Sommaire de la page
- A propos de la BAO 1
- Script Bao1
- Script, liens de téléchargement
-
Résultats BAO1 et Tableau Récapitulatif
A propos de la BAO 1
Familiarisation avec les données
La Bao 1 fut l'occasion du premier travail sur les données brutes du corpus.
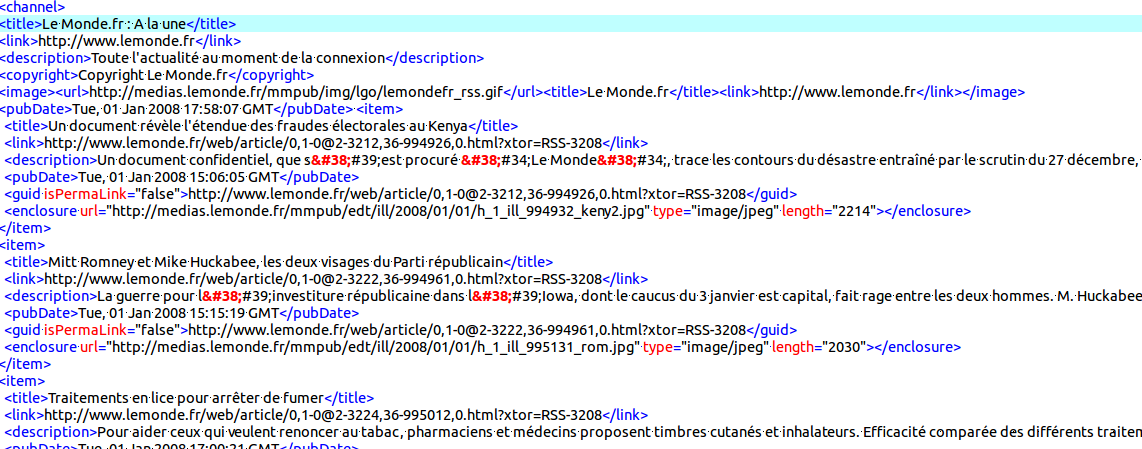
Comme nous l'avions déjà dit auparavant, nous possédions en effet les données issues du flux RSS du journal du monde de
l'année 2013, ainsi qu'un corpus test de 2008 sous deux formats : XML et TXT.
Chacun étant classé par dossier Mois/Jour/Heure(toujours à 19h, heure de la copie des pages). Dans notre cas l'extraction se basait uniquement
sur les fichiers XML.
Plus particulièrement nous devions, pour satisfaire aux besoins de l'exercice extraire les balises "title" et "description", avec la subtilité de ne pas extraire les premières balises "titre" et "description" (titre et description du document et non d'un article)
Du point du de vue du travail à réaliser il fallait donc :
- Traiter un grand nombre de fichiers répartis dans plusieurs dossiers
- Ne traiter que les fichiers .xml et non les .txt : données non homogènes
- Repérer les balises à extraire et celles à ne pas traiter
- De plus, bien que les données d'entrée soit uniquement des données XML, nous devions obtenir en sortie un format .xml et .txt.
Nous avons décidé en outre d'ajouter une sortie .html ceci pour une meilleure visualisation, et aussi car proche de l'XML, le traitement de cette sortie ne devait pas poser problème. - Enfin deux dernières directives nous étaient données :
La première était que nous ne devions extraire une seule fois chaque titre et chaque description : autrement dit, pas de doublons !
La seconde était que nous devions utiliser le maximum des techniques proposées : une méthode pure perl et une méthode avec module , nous avons d'ailleurs incorporé les deux dans le même programme que nous détaillerons ci-après. - Ainsi qu'une directive optionnelle mais utile si on la réalisait :
Séparer les fichiers extraits par rubrique de cette façon on pouvait avoir des fichiers moins volumineux et, aussi, faire un travail de catégorisation en BAO 4 par rubrique. Ce qui permettait d'avoir des fichiers moins volumineux pour un traitement ultérieur via divers logiciel (Cordial et Treetagger)
Script Bao 1
Explications globales
Dès le début nous avions l'idée de séparer chacune des taches bien spécifiques à réaliser. En effet l'idée de traiter toutes les taches de la même façon, linéairement ne contribue pas à la portabilité. Comme certaines des taches sont amenées à être de nouveau utilisée, soit sur des parties annexes du projet, soit dans de futures activités, le découpage par fonction allait, selon nous, ici de soi. Nous avons donc réalisé un script à strate, chaque partie réalisée, appelant la fonction suivante. Passons maintenant aux explications centrées sur le script.
