Analyse du corpus
Présentation du corpus coréen
Le corpus a été collecté le 27 septembre sur trois différents sites de presse coréen. Deux sont plutôt conservateur, le Chosun Ilbo et et le Donga Ilbo. Le troisième est quand à lui un peu plus libéral, le Hankyoreh. Au total, 147 URLs ont été utilisé, et les articles datent tous du 26 et 27 septembre. La méthode de sélection des articles s'est effectuée en tapant le mot 교육 kyoyuk dans la recherche et en prenant les 50 premières URLs dans l'ordre d'apparition. Le choix des articles a été réalisé sans lire les articles au préalable pour ne pas influer dans les résultats.
Une fois les URLs collectés, deux fichiers ont été créé, un fichier DUMP contenant tout le contenu téléchargé de toutes les URLs et un fichier CONTEXTE avec seulement le contexte extrait. Ici le contexte signifie la ligne où apparaît le mot plus deux lignes au dessus et en dessous. D'après le Trameur, il y a 63 746 mots pour le fichier dump, et le mot le plus fréquent est 있다 itta (exister) avec 488 apparitions. Pour le fichier contexte, il y a 21 353 mots et l'occurrence la plus fréquente est 교육 kyoyuk qui apparaît 567 fois.
Les deux fichiers ont été nettoyé à l'aide des fonctions de recherche et de remplacement présentes sur Notepad++ et TextWrangled. Le fichier contexte a principalement été débarassé des bandeaux de pub, et des bandeaux de navigation pour ne garder que le texte qui nous intéressait. À la suite de ce nettoyage, l'analyseur morphosyntaxique et tokenizer HanNanum a été appliqué aux deux fichiers. Après ségmentation des différentes tokens, il a fallu remettre la mise en page originale du fichier car la sortie de HanNanum se faisait sous forme de colonnes. Pour cela, les expressions régulières ont été utilisé pour simplifier la tâche. HanNanum ne ségmentant pas les mots formés à partir de kyoyuk tel que 교육부 kyoyukbu (ministère de l'éducation), une ségmentation à l'aide d'expression régulière a dû être réalisé pour ségmenter les mots de la forme x-kyoyuk-y où x et y étaient des morphèmes. En reprenant l'exemple de 교육부 kyoyukbu pour illustrer, on a maintenant 교육부 qui devient 교육 부.
Analyse 1 : le Trameur


(À gauche le nuage dump et à droite le nuage contexte)
Les nuages de mots ont été réalise à l'aide de Word It Out. Les fichiers ont été importé avant la ségmentation et une liste de mots vides a également été utilisé. Cette liste a été glané à travers internet en en concatenant plusieurs.
Ce qui ressort le plus de ces deux nuages est bien évidemment le vocabulaire lié à l'éducation comme élève, université, école, professeur, programme.
Le nuage pour le dump est un peu plus fouilli avec des mots qui ne se rapportent pas vraiment à l'éducation mais ont une haute fréquence car ce sont les bandeaux de pub, ou boutons de navigation.
Quand au fichier contexte, on voit apparaître des mots proches de l'éducation, comme le champs (d'étude), pourvoir/fournir, chance ou bien le gouvernement, le Saenuri-Dang (parti au pouvoir de la déchue Park GeunHye). On peut aussi noter des mots liés à l'emploi où l'éducation coréenne joue un grand rôle à cause de la compétitivité lié à l'accès à l'emploi.
