Boîte à outils 2: étiquetage
L'objectif de la BAO2 est d'étiqueter les données textuelles extraites lors de la BAO1. On parle bien d'etiquetage morpho-syntaxique en part of speech (parties du discours) et pour se faire on va utiliser deux outils: Tree-tagger et Cordial. Cordial est un logiciel qui prend en entrée des fichiers au format txt cependant il faudra convertir nos fichiers txt produits en BAO1 en iso-latin après tout le mal que l'on s'est donnée pour qu'il soit en utf-8. Cordial génère en sortie un fichier texte avec 3 colonnes (forme, lemme, catégorie). Tree-tagger lui se lance en ligne de commande il faudra donc l'intégrer à un script et le lancera sur les fichiers au format XML.
étiquetage cordial
Comme dit précedemment avec Cordial il faut dans un premier temps convertir les fichiers que l'on veut étiqueter en iso-latin. Pour cela, on peut procéder de différentes manières. On peut procéder: manuellement à l'aide d'un logiciel comme Notepad ou Word en choisissant l'encodage; en utilisant la commande "iconv" sous Linux. Pour l'utiliser sous Windows on peut télécharger une version d'iconv à cette adresse : https://code.google.com/p/
La commande iconv fonctionne de cette façon: iconv -f inputencod -t outputencod input file > output file
Après cette conversion il suffit d'ouvrir le fichier dans Cordial et sélectionner dans le menu "Syntaxe" "Etiquetage du texte puis sélectionner les paramètres qui nous intéressent.
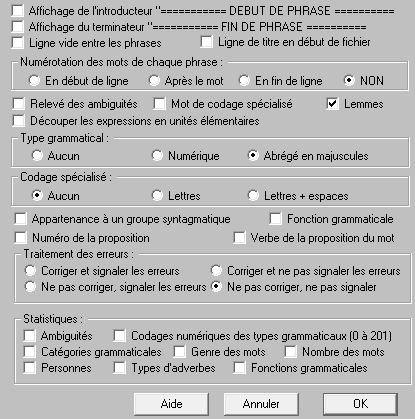
Le résultat obtenu est un fichier au format cnr qui est sous forme de colonnes avec le token (le mot) à la première colonne puis le lemme et enfin la catégorie syntaxique. Vous trouverez un exemple de sortie Cordial ci-dessous.
