Objectif: extraction des titres et descriptions contenus dans les balises item d'un seul fichier xml, puis d'une arborescence de fichiers,
et production en sortie de deux fichiers: un fichier txt avec les titres et les descriptions et un fichier xml avec de même titres et desriptions.
On commence par ouvrir le fichier xml en lecture, fichier qu'on passera en argument dans la ligne de commande
et qui est représenté dans le script par la variable $ARGV[0].
On lit le fichier xml ligne par ligne, ligne qu'on ajoute à une variable $texte et on concatène chaque ligne pour n'avoir plus qu'une
seule ligne avec tout le contenu ce qui facilite la recherche de motif avec les expressions régulières.
Avant cela, on utilise chomp pour supprimer les fins de ligne.
On ouvre aussi au début du script un fichier txt en écriture et un fichier XML en écriture (qui seront nos deux fichiers de sorties).
On a maintenant notre variable $texte contenant tout le fichier XML(RSS) sur une ligne. On va donc utiliser une expression régulière
pour "capturer" le contenu voulu, c'est-à-dire les titres et les descriptions contenus dans les balises item.
On n'oublie pas d'utiliser les parenthèses pour récupérer le contenu dans les variables $1, $2 etc.
Bien sûr, on veut toutes les occurences donc on met tout cela dans une boucle while.
On imprime tout cela dans les sorties txt et xml ouvert au début en mettant quelque peu en forme, surtout pour la sortie xml où on
va mettre un entête, une racine, une balise <article> pour chaque titre et sa description, des balises <titre> pour les titres et <description>
pour les descritptions. On a ajouté optionnellement un numéro pour chaque article qu'on incrémente à chaque tour de boucle, donc chaque article.
Ensuite, on créer un sous-programme, @nettoyage, qui va nettoyer les titres et les descriptions de ce qu'on ne veut pas (entités html,
caractères mal affichés etc.) via des expressions régulières de substitution.
Exported from Notepad++
#!/usr/bin/perl
#--------------------------------------------
# Ce programme s'utilise comme ceci : perl prog_1.pl filrss.xml
# il prend en argument un fichier RSS et il en extrait les contenus des balises titre et
# description pour chaque item.
# il créé en sortie deux fichiers : un au format txt et l'autre au format XML
#--------------------------------------------
