Boite à Outils 1
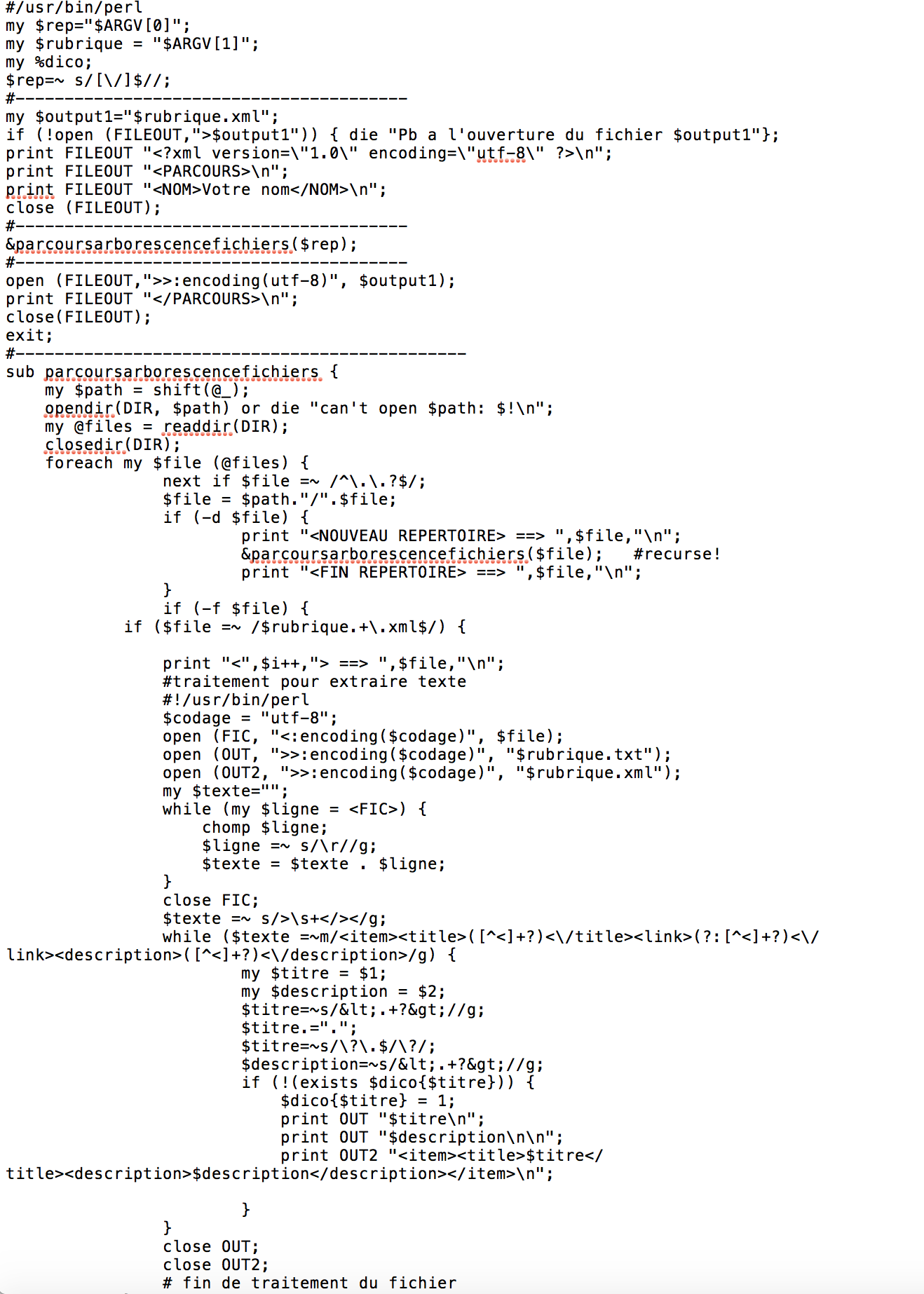
La première étape est d'extraire les textes des fichiers RSS via Perl et Regex. On récupère les contenus des valises 'title' et 'description'.
D'une part, on attend les sorties en texte brut, et d'autre part, les sorties au format XML.
Les ressources traitées dans ce projet est l'ensemble des fils RSS du site 'Le Monde' recueillis
tous les jours de l'année 2107 à 19h.
Sortie Texte Brut
Pour commencer, on a rédigé le script de l'extraction et du nettoyage d'un fichier en Perl.

Pour traiter au niveau de toute l'arborescence de fils RSS, on a encore rédigé le script prenant en entrée le nom du répertoire contenant les fichiers à traiter,
et finalement, le script qui peux parcourir par rubrique.
Ce programme a la possibilité du traitement par rubrique, alors j'ai choisi ces 3 rubriques de Culture, Média et Cinéma, pour l'analyse du motif plus tard.
Pour travailler avec les rubriques choisis, il faut préciser le code de rubrique dans la commande. Par exemple,
perl programme.pl nom_du_repertoire code_rubrique
Sortie XML
Ensuite, Pour obtenir les fichiers au format XML, on a utilisé le module du Perl, XML::RSS.
Si vous voulez, il y a encore des autres solutions comme 'XML::XPath' ou 'XML::LibXML',etc.
Sous Mac OSX, j'ai installé les modules du Perl via CPAN comme ci-dessous :
perl -MCPAN -e shell
cpan> install Bundle::CPAN
cpan> reload cpan
cpan> install XML::RSS
Puis on importe ce module dans le script d'extraction :

Sa sortie sera traitée par Treetagger à Boite à Outils série 3.