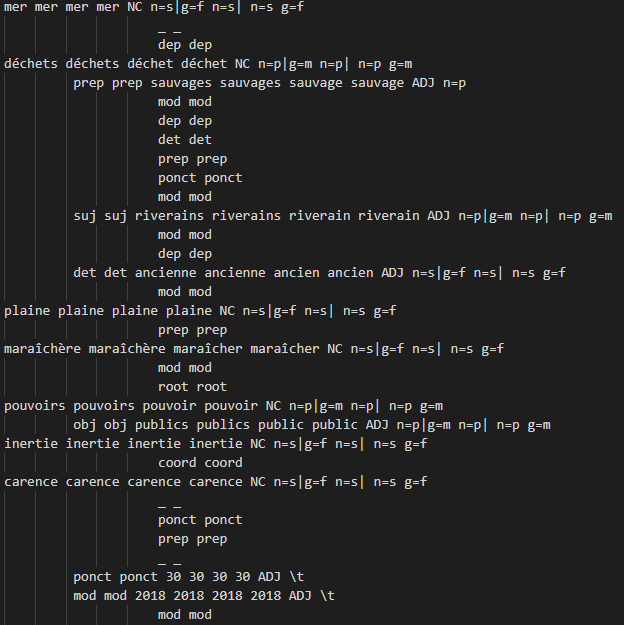
Extraction des patrons morpho-syntaxiques
Avec la 2ème boîte à outils nous avons annoté le contenu textuel des titres et des descriptions avec deux outils TreeTagger et Talismane. Maintenant on peut passer à l'extraction des patrons morpho-syntaxiques par plusieurs moyens.
 pour Talismane
pour Talismane pour TreeTagger
pour TreeTagger