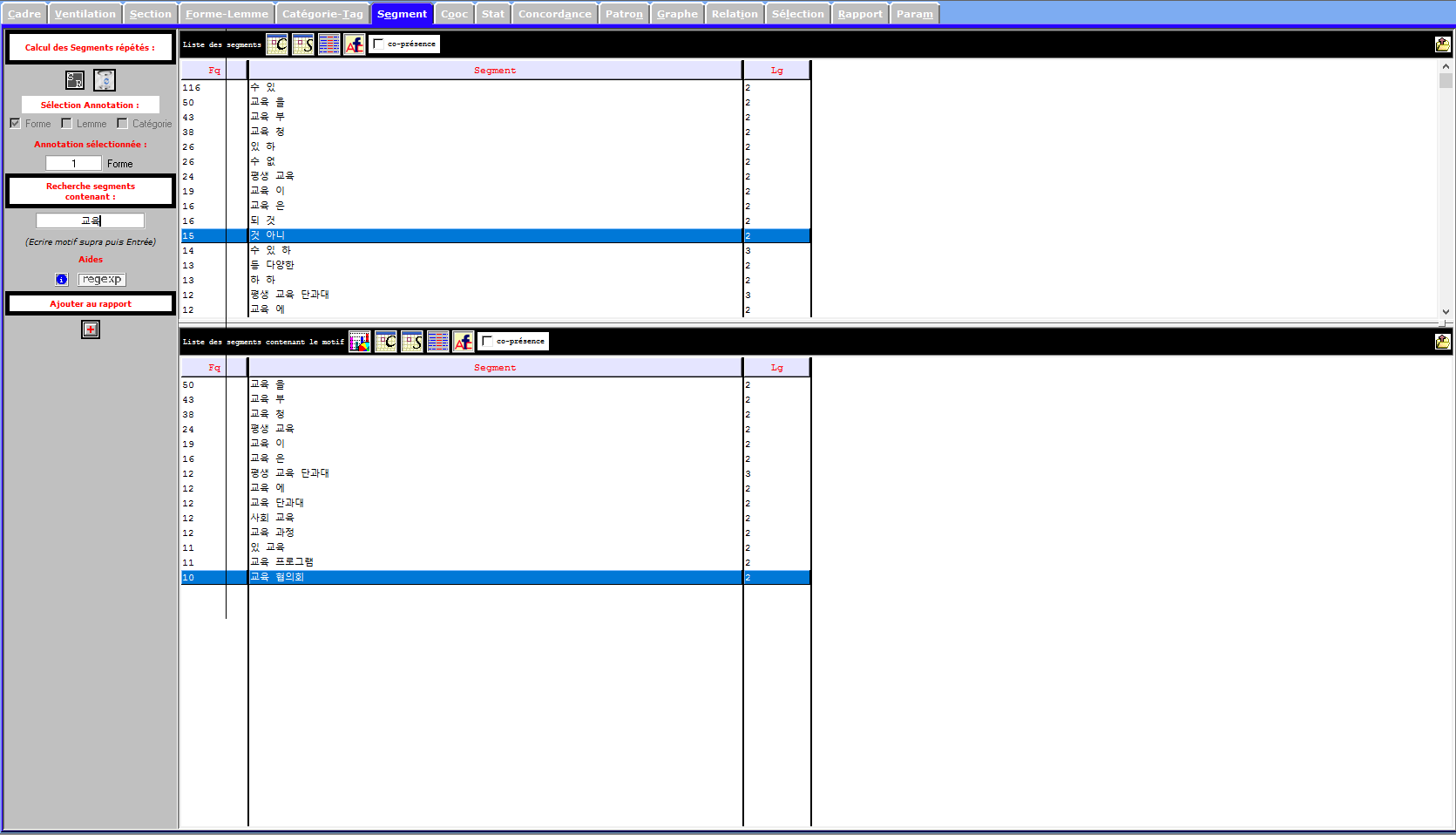
Le trameur a permis de réaliser une seconde analyse avec les fonctions de calcul des cooccurents et la fonction de recherche de segments répétés. Cette dernière fonction nous permet de relever les segments tels que "ministère de l'éducation", "conseil d'éducation", "formation professionnelle continue", "l'éducation sociale/civique", "le processus d'éducation" ou encore "les programmes scolaires". Ces segments répétés semblent plutôt évident lorsque l'on parle éducation où le gouvernement joue un rôle important. La formation continue part du principe qu'il n'est jamais trop tard pour se former, plusieurs centres sont présents en Corée du sud. On peut y recevoir des formations diverses à toutes âges. Ils sont devenus un enjeu dans le paysage éducatif coréen où la quête d'éducation toujours de plus en plus forte. À noter que les programmes scolaires ont une importance ces derniers temps car la déchue présidente souhaitait une réforme des manuels scolaires pour passer au silence certains faits post-colonisation japonaise et ainsi améliorer l'image de son père, dictateur. Plusieurs débats ont donc eu lieu et une levée de bouclier à l'encontre de cette réforme s'est organisée. Néanmoins comme le montre les cooccurents, le mot spécifique pour parler de cette réforme n'apparaît que très peu.