Nous n'allons pas détailler chaque ligne, mais juste les idées globales, le script par lui-même étant disponible ensuite :
- Ligne 1 – 36 : Essentiellement des points habituels dans un programme.
a)Déclaration de l'en-tête, des modules utilisés, (on remarquera que certains modules ont été abandonnés au fur et à mesure de l'avancée du programme et des choix effectués).
b)Récupération de l'argument passé au programme qui sera le dossier d'origine ($racine) et auparavant condition sur ce même argument avec fin du programme si la condition de présence de celui-ci n'est pas satisfaite.(ligne 19)
c)Déclaration de diverses variables et tables de hachage.
d)Une partie nettoyage qui efface les extractions antérieures puis appel de la première fonction. - Ligne 42 – 116 : étape 1 : parcours d'arborescence/reconnaissance des fichiers à traiter/construction de l'arborescence de travail sur ces fichiers.
Les deux fonction lectureDossier1 (ligne 46) et lectureDossier2 (ligne 74) se comportent de la même façon. Elles prennent en argument un nom de dossier qui sera la racine d'un parcours d'arborescence. Cependant, la finalité n'est pas la même, la première lance le processus de traitement, tandis que la seconde ré-ouvre les fichiers html et xml issus du traitement afin d'y insérer les "footers",(voir fonctions footerHtml et footerXML respectivement lignes 452 et 469).
Nous allons donc décrire uniquement la fonction lectureDossier1 :
Si les fonctions n'ont pas la même finalité, elles ont, par contre, un fonctionnement similaire.
a)On commence par récupérer le nom de dossier. Et On l'ouvre.
b)Grâce à un foreach on prend en compte chaque élément du dossier ouvert. On récupère ensuite ces éléments dans 2 variables. La variable $saveName ne sera utilisée par la suite que si l'élément est un fichier et pour ne garder que le nom du fichier. Elle sert essentiellement à nommer les fichiers de sortie du même nom que les fichiers d'entrée. La variable $x permet elle, de reconstituer le chemin.
c)Le next if permet de ne pas prendre en compte les dossier "." et "..", dans le premier cas cela générerait une boucle infinie, dans le second on pourrait remonter jusqu'à la racine ... .
d)On teste les éléments, si c'est un dossier (hormis comme on l'a vu les dossiers "." et "..") on rappelle la fonction qui agit donc récursivement. Si c'est un fichier on appelle la fonction suivante, on passe donc au traitement de fichier à proprement parler. -
Ligne 116 – 128 : étape 2 : vérification du format de fichier (si .xml on traite, sinon pas d'utilisation)
a) Récupération du fichier
b) Test sur le nom de ce fichier au moyen d'une expression régulière : .*\.xml : soit un caractère (".") reproduit 0 ou plusieurs fois ("*") finissant par ".xml" (le point est déspécialisé). Dans ce cas la on appelle la fonction suivante avec en paramètre : chemin/fichier.xml - Ligne 129 – 164 : étape 3 : évalue et établit l'arborescence du fichier de sortie
a) Récupération du nom de fichier et déclaration des variables locales
b) Lecture du fichier et substitution via une expression régulière sur le handle de tous les sauts de ligne, cela permet un traitement sur une ligne.
c) Localisation de la rubrique et capture de son nom grâce à la regExp (expression régulière): "(.*?)", les parenthèses permettant de capturer l'élément et le "?" de rendre l'expression "non gourmande" afin de bien cibler notre élément nom de rubrique.
d) Appel de la fonction nettoyageRubrique expliquée ci après et récupération du résultat qui sera notre nouveau nom de rubrique
e) Appel des fonctions relatives au traitement d'extraction à raison d'une fonction par méthode d'extraction
-
Ligne 165 – 205 : étape 3.1 : nettoyage des noms de rubrique
On cherche ici à "nettoyer" les noms de rubrique et à les uniformiser pour éviter tout problème de traitement futur puisque chaque nom de rubrique deviendra un nom de dossier correspondant.
a) Récupération du nom de rubrique puis déclaration d'une table de hachage, chaque clé sera remplacée par sa valeur.
