

Boite à Outils n°1, aka BàO 1
But de la manoeuvre
La toute première étape de ce projet encadré consiste à extraire le texte sur lequel nous allons travailler par la suite.
Dans le cas présent, les éléments qui nous intéressent sont les titres et les quelques lignes de descriptions sur les articles. Cela veut dire que les pubs, les images, et tout autre élément qui va venir parasiter notre texte doit être laissé de côté. Nous ferons quand même un écart en gardant la date, ça peut toujours être utile...
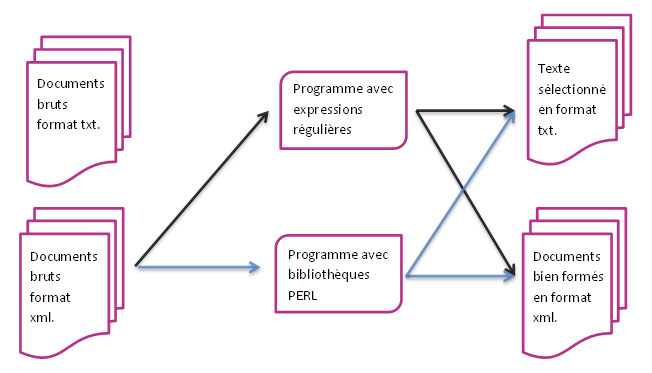
Cette BàO, comme toutes les autres, nécessite la création de deux programmes et va produire deux résultats différents en sortie. L’un des programmes à écrire ne doit utiliser que des expressions régulières, alors que dans l’autre il va nous être possible de faire appel à des bibliothèques PERL qui vont nous aider à gérer le contenu des fichiers. Que cela soit pour l’un ou l’autre des programmes, ils devront tous les deux produire un document texte et un document xml en sortie.
Un pied devant l'autre, et bientôt...
Le programme va donc s’exécuter en plusieurs étapes :
1. Ouverture des fichiers d’entrée et de sortie,
2. Lancement du parcours de l’arborescence de notre dossier de l’année 2013.
En effet, nous souhaitons travailler sur les fichiers, les dossiers en eux même ne sont que des tiroirs qu’il faut ouvrir !
3. Extraction et formatage du contenu textuel
Une fois les fichiers atteints, il nous faut extraire le texte qui nous intéresse (encore une fois, nous ne voulons que les titres et les descriptions avec la date), et s’assurer que tout soit dans le bon encodage, à savoir l’UTF8. De plus, comme nous ne voulons pas que des caractères mal encodés se baladant un peu partout, il nous faut aussi faire passer le texte dans un filtreur pour régler ce point.
4. Formation des fichiers biens formés
Une fois que nous avons le texte, nous devons nous assurer que les fichiers sont bien formés. La question n’est pas d’une importance primordiale dans le cas du fichier en format texte, mais doit bel et bien être pris au sérieux dans le cas du document en format xml. Cela veut dire qu’il faut penser à la déclaration du document, à la balise racine au début et à la fin, à la délimitation entre les articles, les différents jours de publications, et bien sur des balises pour les titres et les descriptions.
Mais (parce qu'il y a un mais), quelque problèmes sont à résoudre ou à anticiper.
Au vu des différentes étapes de cette BàO, on comprend rapidement que ce n’est pas une mince affaire, et bien évidement nous avons rencontré quelques soucis. Tous résolus, on vous rassure !
1. L’utilisation des rubriques
Étant donné que nous ne souhaitions pas avoir TOUT le corpus dans un seul et même fichier de sortie (oui, on sait, c’est plus facile, mais on ne peut pas le faire quand même), nous avons décidé d’utiliser le nom des rubriques pour renommer chacun de nos fichiers de sortie. Pour se faire, nous avons utilisé une table de hachage qui associe un titre à chaque code de rubrique. Une autre méthode possible revient à ne pas utiliser une table de hachage, mais à aller cherche le nom de la rubrique directement entre les bonnes balises dans le fichier source.
