Sommaire de la page
A propos de la BAO
Bienvenue !
Ce site comme tant d'autres, à pour but de présenter le travail réalisé ce semestre de Master 1 TAL dans le cadre du cours de projet encadré
(pour plus de détails cliquez ici : projet Bao ).
Le projet en lui-même dit « Boîte à Outils » ou BAO.
Le but étant ici de traiter les éléments issus de l'extraction des flux rss du monde. Cette extraction réalisée dans le cadre du cours ne sera pas traitée,
le résultat étant l'intégralité des flux rss du monde de l'année 2013 sous deux formats : txt et xml.
Les données xml représentent notre point d'entrée. La BAO se divise en quatre phases distinctes ayant des impératifs imposés pour chacune d'elles.
Nous aborderons chacune des phases en les nommant respectivement, BAO 1, 2 ,3 ET 4.
Chacune d'elles sera décrite dans un onglet traitant de celle-ci et décrivant :
- Les prérequis pour la réussite de celle-ci,
- Le traitement à proprement parler – avec bien sûr un point sur les problèmes rencontrés et les solutions proposées,
- Les résultats commentés,
Nous garderons bien sûr à l'esprit de porter un regard critique sur le travail proposé,
l'abstraction critique étant à notre sens aussi essentielle que la maîtrise technique avec codage de script.
Nous aurons pour nous aider un peu de bon sens et la magie technologique en traitement que nous propose l'arsenal du langage de programmation Perl.
Quelques images qui en disent plus que des mots
Voici maintenant quelques images issues du site du projet sur Plurital qui en diront un peu plus sur le contenu attendu et le traitement employé.