b) Parcours de la table et remplacement des clés par leur valeur
c) Remplacement des minuscules par des majuscules, puis substitution de quelques éléments graphiques pour faciliter la visibilité
d) On retourne les nouveaux éléments rubrique. -
Ligne 206 – 435 :étape 4 : le coeur du programme, l'extraction
Nous en arrivons à la partie principale du programme. Chacune des quatre fonctions d'extraction a une partie commune et une partie spécifique. Commençons par décrire la partie commune
- Parties communes :
a)On commence par récupérer le nom de fichier et de rubrique puis par appeler la fonction detectionEncodage
b)Cette fonction (ligne 476-492) sert à extraire l'encodage contenu dans l'entête xml, Pour cela on ouvre le fichier et on extrait l'encodage grâce à une expression régulière (<.xml.*?encoding=(.*?).>), on supprime les guillemets, puis on renvoi le résultat.
c) On récupère l'encodage et on ouvre le fichier avec son encodage.Nous avons choisi de ne pas traiter les problèmes d'encodage dans cette partie (BAO1) mais ensuite, l'encodage d'origine est donc ici préservé.
e) Grâce à $saveName nous avons le nom d'origine du fichier sans le chemin, nous substituons dans les 4 cas l'extension du nom du fichier d'entrée par celle du fichier de sortie (xml/html/txt)
f) On créer les dossiers rubriques, le chemin puis on ouvre le fichier de sortie (de cette façon le classement par rubrique est effectué) puis on le parcours. On réemploie aussi le traitement sur une ligne.
g) On appelle la fonction nettoyageFichier (ligne 375 - 434) qui grâce une table de hachage remplace les clés par les valeurs, qui elle même appelle la fonction enleveBalise (ligne 494 - 502) qui va faire un dernier nettoyage des résidus de balise. Au retour nos fichiers ont été nettoyés.
h)Ensuite les cas divergent mais un autre élément unis les méthodes d'extraction : le test d'existence. En effet on récupère nos balises title et description dans des tables de hachage, si le titre existe déjà on ne l'extrait pas encore une fois, on respecte ainsi le prérogative de n'extraire qu'une fois chaque titre et description, nous n'aurons donc pas de doublons (cf image suivante).
le test d'existence, extraction et recopie Nous pouvons a présent passer à la phase de description spécifique
- Parties spécifiques :
a) Extraction TXT
La fonction d'extraction TXT ne nécessite aucun traitement particulier dans ce sens qu'elle ne se contente "que" d'extraire le contenu des balises et de recopier le contenu en sortie. De ce fait son comportement est assez bien décrit ci-dessus, c'est la base de notre méthode d'extraction .
b) Extraction HtmlCette fonction doit insérer une série d'éléments correspondant aux entêtes html habituels mais qui ne doivent apparaître qu'une fois par fichier traité. Nous testons donc grâce à une table de hachage si nous avons déjà ouvert un fichier de ce nom. Si c'est le cas on ne fait rien d'autre qu'augmenter la valeur de notre table de hachage, sinon c'est la première fois que l'on rencontre ce fichier,on insère alors les éléments html. (Et merci à Mr S.Fleury et Mr JM. Daube pour l'idée de technique)
De plus nous souhaitons présenter les éléments sous forme de tableau, il faut donc insérer les balises table, tr et td judicieusement.
