

Boîtes à Outil n°3, aka BàO3
Vous avez dit changement?
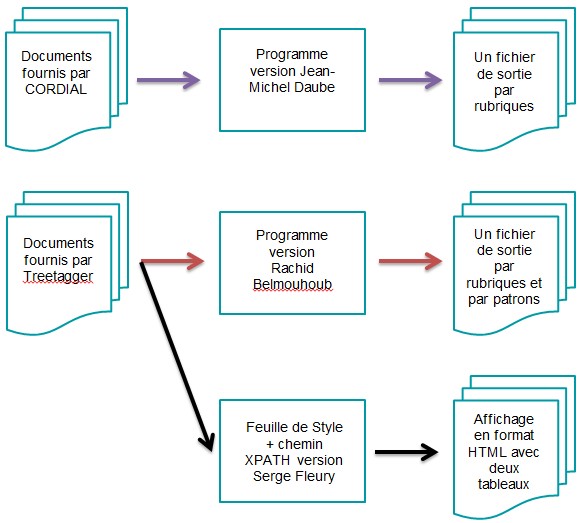
Puisque la dernière étape a eu pour but d’étiqueter chaque fichier résultat, il nous faut maintenant extraire les données en suivant des patrons morphosyntaxiques. Étant donné que les sorties de Cordial et de Treetagger ne sont pas les mêmes, les approches exposées vont être différentes. Ce sont ces dernières que nous allons exposer ici !
Nouvelles données, nouveau cahier des charges!
Pour une fois, nous n’allons pas expliquer 2, mais 3 méthodes différentes de procéder ! La première méthode va nous permettre d’extraire les données des fichiers créés par Cordial, la deuxième méthode va faire de même avec les sorties de Treetagger, et enfin la dernière méthode va faire appel à une feuille de style xsl et à une requête XPATH pour extraire les patrons à partie de la sortie Treetagger.
Première méthode : Avec les sorties de Cordial
Comme nous l’avons déjà expliqué, les sorties de Cordial sont en format txt. et se présente de la façon suivante :
[lemme] [tabulation] [forme] [tabulation] [étiquette]
On remarque donc que l’élément délimiteur dans les fichiers est la tabulation est c’est ce que nous avons exploité. Nous avons donc effectué les sélections qui s'imposaient.
Dans le cadre de nos recherches, nous avons décidé d’extraire les patrons de type :
- NOM_ADJ
- NOM_PREP_NOM
- NAM_NAM
Ainsi, en suivant les patrons donnés, il semble impossible d’obtenir un résultat de type NOM_ADJ_ADJ… et pourtant, c’est bien ce que nous retrouvons dans le résultat !
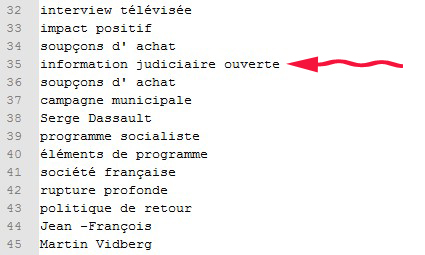
Bizarre, bizarre...
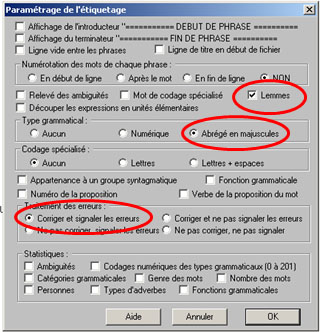
Alors d’où ça vient ?! Un petit retour en arrière à l’étape de l’étiquetage avec Cordial est nécessaire. Dans les choix multiples qu’il nous était possible de faire, nous pouvions cocher cette case :
Et la cochant, on autorise alors Cordial à garder certains groupes de mots et donc à ne pas obtenir exactement ce que nous avions demandé via notre patron. Bien sûr, il est toujours possible de refaire tourner Cordial sur tous nos fichiers, mais nous avons néanmoins fait le choix de garder les choses telles qu’elles. En effet, rappelons le sujet de la BAO4 : nous allons analyser les résultats de toutes nos extractions ! Et lors d’une analyse il est certainement plus cohérent d’avoir une expression dans sa totalité plutôt qu’une partie qui va s’avérer bien plus compliquée à analyser.
Notons néanmoins un petit bémol : visiblement, Cordial fait ses groupes de mots en se basant sur un dictionnaire qu’il doit avoir à disposition… et ce dictionnaire est loin d’être complet. Ainsi, il pourra parfois prendre un groupe de mots puisqu’il le reconnait dans son dictionnaire, mais pas un autre qui semble pourtant tout à fait similaire, tout simplement parce qu’il ne le reconnaitra pas.
Les résultats sont téléchargeables ici pour l'étiquetage des fichiers ".txt".
Deuxième méthode : Avec les sorties de Treetagger
Dans le cadre d’un fichier qui a été créé par Treetagger, il est évident que le séparateur n’est pas la tabulation, mais la balise qui va déterminer la nature du contenu et donc ce que nous voulons extraire.
