Dans la deuxième partie du projet, il s’agit d’étiqueter morpho-syntaxiquement les fichiers générés par les programmes. Pour les fichiers TXT, nous utilisons le logiciel Cordial ; pour les fichiers XML, nous utilisons Treetagger. Ce dernier nécessite la modification de nos scripts, car il peut être intégré directement dedans. Précisons que nous avons tout d'abord ajouté un détail dans nos scripts concernant les sorties titre/résumé : nous avons fait en sorte d'ajouter un point à la fin de chaque titre et de chaque résumé, afin que ceux-ci soient bien reconnus par les logiciels d'étiquetage. Il a tout simplement fallu ajoutrer ce point sur les lignes print comme suit : print OUT1 "Resume = $resume.\n";
Etiquetage avec Cordial
Cordial a l’avantage d’être très rapide, mais le désavantage de ne pas supporter l’utf-8. Nous avons donc du préparer les fichiers initialement encodés en UTF-8. Deux solutions s’offraient à nous : mise en place d’un programme qui transcode tous nos fichiers TXT utf-8 en ISO-8859-1 ; ou tout simplement « enregistrer sous » ces mêmes fichiers dans un logiciel de traitement de texte, en les transcodant en ISO-8859-1. Nous avons choisi la deuxième solution, pensant que celle-ci allait être plus rapide… En réalité, cette tâche n’est pas sans risque de perdre les données sous une mauvaise manipulation.
Nous avons procédé par le biais de WORD. Nous avons renommé les fichiers pour les enregistrer une seconde fois, en précisant à WORD sous quel encodage nous voulions les sauvegarder. Il a fallu, de plus, cocher la case « autoriser la transformation de caractères », pour éviter d’avoir quelques scories comme nous le montrait l’aperçu du logiciel.
Pour finir, sous les conseils de S. FLEURY, nous avons enlevé les informations « titre » et « résumé » à l’aide d’un chercher/remplacer sous Cordial (possible aussi, bien sûr, sous WORD, Notepad++…), car nous n’avions pas besoin de ces informations (répétitives, qui plus est) pour l’étiquetage. Une fois cette préparation faite, nous avons procédé à l’étiquetage sous Cordial (beaucoup moins longue que la préparation, certes !). Celui-ci est assez simple d’utilisation. Il suffit d’ouvrir le fichier, de demander l’étiquetage syntaxique, et de cocher ou non les cases dans la boîte de dialogue. Dans ces paramétrages, nous avons coché :
- Dans « numérotation des mots de chaque phrases » : « non »
- Puis « lemme »
- Dans « type grammatical » : « abrégé en majuscules »
- Dans « codage spécialisé » : « aucun »
- Puis « ne pas corriger les erreurs »
- Dans « Statistiques » : nous avons tout décoché.
Cordial nous donne en sortie un nouveau fichier avec notre texte étiqueté. Nous nous servirons de celui-ci pour extraire des patrons morpho-syntaxiques dans la BàO 3. Vous pouvez télécharger un exemple de fichier généré par Cordial ci-dessous :
Exemple de fichier généré par Cordial
Etiquetage avec Treetagger
Treetagger est un logiciel d’étiquetage utilisable en ligne de commande. Il nécessite au préalable de lire un fichier où un mot = une ligne : pour cela, il faut procéder à une tokenisation à l’aide un programme. Pour appeler Treetagger en ligne de commande, il faut suivre la syntaxe suivante : Chemin de Treetagger + chemin du fichier correspondant à la langue analysée + chemin du fichier à analyser + options éventuelles + redirection.
