
Boîte à Outils 3
La Boîte à Outils 3 concerne le traitement des résultats obtenus dans la BAO2. Les deux scripts proposés en cours par Jean-Michel Daube, Serge Fleury et Rachid Belmouhoub permettent d'extraire les patrons sur les sorties brutes de l'étiquetage via le Cordial et sur les sorties au format XML de l'étiquetage via le Treetagger respectivement.
Pour étiqueter les données extraites dans l'arborescence, nous utilisons le logiciel d’étiquetage Cordial. Cordial permet de générer un fichier texte avec 3 colonnes (forme, lemme, catégorie) a la sortie. L’incommodité du logiciel Cordial c’est que il est payant et il ne fonctionne que sous le Windows et ne marche que dans l'encodage ANSI. C’est aussi impossible de travailler avec des gros fichiers.
Nous n'allons pas nous reposer sur la manipulation du Cordial car il suffisait d'ouvrir le logiciel, charger le fichier de sortie TXT, sélectionner Syntaxe, décocher tous les cases sauf :
- NON
- Lemmes
- Abrégé en majuscules
- Ne pas corriger, ne pas signaler
Après, il faut cliquer OK. Nous avons ensuite enregistré chaque fichier sous le format .CNR et lancé l'étiquetage.
Script d'extraction de patrons : sorties CRN
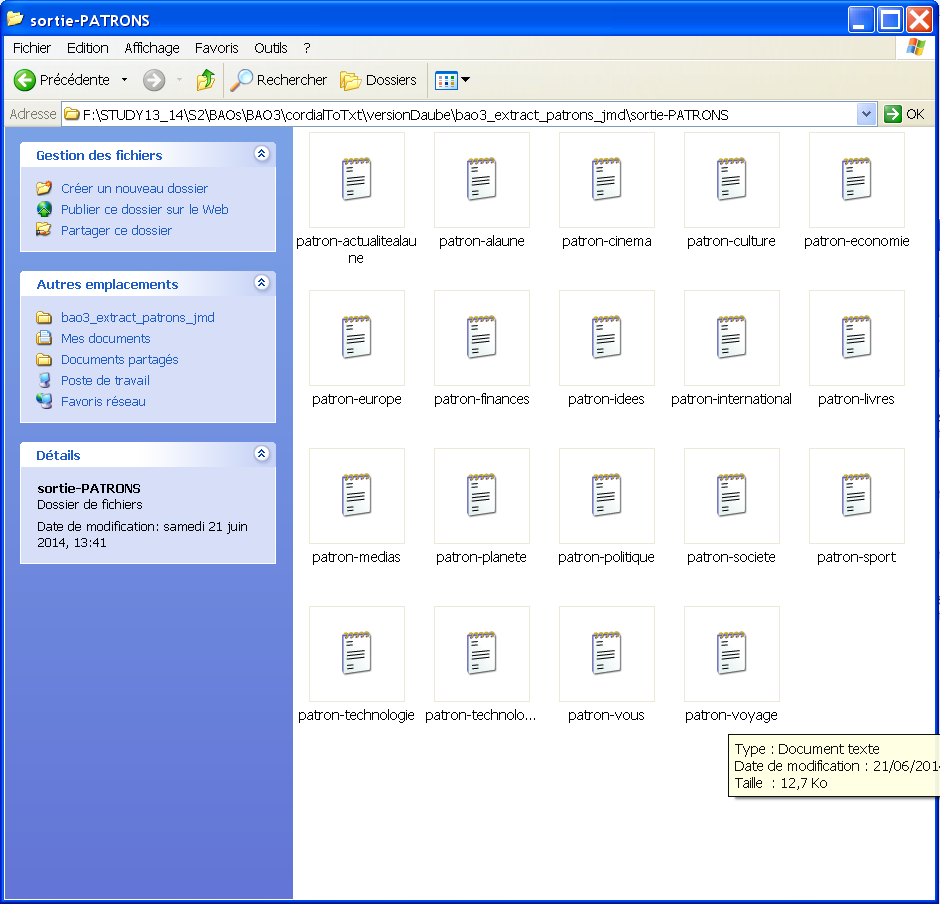
Le programme prend en argument le nom du répertoire (dans lequel se trouvent les fichiers CNR) et le nom de fichier dans lequel l'utilisateur indique les motifs recherchés. Il crée et écrit les suites des patrons extraits dans les fichiers de sortie nommés d'après les rubriques dans le dossier sortie-PATRONS.