Enfin le header et le footer sont appelés mais pas de la même façon , le header est appelé par un fonction avant l'extraction, le footer est appelé à la fin du programme (une fois tous les fichiers traités) par la fonction lectureDossier2 dont nous avons déjà vu le fonctionnement grâce à lecture dossier1 (voir images ci-dessous).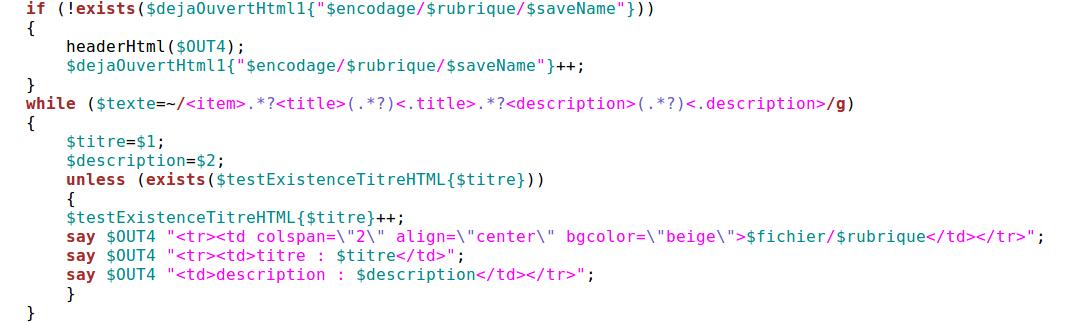
la fonction d'extraction html 
les fonctions header et footer html
c) Extraction XML
Cette fonction est proche de la html décrite ci-dessus, la seule différence est l'insertion d'un élément racine au lieu des entête html (l'élément < dossier > )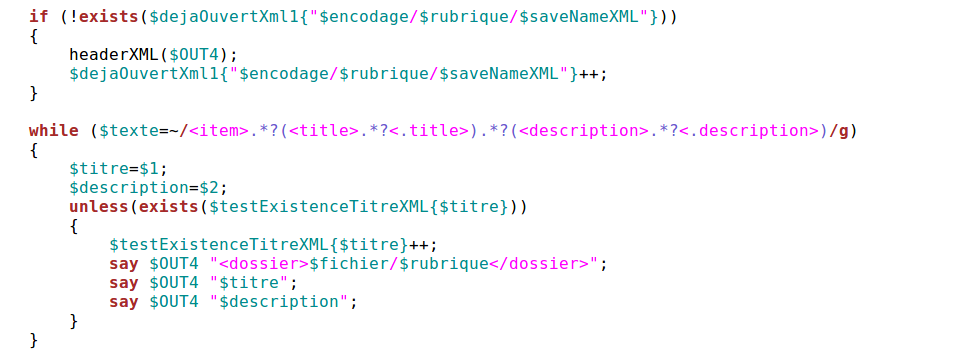
la fonction d'extraction Xml 
les fonctions header et footer xml
d) Extraction XML::RSSLa fonction Xml Rss est la plus complexe du point de vue de l'abstraction puisqu'elle fait appelle au concept "d'objet".
On commence donc par créer un objet avec :
my $rss = new XML::RSS;.
L'objet à analyser est indiqué par la fonction parsefile comme ceci :
$rss->parsefile($fichier);
Reste à instancier à chaque cas. On utilise le test d'existence (pas de doublons !) Puis on extrait :
$texte=nettoyageFichier($titre);
say $OUT5 "titre : $texte";
$texte=nettoyageFichier($description);
say $OUT5 "description : $texte"; L'intégralité de la fonction ci-dessous.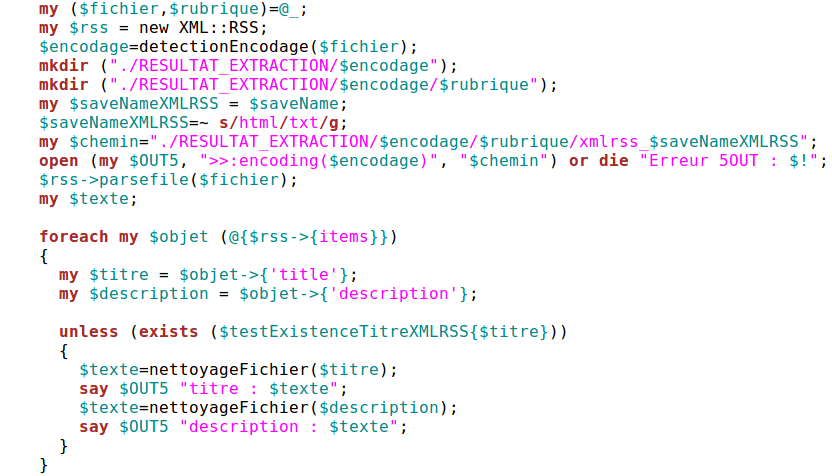
la fonction d'extraction Xml::Rss
- Parties communes :
L'avantage est ici que l'on peut rajouter le nombre de méthodes d'extraction que l'on veut et ainsi étendre la portabilité du programme. Bien sûr, chaque fonction rajoutée est autant de temps d'exécution du programme en plus, propre au temps de traitement de chaque fonction
L'essentiel du script est expliqué on trouvera ci-dessous le script tel qu'il a été utilisé au moment de l'extraction.