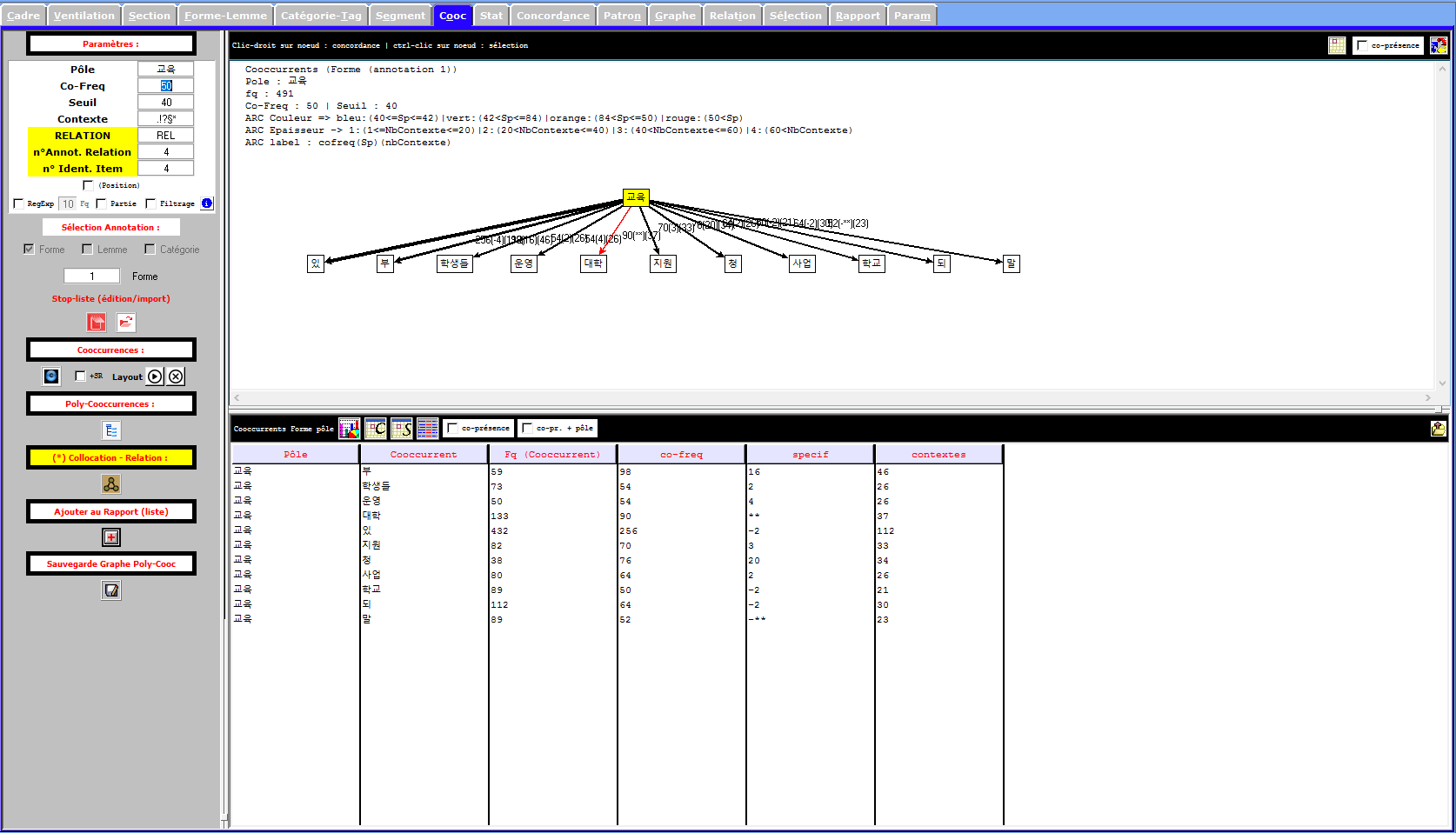
En regardant l'analyse des cooccurents (seuil 40, cooc 50), on note que certains des segments répétés disparaissent car ils ont une fréquence de 12 environ. Cependant de nouveaux termes appairaissent. Nous avons naturellement "étudiant(s)", "école(s)", "candidature", "administration", "projet éducatif".