Dans notre cas, nous avons recherché NOM ADJ et NOM PREP NOM:
Nous avons réutilisé la procédure du parcours des fichiers recurseTousFics. A part du repérage des fichiers, le programme extrait les noms des rubriques à partir de leurs noms et les assignes en tant que noms pour les fichiers de sortie. Afin de copier l'impression (STDOUT) des patrons par l'instruction print, nous avons introduit le fichier LOG pour chaque fichier CNR de l'arborescence.
Après la lecture du fichier CNR, le programme stocke le token, la lemme et la catégorie à l'indice 0, 1, 2 de la liste $LISTE. Les compteurs $j et $k assurent l'ordre de l'apparition des patrons. L'instruction select redirige la sortie "@TOKEN[$j..$j+$k]\n"; dans le fichier STDOUT LOG, mentionné ci-dessus.
Au final, le script stocke les fichiers de sortie avec des patrons.
Télécharger
Script d'extraction de patrons XPATH
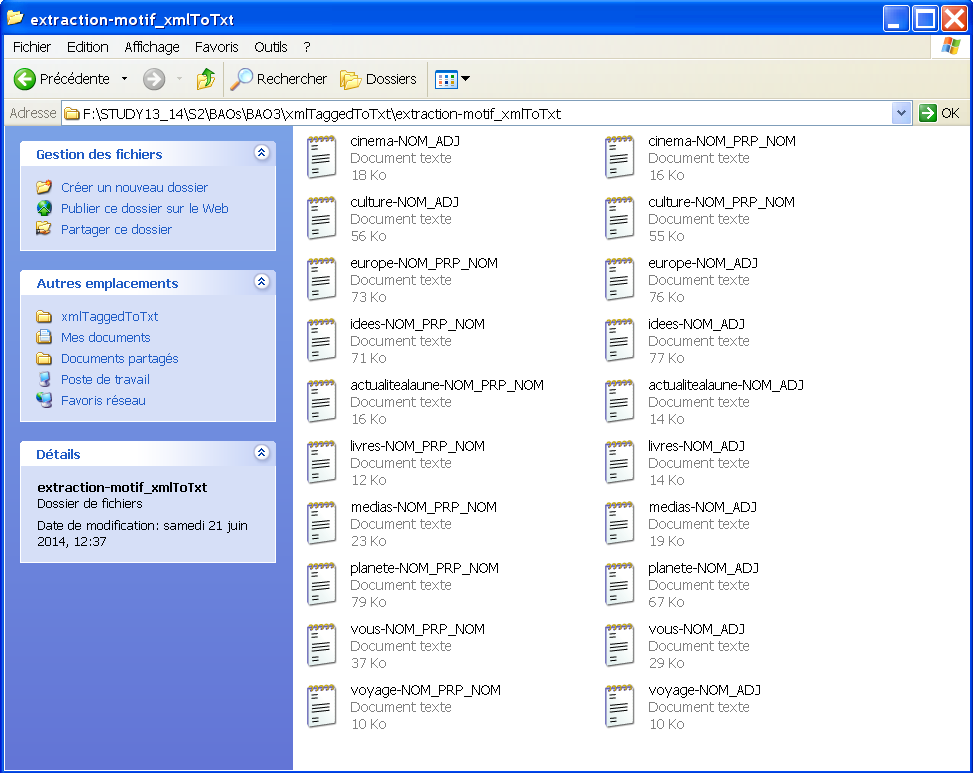
Cette version inclut le module XML::XPath qui permet d'utiliser les requêtes XPATH pour repérer des tokens, des lemmes et des catégories ainsi qu'extraire des motifs qui sont indiqués dans le fichier séparé. Le programme prend 2 arguments : le nom du répertoire des fichiers XML et le fichier qui contient les motifs. Il renvoie des fichiers nommés d'après la rubrique et le motif recherché (un motif par fichier).
La procédure construit_XPath construit le chemin XPATH, la procédure extract_pattern récupère ce chemin et utilise l'objet my $xp = XML::XPath->new( filename => $tag_file ) pour explorer chaque fichier XML. Lors du parcours de cet objet, chaque nœud du fichier XML correspondant au motif recherché est itéré afin de localiser les éléments du motif. Ensuite, les formes extraites sont imprimées dans le fichier MATCHFILE qui est stocké dans le répertoire extraction-motif_xmlToTxt.
Le programme réutilise la procédure recurseTousFics qui permet de lire les fichiers d'entrée XML et effectuer l'extraction des patrons pour chaque fichier.
Les fichiers de sortie PATRON sont stockés dans le répertoire séparé et sont nommés d'après les motifs recherchés.