use utf8;
my $fichier = $ARGV[0];
my $texte = "";
#Crétion des fichiers de sortie pour chaque rubrique
open my $in, "<:encoding(utf-8)", $fichier;
open my $txt, ">:encoding(utf-8)", "sortie.txt";
open my $xml, ">:encoding(utf-8)", "sortie-xml.xml";
while (my $ligne = <$in>)
{
chomp $ligne; #permet de supprimer les fins de ligne
#peut-être qu'il faudra supprimer les \r
$texte = $texte . $ligne . " ";
#print $texte;
#my $reponse = <STDIN>;
}
close $in;
print $xml "<?xml version=\"1.0\" encoding=\"UTF-8\" ?>\n";
print $xml "<Racine>\n";
my $nb = 1;
#Extraction des données textuels du titre et description
while ($texte =~ /<item>.*?<title>([^<]*)<\/title>.*?<description>([^<]*)<\/description>.*?<\/item>/g)
{
my $titre = $1;
my $description = $2;
my ($titre_clean, $description_clean) = &nettoyage($titre, $description);#& précède le nom d'une fonction qui va être défini après
print $txt "$titre_clean\n"; #my ($titre_clean, $description_clean) est une liste
print $txt "$description_clean\n\n";
print $xml "<article numero='$nb'>\n";
print $xml "<titre>$titre_clean</titre>\n";
print $xml "<description>$description_clean</description>\n";
print $xml "</article>\n\n";
$nb++;
}
print $xml "</Racine>\n";
close $txt;
close $xml;
sub nettoyage{
my $var = $_[0];#le nom de la liste est underscore (->@_ à la base)
my $var1 = $_[1];
#autre manière de faire:
#my $var1=shift(@_);
#my $var2=shift(@_);
$var = $var . "."; #$var .= ".";\xE9
$var =~ s/&#39;/'/g;
$var =~ s/\\xE9/é/g;
$var1 =~ s/&#39;/'/g;
$var1 =~ s/\\xE9/é/g;
$var =~ s/&#34;/"/g;
$var1 =~ s/&#34;/"/g;
$var =~ s/\\xE0/à/g;
$var1 =~ s/\\xE0/à/g;
$var =~ s/\\xE8/è/g;
$var1 =~ s/\\xE8/è/g;
$var =~ s/\\xEE/î/g;
$var1 =~ s/\\xEE/î/g;
return $var, $var1;
}
Télécharger ce script
Voici un exemple des sorties TXT et XML produites par ce script sur un fil RSS "À la une" (0,2-3208,1-0,0.xml):
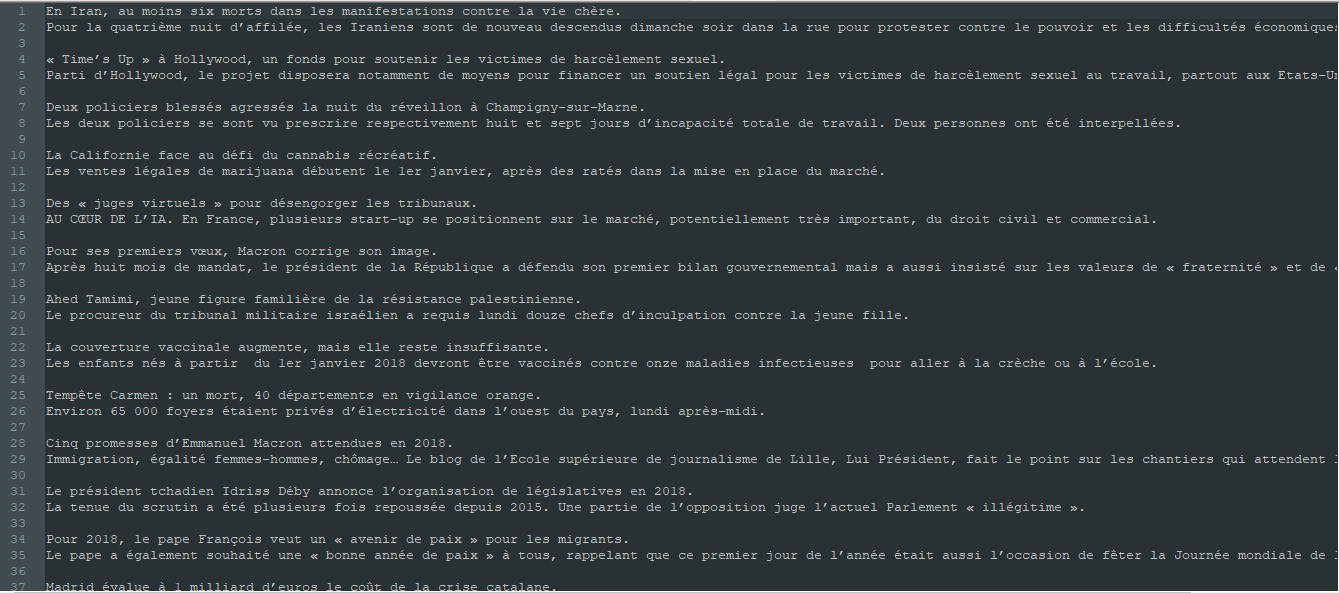 Télécharger la sortie TXT
Télécharger la sortie TXT
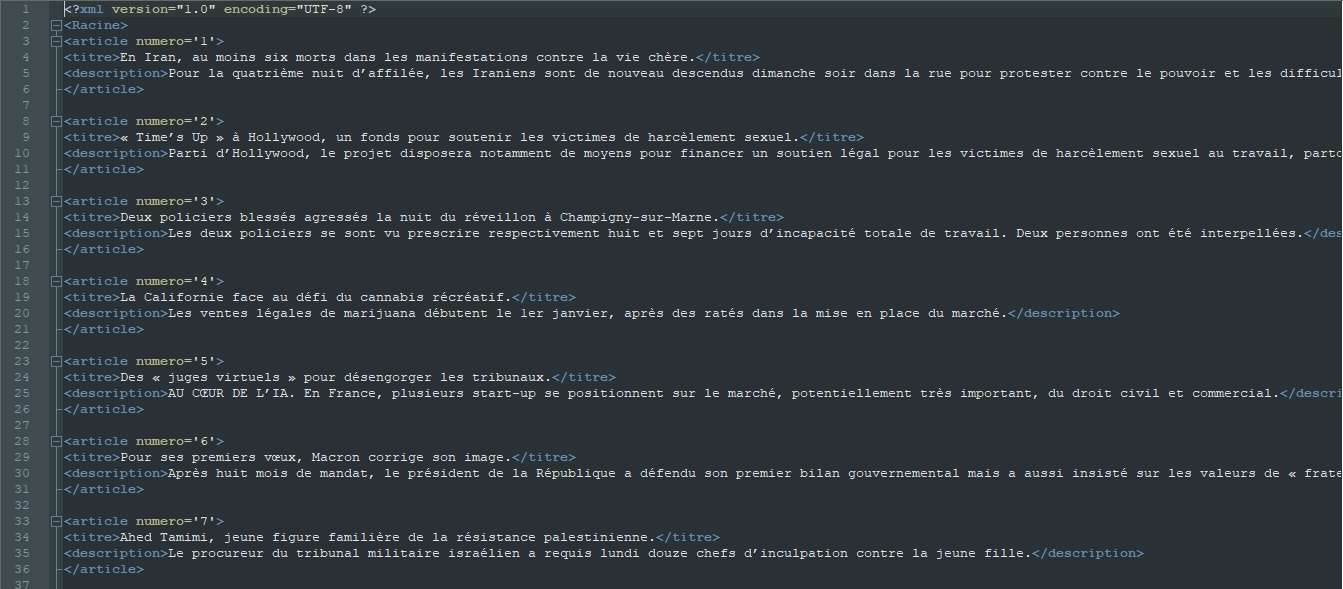 Télécharger la sortie XML
Télécharger la sortie XML
L'étape suivante est la récupération des titres et descriptions des fichiers XML d'une arborescence selon la rubrique qu'on veut.
Car jusqu'à maintenant, la phase d'extraction des titres et descriptions ne se faisait que sur un fichier XML. On va alors fabriquer un
