Objectif: étiquetage des sorties produites dans la BàO1 via TreeTagger et Talismane et transformation des sorties étiquetées au format XML.
On a donc utilisé deux étiqueteurs dans cette partie du travail. Le premier est TreeTagger: TreeTagger est un outil d’annotation
de texte donnant des informations sur les parties du discours (part-of-speech) et sur le lemme. Il a été développé par Helmut Schmid
dans le cadre du projet TC de l'institut de linguistique informatique de l'université de Stuttgart. TreeTagger a été utilisé avec succès
pour identifier les langues suivantes: allemand, anglais, français, italien, danois, néerlandais, espagnol, bulgare, russe, portugais,
galicien, grec, chinois, swahili, slovaque, slovène, latin, estonien, polonais, roumain et tchèque.
Pour le faire fonctionner correctement, il faut donner à TreeTagger une liste de tokens contrairement
au second étiqueteur utilisé durant ce projet: Talismane.
TALISMANE (Traitement Automatique des Langues par Inférence Statistique Moyennant l'Annotation de Nombreux Exemples)
est un analyseur syntaxique développé par Assaf Urieli dans le cadre de sa thèse au sein du laboratoire CLLE-ERSS, sous
la direction de Ludovic Tanguy. Il est écrit intégralement en Java : il fonctionne donc sur tous les systèmes d'exploitation
et est facilement intégrable à d'autres applications. Pour passer d'un texte brut à un réseau de dépendances syntaxiques, Talismane
utilise une analyse en cascade avec quatre étapes classiques pour ce type de tâche : le découpage en phrases, la segmentation en mots,
l'étiquetage (attribution d'une catégorie morphosyntaxique), et le parsing (repérage et étiquetage des dépendances syntaxiques entre
les mots. Talismane devrait être considéré comme un cadre pouvant potentiellement être adapté à n’importe quel langage naturel.
Actuellement, des modules linguistiques sont disponibles pour le français, l'anglais et l'occitan.
Pour venir à bout de la BàO2, il a fallut ajouter deux nouveaux sous-programmes au script développé à l'issu de la BàO1,
l'un intégrant l'utilisation de TreeTagger et l'autre intégrant l'utilisation de Talismane.
Le sous-programme permettant d'utiliser TreeTagger sépare les titres des descriptions et y opère les mêmes traitements. Pour chacun d'eux,
on utilise la commande perl system qui nous permet de faire fonctionner des commandes bash directement dans un programme écrit
en perl ce qui est bien pratique pour nous. La première commande system inclut à la suite l'utilisation du programme perl "tokenise-utf8.pl" (télécharger)
qui comme son nom l'indique va tokeniser les titres et descriptions donnés en entrée, puis on appel TreeTagger :
system("perl tokenise-utf8.pl -f temp.txt | tree-tagger.exe french-oral-utf-8.par -token -lemma -no-unknown > temp_tag.txt"); . La seconde
commande system appel un autre programme perl "treetagger2xml-utf8.pl" (télécharger) qui va nous permettre de passer du format produit par TreeTagger
à un format XML: system("perl treetagger2xml-utf8.pl temp_tag.txt utf8"); .
De plus, il ne faut pas oublier que "treetagger2xml-utf-8.pl" créer un entête (<?xml version ...) à chaque utilisation,
on a donc utilisé une expression régulière pour s'en affranchir et n'avoir qu'un entête : $titretagger =~ s/<\?xml.+?>//;
Le sous-programme permettant l'utilisation de Talismane traite directement les titres et les descriptions contrairement au sous-programme pour
TreeTagger. De plus, Talismane tokenise et découpe les phrases lui-même. À part cela, le principe est le même puisqu'on utilise la commande
system pour lancer Talismane sur les fils RSS comme si on lançait la commande à partir de notre terminal. C'est une commande java
dans laquelle il faut préciser la langue, l'encodage, le nom du fichier en entrée et le nom du fichier en sortie:
java -Xmx1G -Dconfig.file=./TALISMANE/talismane-fr-5.0.4.conf -jar ./TALISMANE/talismane-core-5.1.2.jar --analyse --sessionId=fr --encoding=UTF8 --inFile=bao1_test.txt --outFile=bao1_test.tal
À la fin de cette BàO2, on a donc trois sorties pour chaque rubrique: une sortie texte brut, une sortie au format Talismane et une sortie au format TreeTagger XML.