Script, liens de téléchargement
Pour commencer le lien vers le téléchargement du script : Cliquez ici
Et une page html simple pour mieux visualiser les explications (possible aussi de cliquer sur l'image) : Cliquez ici
Et bien sûr le script à visualiser ici même :

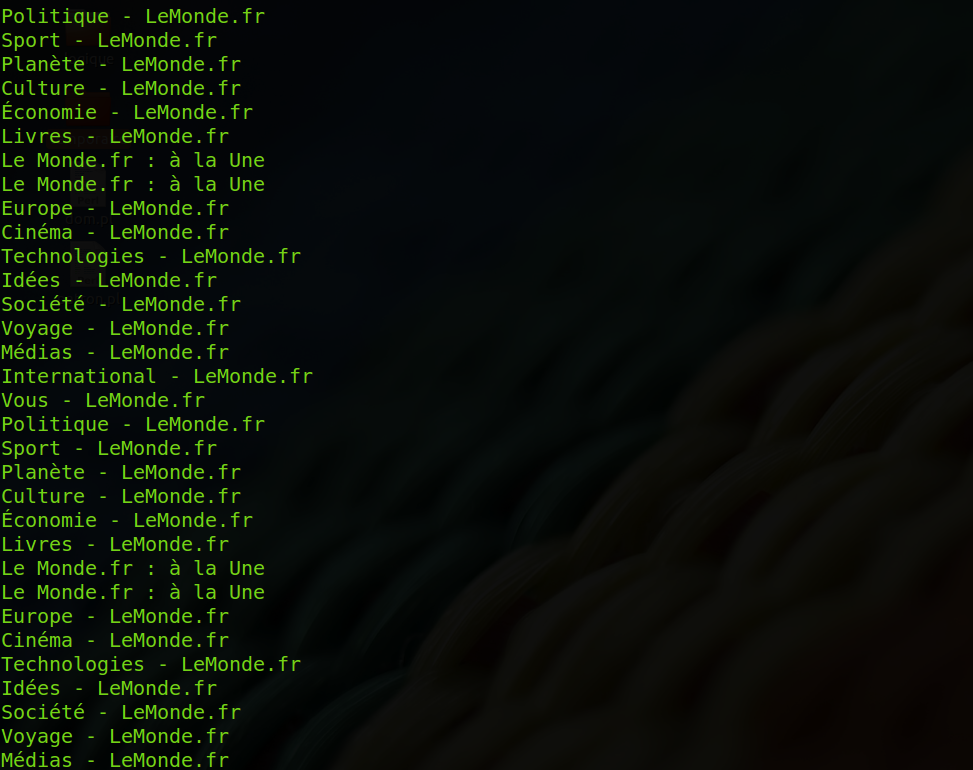
Résultats BAO1
On obtient un série de fichiers, classés par dossiers portant chacun un nom de rubrique
Remarque : le programme a aussi été testé sur l'année 2008 et obtient d'aussi bons résultats.
Tableau Récapitulatif
On trouvera aussi l'ensemble des résultats classés ci-dessous.
Remarque : certains fichiers portant le même nom n'ont pas extrait les balises dans le même ordre. Le classement des balises n'est donc pas le même, (cas typique de xmlrss). L'autre possibilité étant que certaines balises n'aient pas été "matchées" par certaines RegExp. Les cas semblent heureusement rares car sur 25 tests effectués de recherche de titre dans un fichier xmlrss puis dans les fichiers txt, seul deux des test montrent un échec d'une méthode ou d'une autre. A l'exception des fichiers de rubrique ACTUALITE_A_LA_UNE qui semblent ceux pour lesquels l'extraction semble avoir mieux marché avec la méthode Xml::Rss. De ce point de vue cette dernière semble donc plus efficace. Les cas récurrents d'échecs se trouve uniquement concentré dans les fichiers de fin, dossier type "A_LA_UNE" encore qu'il faille vérifier, pour prouver cet échec, chaque fichier pour rechercher chaque balise potentiellement extraite par une méthode et vérifier qu'elle le soit aussi par une autre méthode ce qui n'est guère envisageable.
