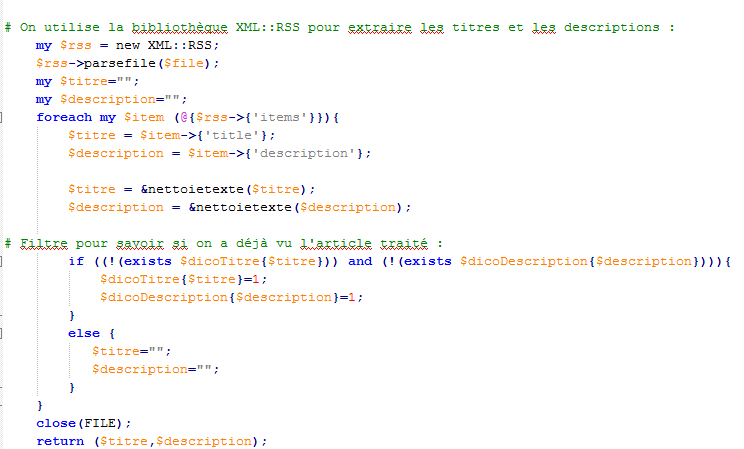
Boîte à outils 1: extraction
La première étape du Projet encadré consiste à
extraire les
informations à partir de l'arborescence des fils RSS du journal "Le
Monde" de l'années 2013 collectés tous les jours à 19h (corpus 2013).
Ils sont au format xml et txt. Pour l'extraction on ne va s'intéresser
qu'aux fichiers au format xml car l'extraction va se faire grâce aux
balises <title> et <description> (les informations qui nous
intéressent).
La bibliothèque XML::RSS de Perl va me permettre de réaliser cette
tâche pour obtenir à la fin un fichier xml avec le titre et la
description de tous les fils RSS pour chaque rubrique (A la une,
Internationnal, Politique...). On peut aussi réaliser cette tâche en
utilisant des expression régulières on produira en sortie des fichiers
aux format txt avec les titres et descriptions. Tous les fichiers
seront encodé en utf-8.
Pour réaliser cette extraction nos enseignants nous ont fourni un
programme de parcours d'arborescence sommaire que nous avons amélioré
pour réaliser l'extraction. Vous pouvez trouver le script de parcours
de départ ==> ici
Le principe de la procédure de parcours est que étant donné des
fichiers rangés dans plusieurs dossiers classés par mois si le
programme tombe sur un répertoire il continue le parcours de
l'arborescence si c'est un fichier il le traite et tout ça de manière
récursive jusqu'à ce qu'il est parcouru toute l'arborescence.