécharger le script complet avec le lien ci-dessous :
Problèmes rencontrés...
Ce qui nous a le plus posé problème, c'est la concaténation des lignes du fichier dans une variable. Si la méthode est très simple à réaliser (cela ne prend que 3 lignes de code), sa position dans le script est délicate. Notons qu'il ne faut surtout pas oublier d'initaliser la variable (ce que nous avons fait...!), autrement, la concaténation de fonctionne pas.
Nous avions tout d'abord demandé cette méthode deux fois dans notre script : la première pour récupérer le nom de la rubrique, avant la création des fichiers et le traitemment des titres et des résumés, à l'aide d'une boucle while, en prenant soin de fermer le fichier traité juste après. Puis une seconde fois au moment du traitement des informations. Mais lorsque nous avons voulu faire en sorte de récupérer les titres hors "le monde.fr" etc, nous nous sommes rendu compte que la concaténation des lignes ne se faisait pas, du fait de la première boucle, puisque les balises "item" et "title" sont sur deux lignes. Nous avons donc supprimé cette deuxième boucle, inutile car la première suffisait. Il fallait ensuite travailler sur la variable $texte.
Pour finir, nous nous somme obstinée à utiliser une boucle if pour récupérer les informations. Le programme ne nous donnait alors que la première occurrence trouvée par fichier et passait son chemin. Il faut donc utiliser une boucle while pour qu'il parcourt toute la variable $texte et nous donnent toutes les occurrences possibles par rapport à notre expression régulière.
Le script XML::RSS
C'est cette méthode que nous avons choisi d'utiliser pour traiter nos fichiers. Celle-ci nous paraissait plus simple et plus fiable (à tord, peut-être?).
Ce script utilise la bibliothèque Perl XML::RSS, permettant de vérifier si un fichier est bien de l'XML, et de rechercher des informations dans celui-ci sans utiliser d'expressions régulières. Par exemple, nous dirons que dans la variable $date, nous stockons les informations qui se situent entre les balises "pubdate" :
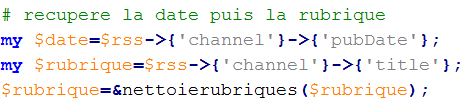
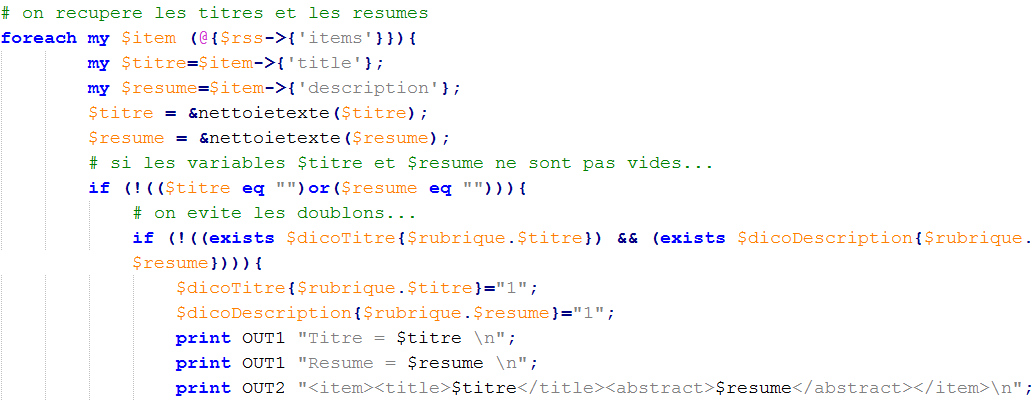
Nous récupérons les titres et les résumés de la même manière. L'opérateur "flèche" permet d'accéder aux informations à l'aide d'une grande table de hashage; la table de hashage "channel", prend les valeurs de "item" ayant comme clés "title" et "desciption" :
Vous pouvez télécharger le script complet avec le lien ci-dessous :
Problèmes rencontrés...
Nous avons eu un "gros" problème d’encodage qui nous a fait perdre plusieurs jours… En effet, les noms des rubriques une fois nettoyés s’affichaient mal dans l'arborescence lorsqu’il y avait un caractère accentué : il semblait que la machine, probablement encodée en utf-8, lisait de l'ISO-8859-1. En réalité, le programme fonctionnait très bien, mais le problème provenait de l’encodage de l'éditeur de texte dans lequel le script avait été rédigé...Et non, Notpad++, très bon éditeur cependant, n'est pas encodé en utf-8 par défaut...C'est une chose qu'on n'oublie pas!
Le second problème est que certaines rubriques peuvent être intitulées de deux manières différentes au cours de la même année. Par exemple, pour la rubrique "à la une", nous rencontrons « à la une », et « actualité à la une ». Le programme nous créait donc deux fichiers pour cette même rubrique, nommés « ALAUNE » et « ACTUALITEALAUNE ». Evidemment, cela arrivait sur Décembre, donc à la fin du programme…Nous avons donc fait en sorte que notre fonction de nettoyage de rubrique supprime « actualité », et nous avons pu relancer notre programme.
Ces scripts une fois prêts, nous pouvons passer à la suite du projet, la BàO 2, qui consiste à étiqueter les données récupérées.