Nous avons extrait exactement la même chose que dans le cadre de Cordial (Allé, rappelons-le pour la forme : NOM_ADJ, NOM_PREP_NOM, et NAM_NAM), et nous avons obtenu un résultat qui est tout à fait similaire qu’avec le résultat de Cordial … les groupes de tokens clandestins en moins. Nous avons également fait le choix d’avoir tous les résultats d’extraction de Cordial dans le même fichier de sortie, alors que pour les extractions de Treetagger, nous créons un fichier résultat par rubrique et par patron.
Le script que nous avons produit est basé sur la solution proposée par Monsieur R. Belmouhoub.
Les résultats sont téléchargeables ici pour l'étiquetage des fichiers ".xml".
Troisième méthode : Avec une feuille XSL et un chemin XPATH
Dernière méthode pour cette BAO, l’utilisation d’une feuille XSL qui va s’appliqué à notre fichier de sortie Treetagger au format XML, avec une requête XPATH pour aller chercher les patrons qui nous intéressent.
La feuille de style a été fournie par Monsieur Serge Fleury.
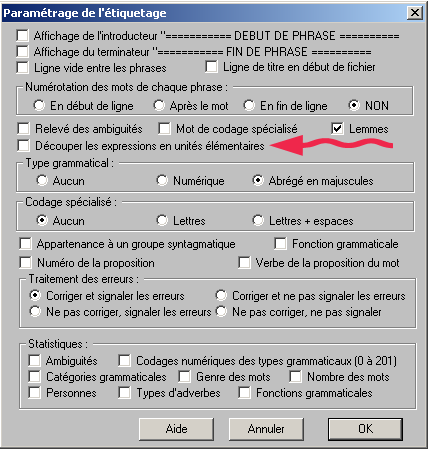
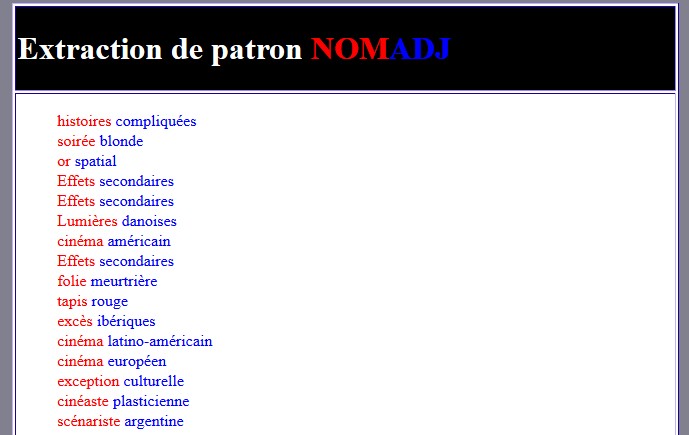
Dans cette feuille de style, il existe deux techniques différentes : une pour les NOM/ADJ et une pour les NOM/PRP/NOM. Et pour les comprendre, quelques explications s’imposent. Pour NOM/ADJ tout d’abord :
On se place tout d’abord au bon endroit dans le document, chaque chemin étant propre à chacun :
On commence l’introduction de la condition:
Littéralement, lorsque l’élément contenu dans “data” a pour etiquette “NOM” et que son frère suivant a pour etiquette “ADJ”…
Alors on le garde et on le met en rouge
On met un espace
Encore une fois, lorsque l’élément contenu dans “data” a pour étiquette “ADJ” et que son frère précédent est un “NOM”…
Alors on le garde et on le met en bleu
Dans le cas du patron NOM/PREP/NOM, on ne choisit pas d’utiliser « when », mais plutôt « if », ce qui donne la chose suivante :
Encore une fois on se place tout d’abord au bon endroit dans le document, chaque chemin étant propre à chacun :
Si notre recherche trouve un élément contenant l’étiquette “NOM”…
Alors on le garde er on lui donne la valeur “p1”.
Si l’élément suivant notre « NOM » déjà sélectionné est une préposition « PRP »…
Alors on le garde en lui donnant la valeur “p2”
Enfin si l’élément suivant le NOM et la PRP déjà sélectionné est un NOM…
Alors on le garde en lui donnant la valeur “p3”.
On affiche désormais p1 en rouge…
Un espace…
p2 en bleu…
Un espace …
Et p3 en rouge…
Et on passe au suivant.
Et voilà comment on arrive à avoir les deux extractions sur la même feuille !
Petites précisions tout de même :
- pour pouvoir l’utiliser il est nécessaire de rajouter une ligne dans le document xml concerné pour pouvoir appeler la feuille xsl ;
- avant de dire que ça ne fonctionne pas pour vous, vérifiez bien le chemin utilisé pour aller chercher l’élément « data » (oui, on sait, ça sent le vécu…) ;
- notre méthode est UNE méthode de fonctionner parmi tant d’autres. Il est tout à fait possible d’utiliser une structure en « apply-templates » par exemple !
Et maintenant?
Puisque nous avons tout ce qu’il nous faut, on peut désormais attaquer la dernière BAO pour faire l’analyse de nos extractions et de nos fils RSS !!
Pour la BAO4, rendez-vous ICI !