En conclusion, nous pouvons noter que ces articles tournent principalement autour de l'éducation d'un point de vu administratif avec l'apparition fréquente de "minstère de l'éducation", "administration". Bien entendu, l'administration gérant l'éducation des termes liés comme "projet éducation", "programme scolaire" ont également une fréquence élevé.
Analyse 2 : NLTK, KoNLPy
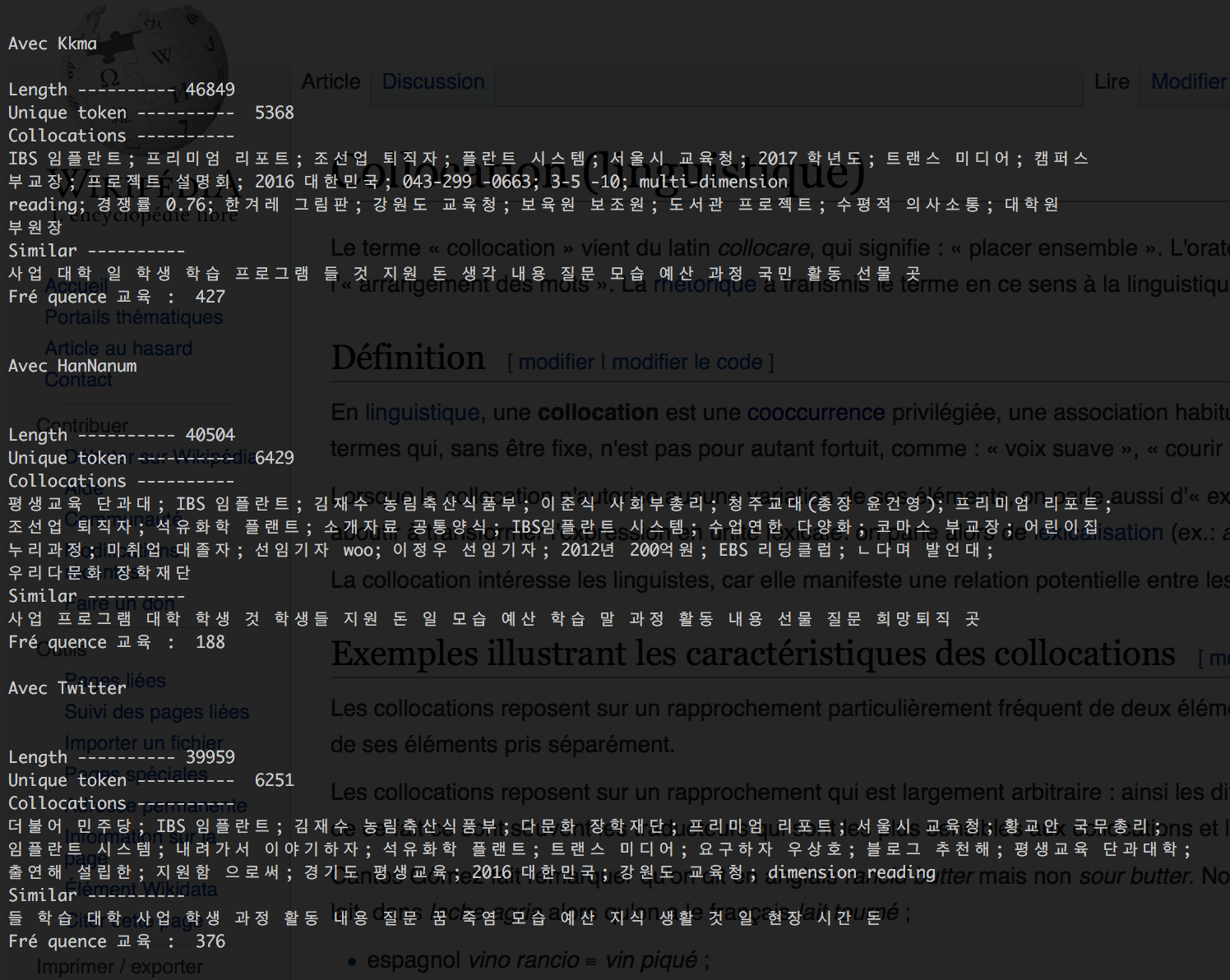
Suite à l'analyse via Trameur, une nouvelle analyse a été réalisé via le tooltkit NLTK et son homologue coréen KoNlPy. Le module KoNLPy propose des outils similaires à celui de NLTK, mais il permet également d'appeler différents ségmenteurs comme HanNanum, Twitter Korean Text et Kkma. Le mode opératoire diffère un peu de la précédente analyse. Ici, le fichier contenu a été traité juste après son nettoyage et sans l'expression régulière séparant les formes contenant kyoyuk.
Chaque segmenteurs a ses forces et faiblesses et on peut voir que leur analyse diffère un peu. Par exemple, la taille du texte n'est pas la même, 46849 tokens pour Kkma, 40504 pour HanNanum et 39959 pour Twitter KT. Les tokens uniques ont aussi des résultats différent, HanNanum en repérant plus que ses confrères, avec Kkma qui en reconnaît le moins. On peut noter, que la méthode de segmentation étant différente, les occurrences de 교육 kyoyuk aussi (Kkma : 427, HanNanum : 188, Twitter KT : 376). Kkma isole donc plus de formes de kyoyuk. Cette différence montre à quel point la notion de token est fragile car sur trois outils différents, trois méthodes sont proposées. Rappelons que dans l'analyse 1, l'occurrence de 교육 était de 536 car segmentation avec l'expression regulière.