À noter aussi le temps d'éxécution total très long du programme surtout si vous travaillez avec une machine peu puissante.
Voici le programme:
Exported from Notepad++
#/usr/bin/perl
<<DOC;
JANVIER 2019
Le programme prend en entrée le nom du répertoire contenant les fichiers et la rubrique à traiter.
perl programme.pl dossier_fichier/ 3208
DOC
#-----------------------------------------------------------
use utf8;
my $rep="$ARGV[0]";
my $rubrique="$ARGV[1]";
my %doublon;
#Crétion des fichiers de sortie pour chaque rubrique
open(FILEOUT1, ">:encoding(utf-8)", "sortie_$rubrique.txt");
open(FILEOUT2, ">:encoding(utf-8)", "sortie_$rubrique.xml");
print FILEOUT2 "<?xml version='1.0' encoding='UTF-8'?>\n";
print FILEOUT2 "<PARCOURS>\n";
print FILEOUT2 "<nom>Elias SELHAOUI</nom>\n";
print FILEOUT2 "<fichiers-rss rubrique='$rubrique'>\n";
open(TALISMANE, ">:encoding(utf-8)", "sortie-$rubrique-talismane.txt");
# on s'assure que le nom du répertoire ne se termine pas par un "/"
$rep=~ s/[\/]$//;
#----------------------------------------
#Appel de la procédure afin de pouvoir parcourir tous les fichiers du répertoire
#Procédure qui est défini après
&parcoursarborescencefichiers($rep);
#fermeture des balises dans les fichiers XML de sortie
print FILEOUT2 "</fichiers-rss>\n";
print FILEOUT2 "</PARCOURS>\n";
close FILEOUT1;
close FILEOUT2;
close TALISMANE;
# on lance la récursion.... et elle se terminera après examen de toute l'arborescence
#----------------------------------------
exit;
#----------------------------------------------
#la procédure:
sub parcoursarborescencefichiers {
my $path = shift(@_);#@_ contient les arguments passés au sous-programme en cours (sub)
opendir(DIR, $path) or die "can't open $path: $!\n";
my @files = readdir(DIR); #readdir : fonction qui permet de lire le répertoire, renvoit une liste des ressources qu'il contient;
#readdir c'est "l'équivalent" de l'affichage ls.
closedir(DIR);
foreach my $file (@files) {
next if $file =~ /^\.\.?$/; #passe au prochain élément de la liste si l'élément sur lequel on est correspond à .(répertoire courant)
#ou ..(répertoire parent)
$file = $path."/".$file;#reconstruction du chemin relatif
if (-d $file) {
print "<NOUVEAU REPERTOIRE> ==> ",$file,"\n";
&parcoursarborescencefichiers($file); #recurse
print "<FIN REPERTOIRE> ==> ",$file,"\n";
}
if (-f $file) {
if ($file=~ m/$rubrique.+\.xml$/ ) {
print "\n<",$i++,"> ==> ",$file,"\n\n";
#Traitement réalisé sur chaque fichier
open(FILEIN, "<:encoding(utf-8)", $file);
open(FILEOUT1, ">>:encoding(utf-8)", "sortie_$rubrique.txt");
open(FILEOUT2, ">>:encoding(utf-8)", "sortie_$rubrique.xml");
print FILEOUT2 "<date>$file</date>\n";
my $texte="";
while (my $ligne=<FILEIN>) { #Lecture ligne par ligne du fichier ouvert
chomp $ligne; #Suppression du retour à la ligne sur la ligne en cours
$ligne =~ s/\r//g; #Suppression du retour chariot, sait-on jamais
$texte=$texte.$ligne; #Concaténation de la ligne lue dans la variable $texte.
