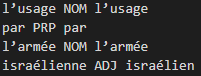
Etiquetage morpho-syntaxique
Le but de la 2ème boîte à outils est de réaliser l'étiquetage morpho-syntaxique à l'aide de deux outils: TreeTagger et Talismane.
Pour la réalisation de la 2ème boîte à outils deux programmes déjà fait (fournis par M.Fleury) en Perl ont été utilisés. Le 1er fait la tokenisation ("tokenise-utf8.pl") et le 2ème transforme le fichier au format .xml ("treetagger2xml-utf8.pl"). Nous avons également fait quelques modifications de ces scripts de Perl (e.g. l'apostrophe typographique).