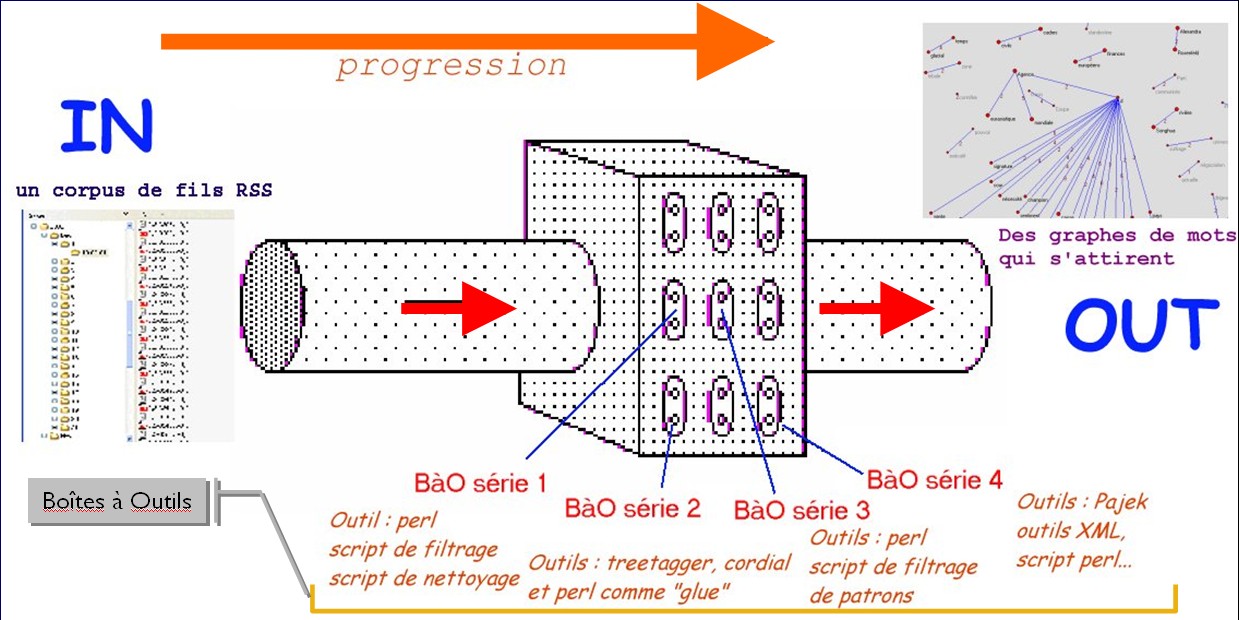
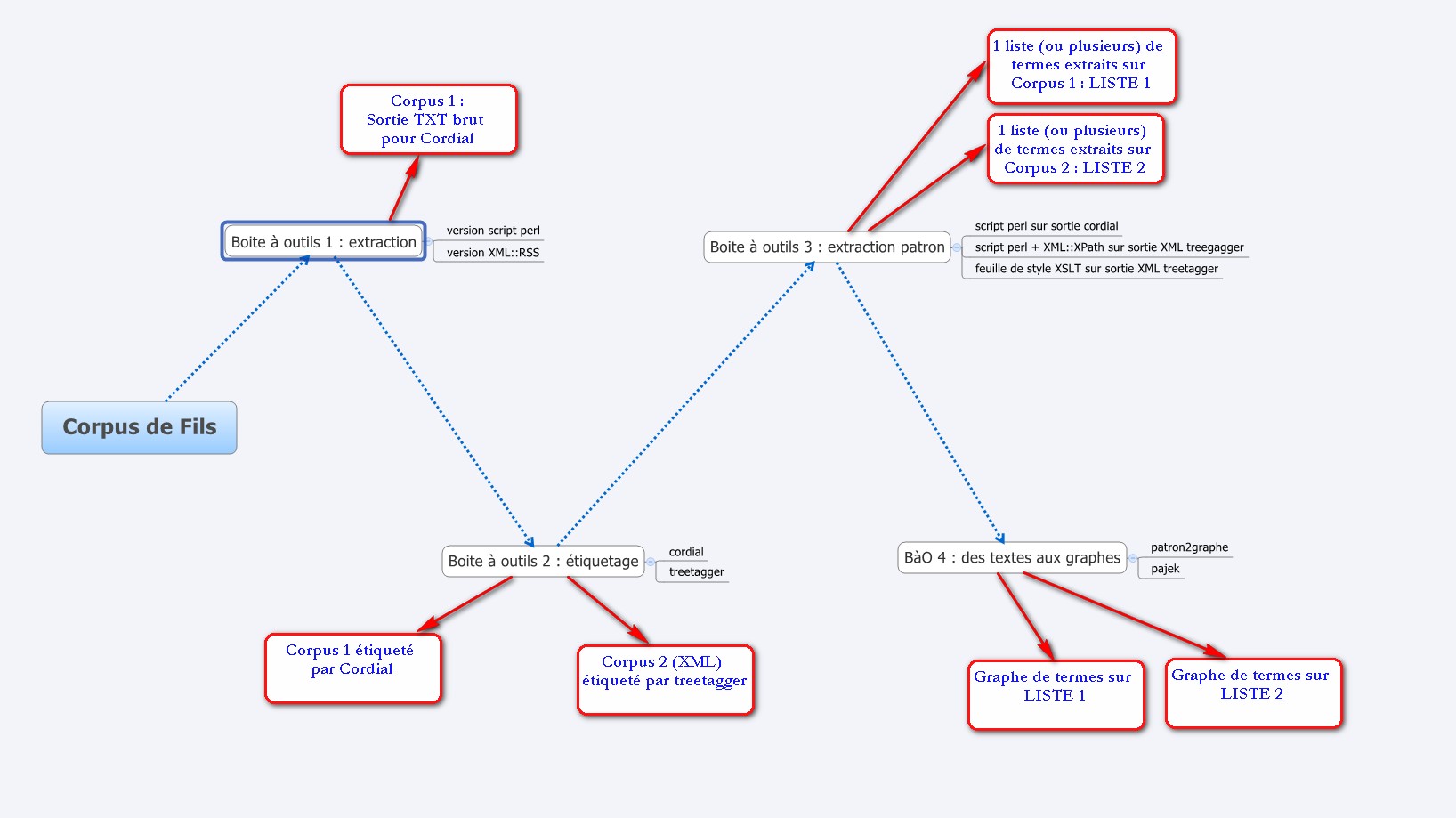
Catégorisation
Il convient néanmoins, avant de commencer à travailler sur la BAO de se pencher un peu sur les données de travail et de tenter quelque peu de les catégoriser suivant quelques critères :
- Taille : 1492745 mots et 43392 phrases (résultat obtenu en parallèle via le module python NLTK cf infra)
- Annotations : Taguer grâce au programme Treetagger (Part-of-Speech Tagging) cela à partir de BAO3.
- Statut de la documentation : Informations généralistes
- Stratégie d’échantillonnage et origine des textes : Presse écrites
- Modalité : Écrit (parfois retranscription de l'oral en cas de témoignages rapportés)
- Licence et droits d’utilisation : contenu privé soumis à des droits d'auteur
Petit Ajout sur NLTK (Python)
Bien que cela soit un peu hors sujet, puisque NLTK nous a permis une certaine catégorisation du corpus, nous considérons qu'un ajout concernant
ces éléments utilitaires n'est pas forcément inutile ni en dehors du propos.
Ainsi, nous détaillerons un minimum, et en paraphrasant un peu (voir beaucoup !) une partie de notre travail rendu en cours de Traitement de corpus.
Concernant NLTK (Natural Language Toolkit) du langage Python il suffira d'aller faire un tour sur la documentation.
Cliquez ici et aussi ici
Application
Une fois le module installé, on place l'archive dans le dossier des données nltk_data et on l'extrait. (tar -xvzf