2. Les doublons
Étant donné que par la suite nous souhaitons faire une analyse de notre texte, nous n’avons aucun intérêt à garder deux fois le même élément ! En soit cela revient à enregistrer le titre et/ou la description dans un dictionnaire, et à chaque nouvel élément, à aller vérifier si notre dictionnaire n’a pas déjà enregistré celui-ci. Si l’élément n’est pas enregistré, alors il le traite et l’ajoute au dictionnaire, sinon il ne fait rien et passe à la suite. Rien de bien compliqué, mais il faut tout de même y penser.
3. L’encodage
Comme nous l’avons précisé, nous souhaitons obtenir des fichiers en utf8. Oui mais voilà, tous nos fichiers d’entrer ne le sont pas, en utf8, ce qui implique une conversion à un moment ou à un autre dans le programme ! Pour cela, il est possible de faire une procédure complètement dédiée à cette action, mais il est également possible de l’indiquer au moment du formatage de la sortie. Nous avons préféré la deuxième solution, même si elle implique d’avoir un filtreur plus performant.
4. La formation des documents
Comme cela a été précisé dans la description des étapes de la BOT1, il est important d’avoir des documents xml bien formés en sortie. Cela veut dire que la déclaration document ainsi que la balise racine ne doivent être présent qu’une seule fois. Si on utilise des procédures, on va donc préférer mettre ces lignes tout au début, en dehors des boucles qui sont faites pour répéter des actions. Pour ce qui est de la balise qui définit une journée, elle doit être présente autant de fois que nécessaire, ce qui implique, encore une fois, qu’elle soit placée au bon endroit.
Comme pour les doublons, la procédure de codage n’est pas difficile. Néanmoins il faut tout de même prendre du recul avant de faire quoi que ce soit, sous peine de se retrouver avec un document xml contenant des balises qui n’ont absolument aucun sens.
5. Les bibliothèques PERL
Même si, de prime abord, les bibliothèques peuvent grandement nous faciliter la vie, elles nécessitent tout de même un minimum de compréhension pour être utilisées de façon efficace. En effet, une bibliothèque va contenir plusieurs fonctions (normal me direz-vous), mais il faut savoir quelle fonction appeler, par quel nom, avec quels inputs et quel format de sortie choisir. Un fois tout ça compris, et pris en compte, il est certain qu’une bibliothèque est un vrai coup de pouce.
6. L’optimisation
Jusqu’à présent, nous n’avons pas vraiment été amené à prendre en compte l’optimisation d’un programme, néanmoins rejetons un petit coup d’œil à ce que nous traitons : environ 365 dossiers, chacun contenant 17 fichiers encodés en xml, pouvant produire jusqu’à 1700Ko de données intéressantes par année et par rubrique pour nous. Tout cela étant quand même assez lourd à traiter, on ferra attention à optimiser les actions du programmes pour éviter les répétitions alors qu’elles peuvent être évitées.
7. L’expression régulière pour la version regexp
Contrairement à ce que l’on pourrait penser, le programme qui nous a donné le plus de fils à retordre est celui n’utilisant pas les bibliothèques PERL. En effet, comme on ne peut pas faire appel à une fonction pour aller chercher les éléments souhaité, il est primordial que l’expression régulière soit bien réfléchie ! Cela implique de connaître l’architecture de notre fichier, de savoir précisément ce que l’on veut, et où aller le cherche, tout ça dans le but d’avoir une extraction la plus propre possible.
Vous pouvez télécharger les résultats ici .
Next!
Il est évident que nous n’allons pas nous arrêter en si bon chemin ! La BOT2 aura donc pour but d’étiqueter le texte que nous avons extrait. Pour cela il nous faudra utiliser le logiciel CORDIAL pour le format texte et TREETAGGER pour le format xml !
Pour en savoir plus sur cette étape, rendez-vous ici !