
Boîte à Outils 2
L'objectif de cette étape est d’étiqueter les données extraites dans l'arborescence. La Boîte à Outils 2 est plus complexe dans le sens que le filtrage et l'extraction se fait sur tous les fichiers par leurs rubriques. A part de l'extraction des titres et des résumés au format TXT et XML, le script applique l'étiquetage morphologique via le Treetagger qui produit dans des fichiers de sortie XML toutes les formes, les lemmes et les catégories des textes extraits précédemment.
Script d'extraction à l'aide des expressions régulières
Nous n'avons pas porté des modifications importantes dans ce script car il était déjà prédéfini. Comme nous avons considéré le module XML::RSS le plus utile, nous nous sommes focalisées sur l'optimisation de ce dernier. Nous avons modifié le reperage des rubriques et nous avons exécuté le script sur le corpus de test (2008). Les résultats obtenus sont fournis ci-dessous.
Télécharger
Script d'extraction à l'aide du XML::RSS
Cette version se base sur l'utilisation du module XML::RSS. Il produit trois types de fichiers :
- Fichiers TXT et fichiers XML triés par rubrique et contenant les textes extraites à partir des balises <title> et <description>. Les fichiers TXT seront étiquettes via le Cordial, les fichiers XML seront traité directement par le script de la BAO3. Il faut noter que les fichiers de sortie TXT doivent être encodés en ISO-8859-1.
- Fichiers XML étiquetés via les commandes du Treetagger, contenant les formes, les lemmes et les catégories des textes extraits à partir des balises concernées.
Le traitement de tous les fichiers des fils RSS 2013 nous a durée 2 jours. Afin de lancer le script, nous l'avons testé sur quelques échantillons des fils 2008. En résultat, environ 10-15% des textes n'ont pas été repérés.
Nous avons testé plusieurs fonctions qui transcode les textes en ISO-8859-1 mais cela n'a rien changé. Dans notre script, cela a suffit d'indiquer cet encodage au moment de l'ouverture du fichier de sortie TXT. Les résultats finals produits étaient bien codés en ISO-8859-1 et traités facilement par le Cordial.
La partie importante pour nous était la normalisation des noms des rubriques afin de les utiliser en tant que les noms pour les fichiers de sortie TXT.
Afin de normaliser les caractères spéciaux et accentués dans les noms des rubriques, nous avons importé le module Unicode::Normalize.
Dans la ligne ci-dessus, NFD est la forme définie fourni par le standard Unicode. Ceci dit, la fonction NFD décompose des lettres et des caractères spéciaux dans des lettres de base.
La partie importante du script est la procédure treeTag qui étiquettes les tokens des textes extraits dans la procédure. Dans la procédure recurseTousFics, le programme fait appel à treeTag pour récupérer les catégories, les lemmes et les formes en traitant le couple des textes "titre-résumé". Les couples sont successivement écrits dans les fichiers de sortie TREETAG XML.
La procédure treeTag est divisé en deux parties : l'extraction des titres et l'extraction des résumés. Le contenu textuel (les résultats de sortie) est stocké dans le fichier temporaire $tmptag et traité par les scripts d'étiquetage du Treetagger. La segmentation et l'étiquetage s'appliquent sur chaque mot par ligne qui est concaténée dans la variable $titreTag.=$l (c'est pareil pour la partie des résumées). Le schéma est le suivant : tree-tagger [options] <paramètres> <TEXTE-IN> <TEXTE-OUT>
La deuxième partie de la procédure correspond à l'étiquetage des résumés extraits. A la fin, la procédure renvoie la couple des textes contenant les étiquetages morphosyntaxiquues.
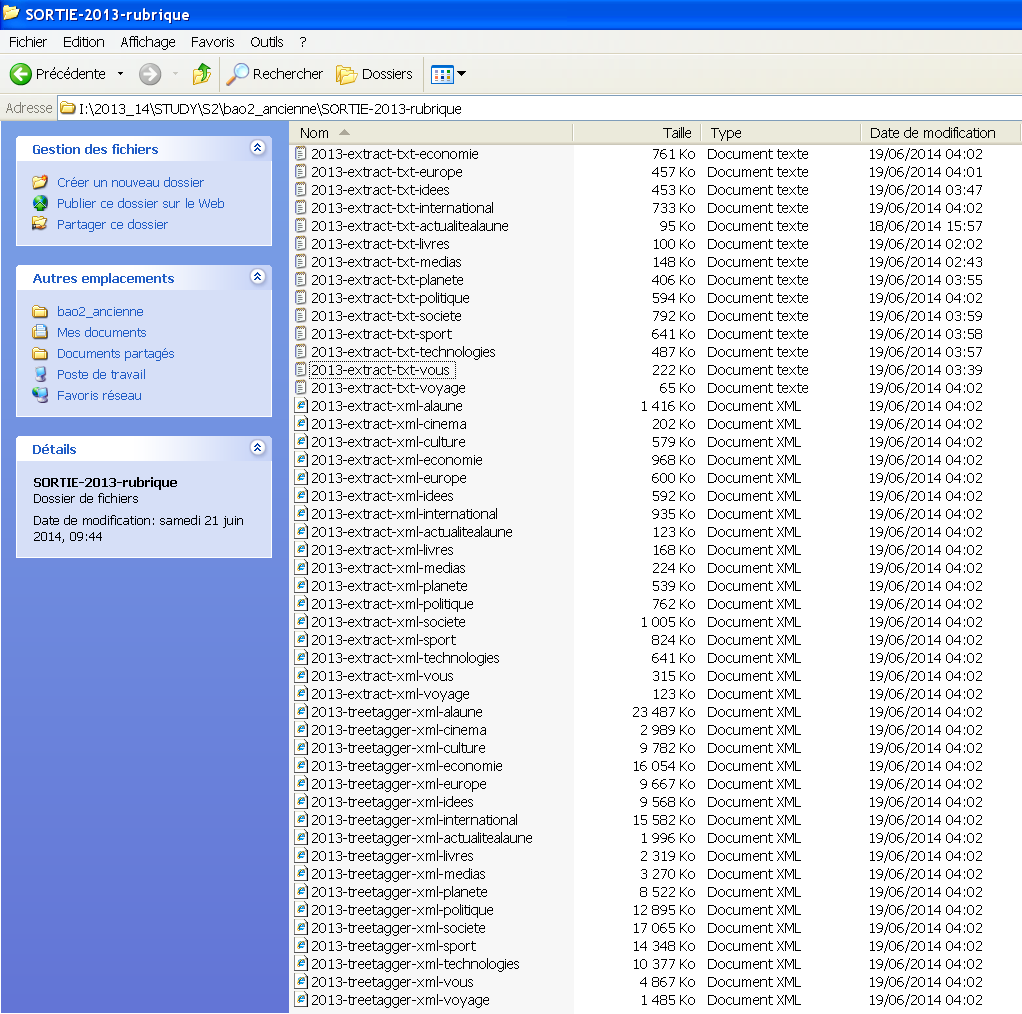
Après la traitement du script, nous avons obtenu l'ensemble des fichiers triés par rubrique, par extensions, par sorties "titre-rubrique" et par l'étiquetage morphosyntaxique.