TreeTagger peut donc être intégré dans un script. Nous pouvons aussi faire un programme à part, mais nous avons choisi la première solution. Nous avons créé une fonction qui fait ce travail, invoquée au moment où nous récupérons les informations à l'aide d'une ligne :

Dans la fonction, Treetagger prend en entrée les titres et les résumés récupérés. La fonction ouvre un fichier temporaire dans lequel s'y inscrit les informations au fur et à mesure. Par la suite, TreeTagger tague l'information temporaire, puis nous faisons appel à un programme qui transforme le fichier TXT généré par Treetagger au format XML, en lui donnant comme paramètre le nom du fichier généré par Treetagger, puis une redirection qui sera automatiquement nommée au format XML. Voici à quoi ressemble la fonction :
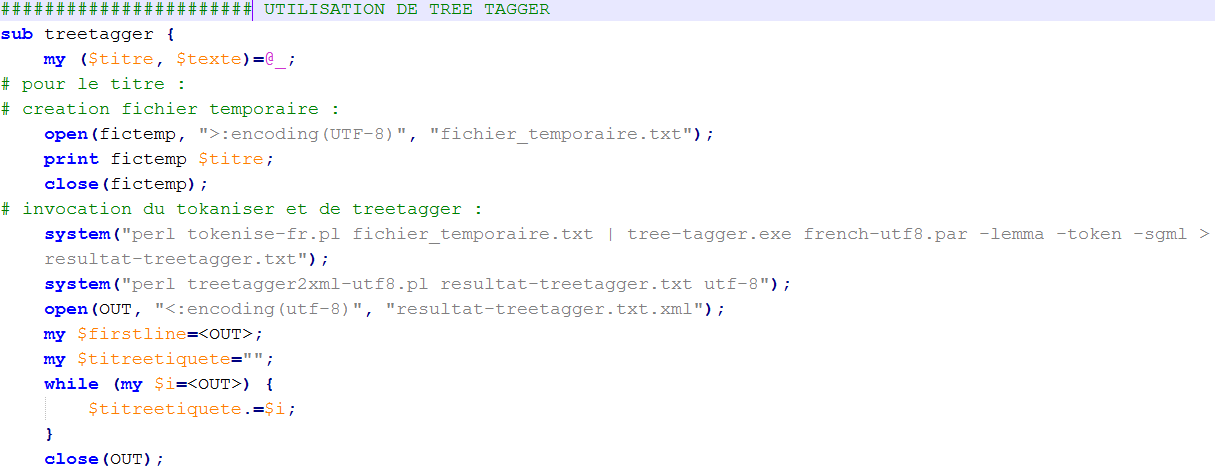
A partir de la ligne 3, nous réitérons le code pour le résumé. Vous pouvez télécharger un fichier exemple généré par Treetagger ci-dessous :
Fichier exemple généré par Treetagger
Problèmes rencontrés...
Etant la reine des erreurs stupides, précisons qu'il faut faire attention de bien utiliser le fichier temporaire dans la fonction Treetagger. Au départ, nous avions mis, sans réfléchir, deux chevrons dans la ligne de code "system" pour la transformation en XML, ce qui faisait que Treetagger taguait toutes les informations qui se concaténaient dans le fichier. Autrement dit : il reprenait le fichier depuis le début jusqu'à la fin, fin qui s'éloignait au fur et à mesure des ajouts d'informations. Nous nous retrouvions avec un fichier en sortie d'une taille si importante qu'il était impossible de l'ouvrir dans quelque logiciel que ce soit...si tant est que le programme n'ait pas fait planter la machine avant...faute de mémoire!
Une fois les scripts prêts, nous avons pu lancer notre programme (rappelons que nous avons choisi le script utilisant le module XML::RSS) pour chacune des rubriques. Nous avons récupéré, dans le nom des fichiers correspondants aux rubriques, ce qui les distinguait : Le Monde utilise des numéros pour chaque rubrique. Il suffisait d'utiliser ce numéro comme paramètre lors du lancement du programme. Celui-ci se lançait donc ainsi :
perl bao2-script_xmlrss_treetagger.pl 2013 3208
Nous appelons donc le script, qui prend deux paramètres : le dossier sur lequel nous voulons le traitement, puis le numéro de la rubrique que nous voulons traiter, qui sera récupéré dans la variable $namefil. Pour plus de clarté, vous êtes invité(s) à télécharger le programme complet :