sous-programme permettant de parcourir une arborescence de fichiers et d'en parcourir le contenu selon la rubrique que l'on souhaite traîter,
le nom du fichier nous indiquant la rubrique du journal "Le Monde" qu'elle contient.
On va se placer en haut de l'arborescence, lire le répertoire et examiner ce qu'il y a dedans de manière récursive.
Si c'est un dossier, on l'ouvre et on chercher le .xml qui nous intéresse. S'il ne le trouve pas et qu'il trouve d'autres dossiers,
il les explore etc. comme cela de manière récursive jusqu'à qu'on trouve ce qu'on cherche, c'est-à-dire les rubriques qui nous intéresse.
Aussi, il a fallu utiliser 'use uft8;' au début du programme pour régler le problème d'encodage des différents fichiers XML
traîtés, mais il a quand même fallut opérer un nettoyage grâce au sous-programme 'nettoyage'.
Exported from Notepad++
#/usr/bin/perl
<<DOC;
JANVIER 2019
usage : perl parcours-arborescence-fichiers repertoire-a-parcourir
Le programme prend en entrée le nom du répertoire contenant les fichiers et la rubrique à traiter. Par exemple: bao1.pl Library "3208"
DOC
use utf8;
my $rep="$ARGV[0]";
my $rubrique="$ARGV[1]";
my %doublon;
#Crétion des fichiers de sortie pour chaque rubrique
open(FILEOUT1, ">:encoding(utf-8)", "sortie_$rubrique.txt");
open(FILEOUT2, ">:encoding(utf-8)", "sortie_$rubrique.xml");
print FILEOUT2 "<?xml version='1.0' encoding='UTF-8'?>\n";
print FILEOUT2 "<PARCOURS>\n";
print FILEOUT2 "<nom>Elias SELHAOUI</nom>\n";
print FILEOUT2 "<fichiers-rss rubrique='$rubrique'>\n";
# on s'assure que le nom du répertoire ne se termine pas par un "/"
$rep=~ s/[\/]$//;
#Appel de la procédure afin de pouvoir parcourir tous les fichiers du répertoire
#Procédure qui est défini après
&parcoursarborescencefichiers($rep);
#fermeture des balises dans les fichiers XML de sortie
print FILEOUT2 "</fichiers-rss>\n";
print FILEOUT2 "</PARCOURS>\n";
close FILEOUT1;
close FILEOUT2;
# on lance la récursion.... et elle se terminera après examen de toute l'arborescence
exit;
#la procédure:
sub parcoursarborescencefichiers {
my $path = shift(@_);#@_ contient les arguments passés au sous-programme en cours (sub)
opendir(DIR, $path) or die "can't open $path: $!\n";
my @files = readdir(DIR); #readdir : fonction qui permet de lire le répertoire,
renvoit la liste des ressources qu'il contient; readdir c'est "l'équivalent" de l'affichage ls.
