BAO2
Étiquetage de texte
Les annotations
Le but de cette étape était d'annoter correctement les fichiers obtenus à partir de la BAO précédente. Nous avions deux manières possibles : soit par le biais de TreeTagger, soit par le biais du logiciel Cordial. La différence se trouve bien entendu dans les annotations (pas le même set, pas forcément la même efficacité partout ou les mêmes paramètres, etc.) mais aussi dans le format et l'encodage du fichier d'entrée. En effet, si nous utilisons les fichiers XML avec Treetagger, encodés en UTF-8, il faut en revanche les fichiers textes pour utiliser Cordial, encodés en ISO-8859-1.
Problèmes rencontrés : le temps de traitement de la méthode TreeTagger pouvant être assez long, je n'ai pas traité toutes les rubriques au moment du rendu. De plus, impossible de faire fonctionner Cordial... j'ai donc emprunté des fichiers de sortie Cordial (.cnr) à une camarade de classe afin de continuer le projet.
méthode TreeTagger
Le script perl utilisant la méthode TreeTagger est une version améliorée du script de la BAO1. À ce titre, on y retrouve des éléments similaires (notamment une sortie XML et une sortie texte, bien que les annotations ne soient que sur la partie XML). L'ajout le plus important est représenté ci-contre : c'est le sous-programme d'étiquetage. Une fois que l'on a nos variables contenant le titre extrait et nettoyé, et la description de même (ce qu'on avait avec le premier script), on les étiquette.
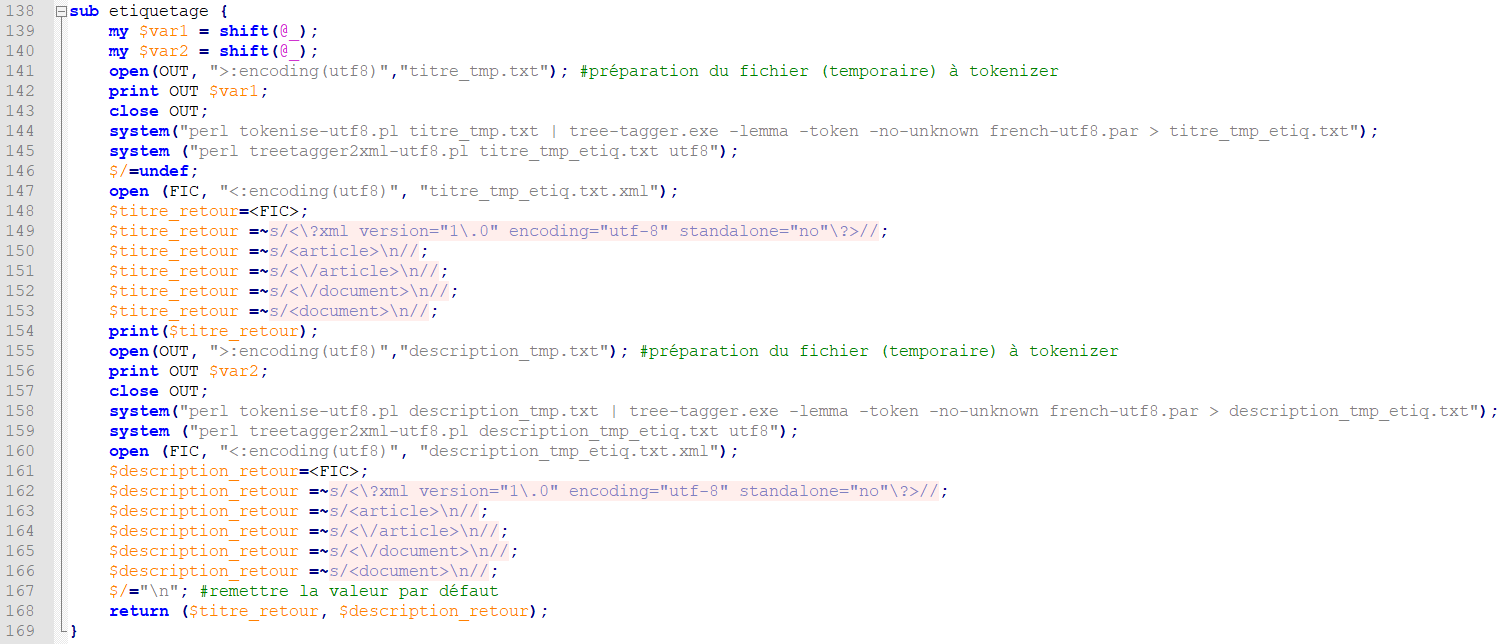
Pour cela, on les fait passer à travers un programme de tokenization, puis ensuite seulement dans TreeTagger (qui est un programme d'annotation), et enfin dans le programme treetagger2xml-utf8, qui ajoute des balises pour un rendu XML propre. Ci-contre, un aperçu d'une sortie XML (sur la rubrique 3208).
Pour lancer le programme, on utilise une commande de la forme "perl programme_parc-arbo.pl [nomdurépertoire] [nomdelarubrique]", qui rappelle la commande de la BAO1. Ici le programme est nommé programme_parc-arbo, est il est disponible ici.
Les sorties obtenues sur les rubriques sur lesquelles j'ai appliqué le programme sont disponibles ici.

méthode Cordial
Malheureusement, comme précisé plus haut, je n'ai pas réussi à faire fonctionner Cordial moi-même, je ne peux donc pas expliquer grand chose de ce processus.
Il faut transformer l'encodage UTF-8 des fichiers textes obtenus à la fin de la BAO1 en encodage ISO-8859-1 afin que Cordial puisse travailler avec. Une fois cela fait, Cordial s'occupe de tokenizer lui-même, et annote, puis renvoie un fichier au format CNR.
Ici sont disponibles les fichiers que j'ai empruntés à ma camarade, afin de pouvoir continuer. Ci-contre est également un aperçu de ce que donne un fichier .cnr.
