BAO1
Extraction de texte
Les débuts
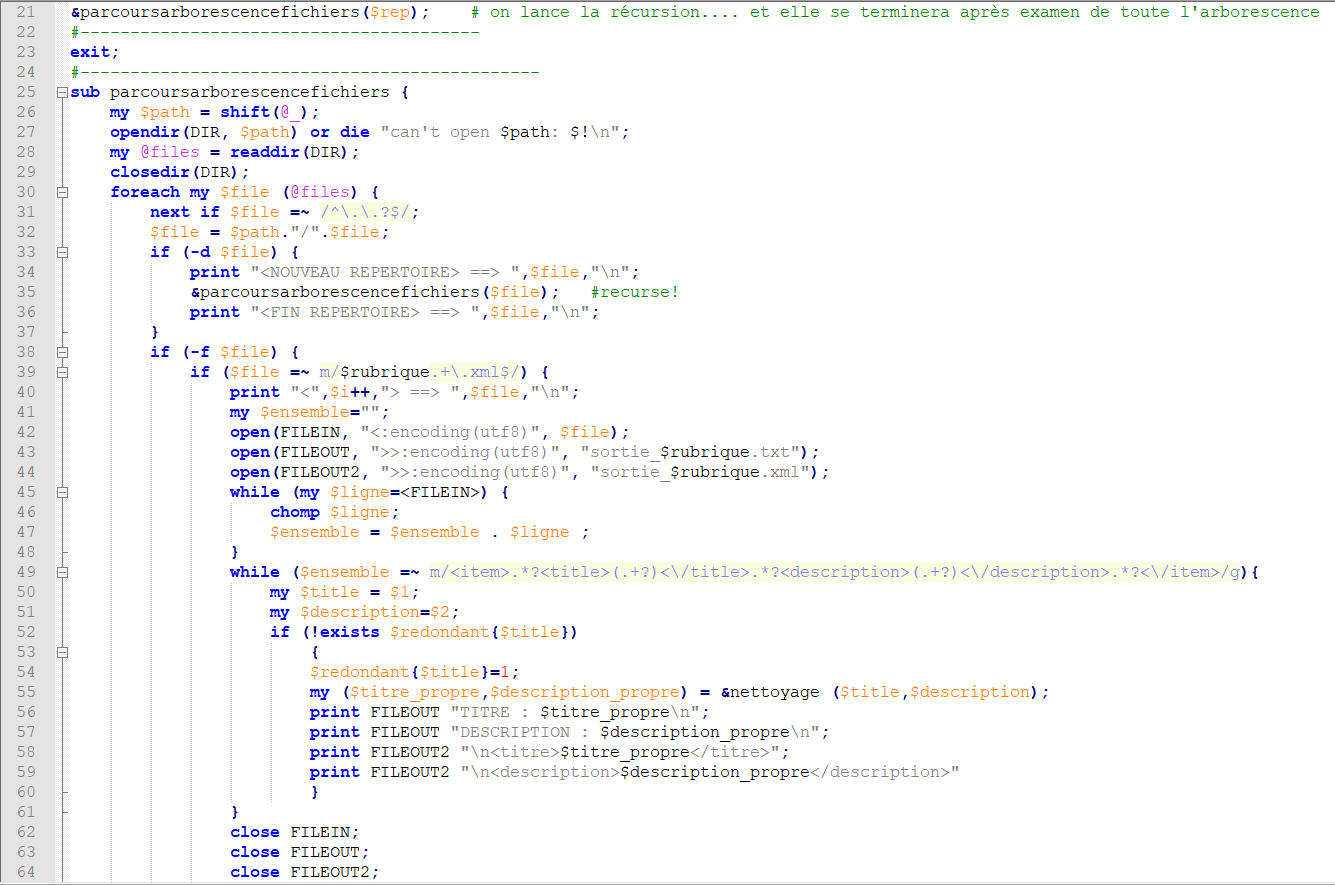
La première BAO (boîte à outils) consistait en l'extraction du contenu textuel des titres et des descriptions, à partir des fichiers du fil RSS. Pour cela, nous avons mis en classe au point un programme perl utilisant les RegEx (expressions régulières). On en a un aperçu ci-contre, et il est aussi disponible ici.
Le script permet, en entrant une commande du type "perl parcours-arborescence-fichiers-2018.pl [nomdurépertoire] [nomdelarubrique]", de parcourir tout un répertoire (ici celui rassemblant les fils RSS du Monde de l'année 2017). Ensuite, il collecte le texte des titres et descriptions dans les fichiers correspondant à la rubrique, et les rassemble dans une sortie texte (.txt) et XML (.xml). On en donne un aperçu ci-dessous, pour les sorties de la rubrique 3208 (texte à gauche, XML à droite), et toutes les sorties sont disponibles ici.