closedir(DIR);
foreach my $file (@files) {
next if $file =~ /^\.\.?$/; #passe au prochain élément de la liste si l'élément
sur lequel on est correspond à .(répertoire courant) ou ..(répertoire parent)
$file = $path."/".$file;#reconstruction du chemin relatif
if (-d $file) {
print "<NOUVEAU REPERTOIRE> ==> ",$file,"\n";
&parcoursarborescencefichiers($file); #recurse
print "<FIN REPERTOIRE> ==> ",$file,"\n";
}
if (-f $file) {
if ($file=~ m/$rubrique.+\.xml$/ ) {
print "\n<",$i++,"> ==> ",$file,"\n\n";
#Traitement réalisé sur chaque fichier
open(FILEIN, "<:encoding(utf-8)", $file);
open(FILEOUT1, ">>:encoding(utf-8)", "sortie_$rubrique.txt");
open(FILEOUT2, ">>:encoding(utf-8)", "sortie_$rubrique.xml");
print FILEOUT2 "<date>$file</date>\n";
my $texte="";
while (my $ligne=<FILEIN>) { #Lecture ligne par ligne du fichier ouvert
chomp $ligne; #Suppression du retour à la ligne sur la ligne en cours
$ligne =~ s/\r//g; #Suppression du retour chariot, sait-on jamais
$texte=$texte.$ligne; #Concaténation de la ligne lue dans la variable $texte.
}
close FILEIN;
$texte =~ s/> +</></g; #Suppression des possibles espaces
#Substitution des entités HTML avec les caractères qui y correspondent
$texte =~ s/\\xE9/é/g;
$texte =~ s/\\xE/è/g;
$texte =~ s/\\xE0/à/g;
$texte =~ s/\\xEA/ê/g;
my $num=1;
#Extraction des données textuels du titre et description
while ($texte =~ /<item>.*?<title>([^<]*)<\/title>.*?<description>([^<]*)<\/description>.*?<\/item>/g){
my $title=$1;
my $description=$2;
#On contrôle que le titre n'a pas encore été lu pour ne pas avoir plusieurs fois le même titre
if (!exists $doublon{"$title"})
{
$doublon{$title}=1;
my ($title_clean, $description_clean) = &nettoyage ($title, $description);
#Impression des données textuelles extraites dans les fichiers de sortie
print FILEOUT1 "$title_clean.\n";
print FILEOUT1 "$description_clean\n\n";
print FILEOUT2 "<item numero='$num'>\n";
print FILEOUT2 "<titre>$title_clean.</titre>\n";
print FILEOUT2 "<description>$description_clean</description>\n";
print FILEOUT2 "</item>\n";
$num++;
}
}
close FILEIN;
}
}
}
}
sub nettoyage {
my $var1=shift(@_);
my $var2=shift(@_);
$var1 =~ s/&#39;/'/g;
$var2 =~ s/&#39;/'/g;
$var1 =~ s/&#34;/"/g;
$var2 =~ s/&#34;/"/g;
$var1 =~ s/é/é/g;
$var2 =~ s/é/é/g;
$var1 =~ s/ê/ê/g;
$var2 =~ s/ê/ê/g;
$var1 =~ s/é/é/g;
$var2 =~ s/é/é/g;
$var1=~s/<.+?>//g;
$var2=~s/<.+?>//g;
$var1 =~ s/è8/è/g;
$var2 =~ s/è8/è/g;
$var1 =~ s/è0/à/g;
$var2 =~ s/è0/à/g;
$var1 =~ s/è7/ç/g;
$var2 =~ s/è7/ç/g;
$var1 =~ s/èA/ê/g;
$var2 =~ s/èA/ê/g;
$var1 =~ s/è2/â/g;
$var2 =~ s/è2/â/g;
$var1 =~ s/èF/ï/g;
$var2 =~ s/èF/ï/g;
return $var1, $var2;
}
Télécharger ce script
Voici le résultat obtenu à l'issu de la Boîte à Outil 1 pour la rubrique Sports (3242):
Télécharger le résultat TXT , Télécharger le résultat XML
Et voici le résultat obtenu pour la rubrique Sciences (3244):
Télécharger le résultat TXT , Télécharger le résultat XML