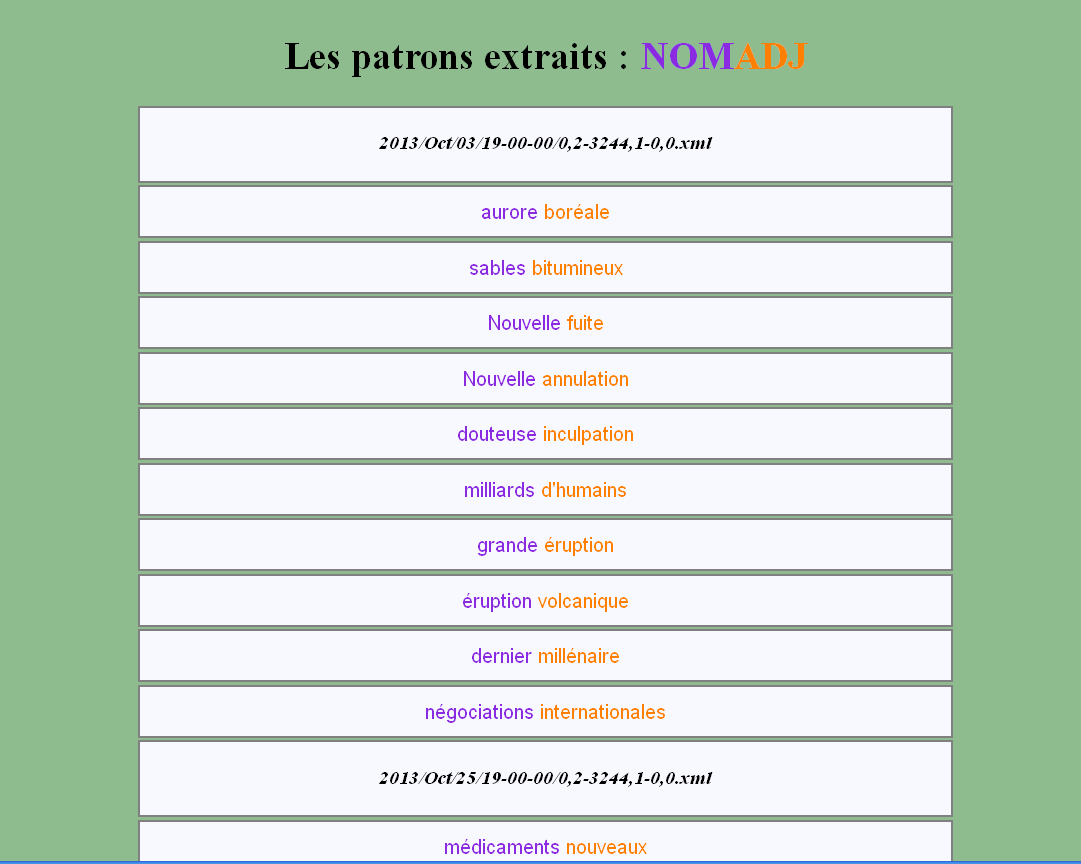
Pour visualiser les listes des patrons, nous avons rédigé deux feuilles de style XSLT pour le fichier XML étiqueté 2013-treetagger-xml-planete. Nous avons fourni les résultats en format HTML pour accélérer l'ouverture des fichiers dans le navigateur. Pour les deux feuilles, il y a des requêtes de repérage et d'extraction pour les noms des fichiers et les éléments de l'étiquetage.
Pour illustrer les requêtes de repérage, la requête pour NOM PRP NOM est ./data[contains(text(),'NOM')] suivie de following-sibling::element[1][./data[contains(text(),'PRP')]] suivie de following-sibling::element[2][./data[contains(text(),'NOM')]].
Pour NOM ADJ, la requête est ./data[contains(text(),'NOM')] suivi de following-sibling::element[1][./data[contains(text(),'ADJ')]].
Pour ADJ NOM, la requête est ./data[contains(text(),'ADJ')] suivie de following-sibling::element[1][./data[contains(text(),'NOM')]]

Télécharger
- Script XPATH
- Sortie-planete TXT NOM-ADJ
- Sortie-planete TXT NOM-PRP-NOM
- Étiquetage XSLT NOM-ADJ
- Étiquetage XSLT NOM-PRP-NOM
- Sortie-planete HTML NOM-ADJ
- Sortie-planete HTML NOM-PRP-NOM
- CSS
Remarques
L'avantage du deuxième script par rapport au premier est la souplesse dans la gestion des fichiers de sortie : chaque fichier contient les patrons qui correspondent à un motif recherché. Le premier script produit seulement des fichiers qui contiennent les patrons pour tous les motifs car le repérage des patrons se fait ligne par ligne.