On passe ensuite par diverses étapes de façon à initialiser un objet puis à instancier un élément issu de celui-ci :
1) Après avoir activé l'interpréteur python grâce à la commande du même nom, on importe ensuite l'objet pour le corpus, il est instancié.
Un jeu de méthodes/procédures est alors disponible. (cf infra)

module : nltk.corpus.reader
classe :CategorizedTaggedCorpusReader
2) On utilise ensuite les expressions régulières pour sélectionner tous les fichiers du dossier portant le nom :
'sortie_ suivi d'un mot portant l'extension « .txt » et « .tagged » qui formeront les catégories d'objet, deuxième paramètre
pour la création de l'instance issue de l'objet CategorizedTaggedCorpusReader.
Le premier paramètre de l'objet est déterminé par l'expression régulière
.*\.tagged (soit un caractère présent 0 ou 1 fois suivi d'une extension .tagged (le point étant dé-spécialisé).
Le deuxième paramètre est déterminé par la variable cat_pattern qui contient
les mêmes fichiers avec une expression régulière similaire mais dont on n'utilise cette fois les parenthèses « capturantes » pour garder
le nom du fichier qui est aussi le nom de la rubrique.
Le tout est alors stocké dans la variable lemonde_rss.

r : utilisation d'expressions régulières
CategorizedTaggedCorpusReader : classe
cat_pattern : catégorie d'objets
Nous avons alors accès aux méthodes et procédures de l'objet que nous décrivions plus haut et pouvons « interroger » les possibilités avec help :

3) Observons maintenant la fonction « categories » :

… qui définit bien évidemment les catégories présentes dans notre corpus (le grand retour et la preuve de l'utilité des fameuses parenthèses capturantes!).
4) On va maintenant pouvoir interroger ces catégories pour nous aider à spécifier les détails du corpus :
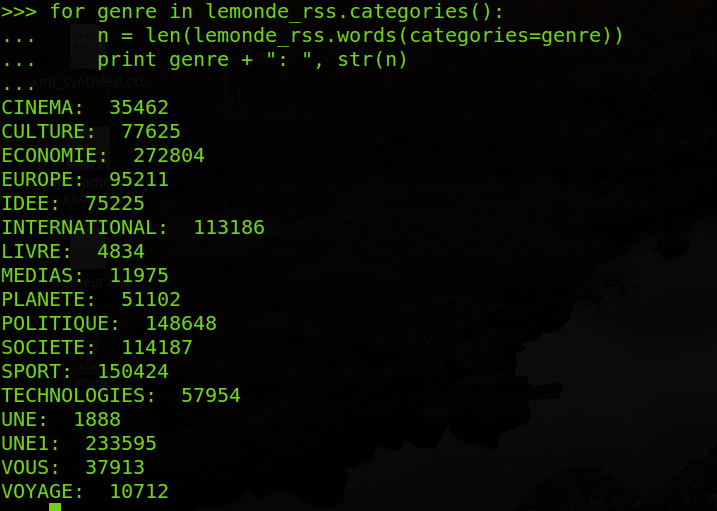
On initialise une variable genre qui prendra tour à tour les valeurs de chacun des éléments de la liste « catégories » que l'on a affichés auparavant. Quand la variable prend une valeur on utilise une variable n pour stocker le résultat de la fonction len (qui renvoie le nombre d'objet d'une séquence) appliqué à la fonction lemonde_rss.words (categories=genre). Celle-ci affichait les mots présents dans la catégorie spécifiée. La variable genre change et on obtient donc les mots de chaque catégories, comptés ensuite par len, et stockés dans n. On demande ensuite simplement un affichage avec print du contenu de genre et de n. On comprend bien qu'en l'appliquant globalement on obtient donc le nombre de mots global du corpus :

De la même façon on peut obtenir le nombre de phrases en remplaçant la fonction words par sents :

L'intermède Python étant terminée nous vous enjoignons sans plus attendre à cliquez ici
pour rejoindre la partie BAO1.
A propos de la BAO
Catégorisation
Petit Ajout sur NLTK (Python)
Application NLTK
Retour au sommaire