Pour visualiser les sorties "titre-rubrique" dans les fichiers XML, nous avons rédigé la feuille de style XSLT qui, en utilisant les requêtes XPATH, extrait dans les balises HTML les suites étiquetés par fichier.
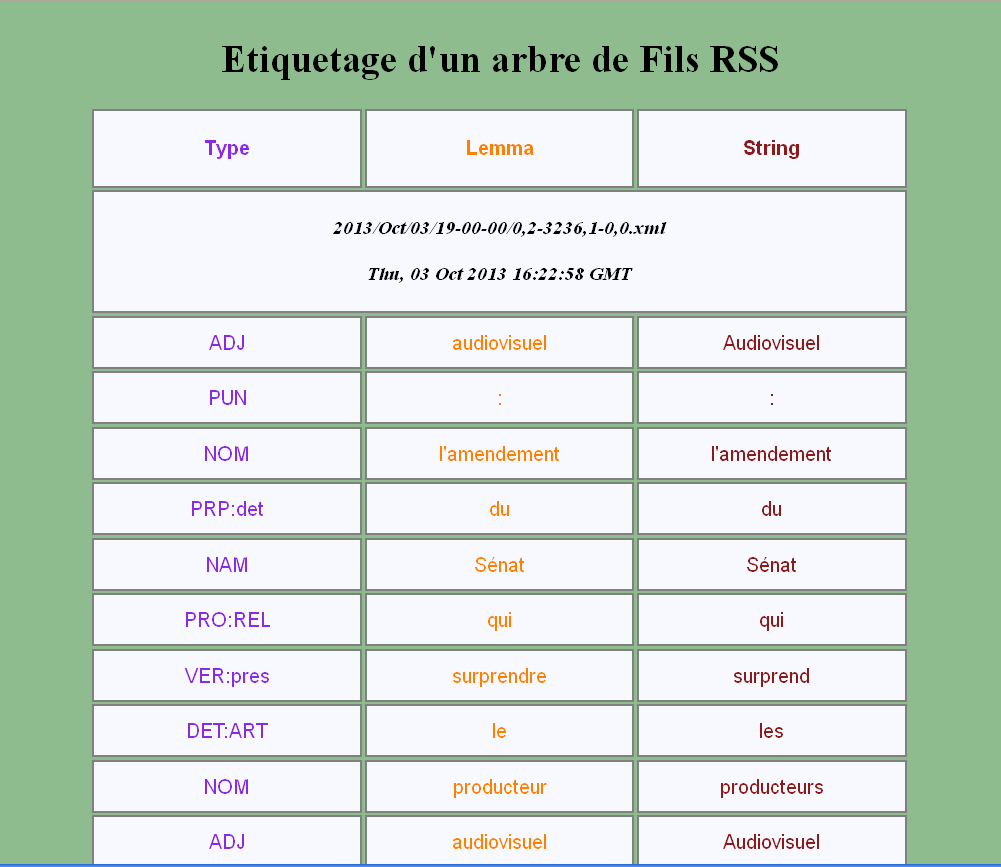
La partie principale de la feuille XSLT consiste du repérage du contenu textuel d'après les attributs des éléments 'type', 'lemma' et 'string' :
<xsl:value-of select="data[@type='type']"/><xsl:text> </xsl:text>
<xsl:value-of select="data[@type='lemma']"/><xsl:text> </xsl:text>
<xsl:value-of select="data[@type='string']"/><xsl:text> </xsl:text>
Télécharger
- Script RSS
- Sortie-2013-medias TXT RSS
- Sortie-2013-medias XML RSS
- Sortie-2013-medias-treetag XML RSS
- Étiquetage XSLT
- Sortie-medias HTML
- CSS
Remarques
Étant donnée que le traitement du dossier 2013 (assez grand) a pris deux jours, nous nous sommes posées la question de quelle façon peut-on éviter les tâches peu importantes. Est-ce que cela serait mieux d'effectuer un pré-traitement pour repérer des rubriques et préparer tous les fichiers pour l'écriture qui se fera en une seule fois, avant de lancer les tâches d'étiquetage et d'extraction ? Cela donne matière à réfléchir.