}
close FILEIN;
$texte =~ s/> +</></g; #Suppression des possibles espaces
#Substitution des entités HTML avec les caractères qui y correspondent
$texte =~ s/\\xE9/é/g;
$texte =~ s/\\xE/è/g;
$texte =~ s/\\xE0/à/g;
$texte =~ s/\\xEA/ê/g;
my $num=1;
my $pourtalismane = "";
#Extraction des données textuels du titre et description
while ($texte =~ /<item>.*?<title>([^<]*)<\/title>.*?<description>([^<]*)<\/description>.*?<\/item>/g){
my $title=$1;
my $description=$2;
#On contrôle que le titre n'a pas encore été lu pour ne pas avoir plusieurs fois le même titre
if (!exists $doublon{"$title"})
{
$doublon{$title}=1;
my ($title_clean, $description_clean) = &nettoyage ($title, $description);
my $titre_clean_tal = $titre_clean;
my $description_clean_tal = $description_clean;
#On découpe les descriptions ligne par ligne en ajoutant une fin de ligne
#après avoir rencontré l'un des signes de ponctuation de la liste ci-dessous pour Talismane
$titre_clean_tal =~ s/([…\.\?\!]+)/$1\n\n/g;
$description_clean_tal =~ s/([…\.\?\!]+)/$1\n\n/g;
$titre_clean_tal =~ s/(\n)+ +/$1/g;
$description_clean_tal =~ s/(\n)+ +/$1/g;
$pourtalismane = $pourtalismane . $title_clean_tal . "\n\n" . $description_clean_tal . "\n\n";
#Impression des données textuelles extraites dans les fichiers de sortie
print FILEOUT1 "$title_clean\n";
print FILEOUT1 "$description_clean\n";
print FILEOUT2 "<item numero='$num'>\n";
#Lancement du sous-programme TreeTagger