| CINEMA |
| 0,2-3476,1-0,0 |
| html |
| txt |
| xml |
| rsstxt |
| CINEMA_TOUTE_L'ACTUALITE_SUR |
| 0,2-3476,1-0,0 |
| html |
| txt |
| xml |
| rsstxt |
| CULTURE |
| 0,2-3246,1-0,0 |
| html |
| txt |
| xml |
| rsstxt |
| CULTURE_TOUTE_L'ACTUALITE_SUR |
| 0,2-3246,1-0,0 |
| html |
| txt |
| xml |
| rsstxt |
| ÉCONOMIE |
| 0,2-3234,1-0,0 |
| html |
| txt |
| xml |
| rsstxt |
| ÉCONOMIE_TOUTE_L'ACTUALITE_SUR |
| 0,2-3234,1-0,0 |
| html |
| txt |
| xml |
| rsstxt |
| EUROPE |
| 0,2-3214,1-0,0 |
| html |
| txt |
| xml |
| rsstxt |
| EUROPE_TOUTE_L'ACTUALITE_SUR |
| 0,2-3214,1-0,0 |
| html |
| txt |
| xml |
| rsstxt |
| IDEES |
| 0,2-3232,1-0,0 |
| html |
| txt |
| xml |
| rsstxt |
| IDEES_TOUTE_L'ACTUALITE_SUR |
| 0,2-3232,1-0,0 |
| html |
| txt |
| xml |
| rsstxt |
| INTERNATIONAL |
| 0,2-3210,1-0,0 |
| html |
| txt |
| xml |
| rsstxt |
| INTERNATIONAL_TOUTE_L'ACTUALITE_SUR |
| 0,2-3210,1-0,0 |
| html |
| txt |
| xml |
| rsstxt |
| LIVRES |
| 0,2-3260,1-0,0 |
| html |
| txt |
| xml |
| rsstxt |
| LIVRES_TOUTE_L'ACTUALITE_SUR |
| 0,2-3260,1-0,0 |
| html |
| txt |
| xml |
| rsstxt |
| MEDIAS |
| 0,2-3236,1-0,0 |
| html |
| txt |
| xml |
| rsstxt |
| MEDIAS_TOUTE_L'ACTUALITE_SUR |
| 0,2-3236,1-0,0 |
| html |
| txt |
| xml |
| rsstxt |
| PLANETE |
| 0,2-3244,1-0,0 |
| html |
| txt |
| xml |
| rsstxt |
| PLANETE_TOUTE_L'ACTUALITE_SUR |
| 0,2-3244,1-0,0 |
| html |
| txt |
| xml |
| rsstxt |
| POLITIQUE |
| 0,57-0,64-823353,0 |
| html |
| txt |
| xml |
| rsstxt |
| POLITIQUE_TOUTE_L'ACTUALITE_SUR |
| 0,57-0,64-823353,0 |
| html |
| txt |
| xml |
| rsstxt |
| SOCIETE |
| 0,2-3224,1-0,0 |
| html |
| txt |
| xml |
| rsstxt |
| SOCIETE_TOUTE_L'ACTUALITE_SUR |
| 0,2-3224,1-0,0 |
| html |
| txt |
| xml |
| rsstxt |
| SPORT |
| 0,2-3242,1-0,0 |
| html |
| txt |
| xml |
| rsstxt |
| SPORT_TOUTE_L'ACTUALITE_SUR |
| 0,2-3242,1-0,0 |
| html |
| txt |
| xml |
| rsstxt |
| TECHNOLOGIES |
| 0,2-651865,1-0,0 |
| html |
| txt |
| xml |
| rsstxt |
| TECHNOLOGIES_TOUTE_L'ACTUALITE_SUR |
| 0,2-651865,1-0,0 |
| html |
| txt |
| xml |
| rsstxt |
| VOUS |
| 0,2-3238,1-0,0 |
| html |
| txt |
| xml |
| rsstxt |
| VOUS_TOUTE_L'ACTUALITE_SUR |
| 0,2-3238,1-0,0 |
| html |
| txt |
| xml |
| rsstxt |
| VOYAGE |
| 0,2-3546,1-0,0 |
| html |
| txt |
| xml |
| rsstxt |
| VOYAGE_TOUTE_L'ACTUALITE_SUR |
| 0,2-3546,1-0,0 |
| html |
| txt |
| xml |
| rsstxt |
| ACTUALITE_A_LA_UNE |
| 0,2-3208,1-0,0 |
| html |
| txt |
| xml |
| rsstxt |
| 0,2-3404,1-0,0 |
| html |
| txt |
| xml |
| rsstxt |
| _A_LA_UNE |
| 0,2-3208,1-0,0 |
| html |
| txt |
| xml |
| rsstxt |
| 0,2-3404,1-0,0 |
| html |
| txt |
| xml |
| rsstxt |
A propos de la BAO 1
Script Bao1
Script, liens de téléchargement
Résultats BAO1
Retour au sommaire