Une des fonctionnalités intéressante était la création des collocations, pour les collocations contenant 교육 kyoyuk, nous avons :
- Bureau de l'éducation de Séoul, Bureau de l'éducation du Gangwan-do
- L'institut privée pour la formation continue
- Formation continue du Kyeonggi-do
On peut donc supposer que la plupart des articles parlent des pôles de décision liés à l'éducation à travers les décisions qu'ils mettent en place. Par rapport à l'analyse 1 qui avait montré plusieurs fois les co-occurrences de "formation continue", "bureau de l'éducation", ici nous avons plus d'éléments pour préciser leur emploi.
Il était aussi possible de voir les tokens apparaîssant dans un contexte similaire à 교육 kyoyuk, dans cette liste plusieurs termes sont liés à l'éducation comme :
- étudiants
- université
- formation
- processus
- question
- rêve
- connaissances
- programme
- budget
Conclusion
Pour conclure, nous avons vu deux outils et deux méthodes différentes pour l'analyse du mot "éducation" sur des articles de presse en ligne. La segmentation joue un rôle très important dans les résultats et il est obligatoire de réfléchir au préalable à la notion de tokens car les résultats ne seront évidemment pas pareil. Avoir plusieurs méthodes d'analyse peut s'avérer utile car chaque outils a ses points forts et faibles. Une utilisation conjointe est donc pertinente pour remonter différentes informations ou en corroborer certaines. On peut supposer que l'éducation vu dans les articles était surtout vu d'un point de vu administratif, plusieurs bureaux étant cités. Également la formation continue semble être un des thèmes revenant régulièrement dans les articles.