my ($title_treetagger, $description_treetagger) = &etiquetage_treetagger($title_clean, $description_clean);
print FILEOUT2 "<titre>$title_treetagger</titre>\n";
print FILEOUT2 "<description>$description_treetagger</description>\n";
print FILEOUT2 "</item>\n";
$num++;
}
}
#Lancement du sous-programme Talismane
my $etiquetTa = &etiquetage_talismane($pourtalismane);
print TALISMANE "##date: $file\n";
print TALISMANE "$etiquetTa";
}
}
}
}
#Nettoyage des entités et caractères bizarres
sub nettoyage {
my $var1=shift(@_);
my $var2=shift(@_);
$var1 = $var1 . "." ;
$var1 =~ s/&#39;/'/g;
$var2 =~ s/&#39;/'/g;
$var1 =~ s/&#34;/"/g;
$var2 =~ s/&#34;/"/g;
$var1 =~ s/é/é/g;
$var2 =~ s/é/é/g;
$var1 =~ s/ê/ê/g;
$var2 =~ s/ê/ê/g;
$var1 =~ s/é/é/g;
$var2 =~ s/é/é/g;
$var1=~s/<.+?>//g;
$var2=~s/<.+?>//g;
$var1 =~ s/è8/è/g;
$var2 =~ s/è8/è/g;
$var1 =~ s/è0/à/g;
$var2 =~ s/è0/à/g;
$var1 =~ s/è7/ç/g;
$var2 =~ s/è7/ç/g;
$var1 =~ s/èA/ê/g;
$var2 =~ s/èA/ê/g;
$var1 =~ s/è2/â/g;
$var2 =~ s/è2/â/g;
$var1 =~ s/èF/ï/g;
$var2 =~ s/èF/ï/g;
return $var1, $var2;
}
sub etiquetage_treetagger
{
#dans le cours, on a écrit:
#my $vartitre = $_[0];
#my $vardesc = $_[1];
my $vartitre = shift(@_);
my $vardesc = shift(@_);
my $titretagger;
my $desctagger;
open (TMP, ">:encoding(utf-8)", "temp.txt");
print TMP $vartitre;
close TMP;#fermer le fichier est obligatoire sinon problème
#On lance à la suite TreeTagger et un programme perl qui permet de transformer la sortie tree-tagger sous forme de document XML
system("perl tokenise-utf8.pl -f temp.txt | tree-tagger.exe french-oral-utf-8.par -token -lemma -no-unknown > temp_tag.txt");
system("perl treetagger2xml-utf8.pl temp_tag.txt utf8");
{
local $/=undef;
open(FIC1, "<:encoding(utf-8)", "temp_tag.txt.xml");
$titretagger = <FIC1>;
#On supprime l'en-tête XML qui est produit automatiquement par 'treetagger2xml-utf8.pl' pour n'en avoir qu'un
$titretagger =~ s/<\?xml.+?>//;
close FIC1;
}
#Rebelote pour les descriptions
open (TMP, ">:encoding(utf-8)", "temp.txt");
print TMP $vardesc;
close TMP;#fermer le fichier est obligatoire sinon problème
system("perl tokenise-utf8.pl -f temp.txt | tree-tagger.exe french-oral-utf-8.par -token -lemma -no-unknown > temp_tag.txt");
system("perl treetagger2xml-utf8.pl temp_tag.txt utf8");
{
local $/=undef;
open(FIC1, "<:encoding(utf-8)", "temp_tag.txt.xml");
$desctagger = <FIC1>;
$desctagger =~ s/<\?xml.+?>//;
close FIC1;
}
return $titretagger, $desctagger;
}
sub etiquetage_talismane
{
my $var = shift(@_);
open (TMP, ">:encoding(utf-8)", "bao1_test.txt");
print TMP $var;
close TMP;
#Utilisation de Talismane sur les titres et descriptions du fil RSS
system("java -Xmx1G -Dconfig.file=./TALISMANE/talismane-fr-5.0.4.conf -jar ./TALISMANE/talismane-core-5.1.2.jar --analyse --sessionId=fr
--encoding=UTF8 --inFile=bao1_test.txt --outFile=bao1_test.tal");
my $lefil;
{
local $/=undef;
open(FIC1, "<:encoding(utf-8)", "bao1_test.tal");
$lefil = <FIC1>;
close FIC1;
}
return $lefil;
}
Télécharger ce script
Un aperçu des sorties produites par ce script:
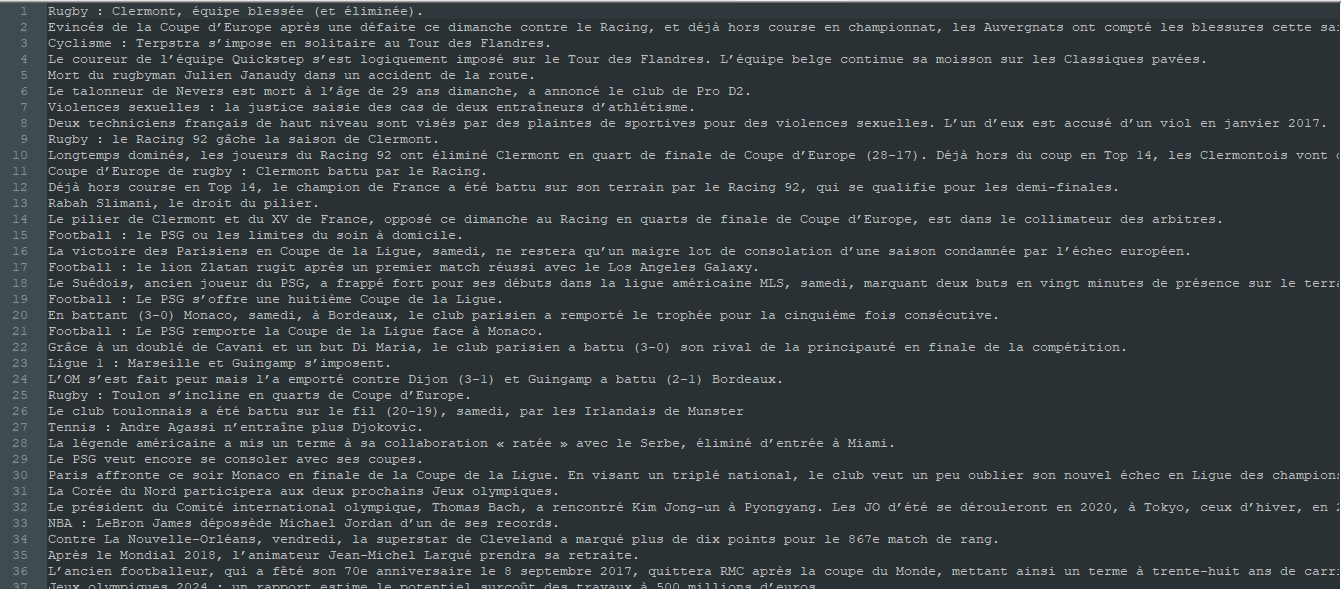 Texte brut
Texte brut
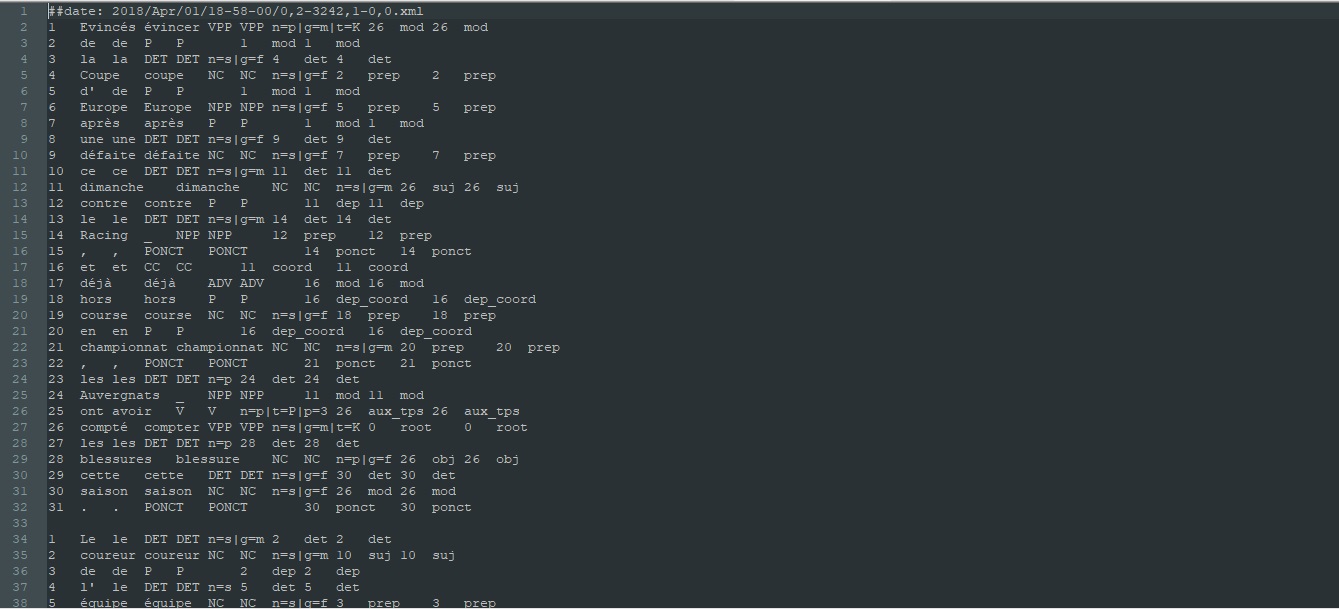 Talismane
Talismane
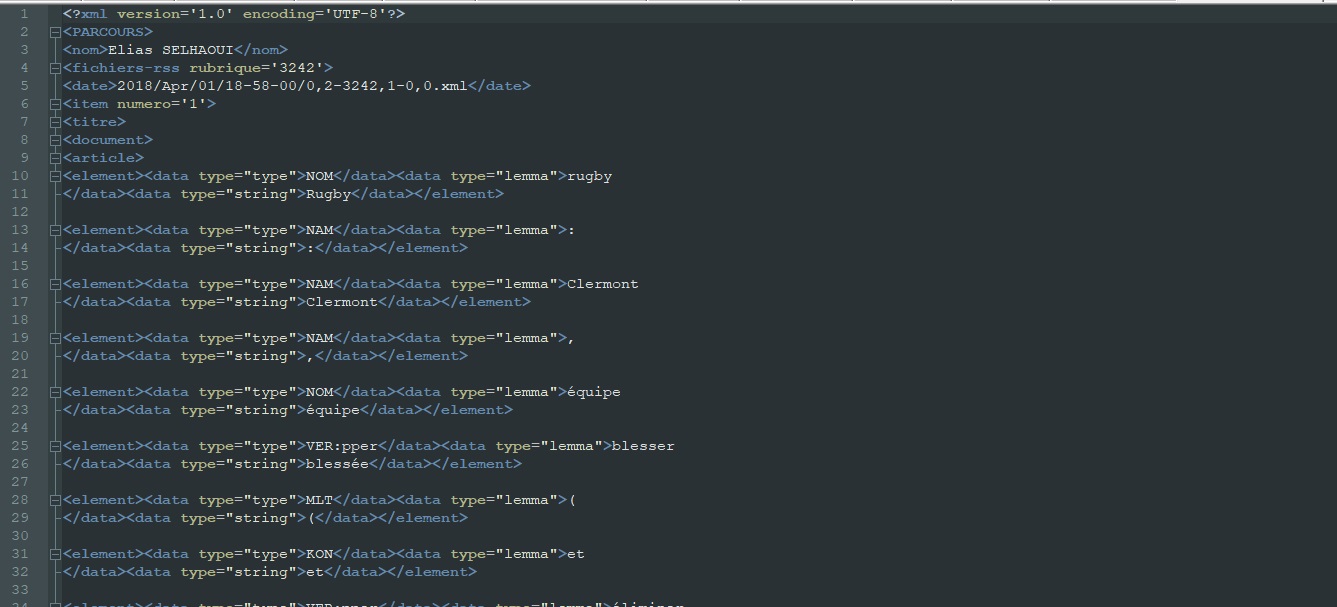 TreeTagger
TreeTagger
Voici le résultat obtenu à l'issu de la Boîte à Outil 2 pour la rubrique Sports (3242):
Télécharger le résultat TXT ,
Télécharger le résultat Talismane
Et voici le résultat obtenu pour la rubrique Sciences (3244):
Télécharger le résultat TXT ,
Télécharger le résultat Talismane
On a rencontré un soucis concernant la sortie TreeTagger pour ces deux rubriques. En effet, la sortie TreeTagger au format XML
pour les rubriques Sports et Sciences étaient mal formées (pas mal de balises </data> fermantes manquantes, portions de textes non
traités par TreeTagger etc). On est alors parti voir du côté de notre script perl mais aucun problème décelé de ce côté là, de même pour le
programme treetagger2xml.pl. On en a déduit que le problème venait du contenu des fils RSS en eux-mêmes. On a donc lancé notre programme d'étiquetage morphosyntaxique
sur deux autres rubriques pour tester, Technologies (651865) et Voyages (3546), avec pour résultat deux sorties biens formés. Nous n'avons toujours pas, à ce jours,
mis le doigt sur l'origine de ce problème.
Voici donc le résultat TreeTagger au format XML pour la rubrique Technologies (651865):
Télécharger le résultat TreeTagger ,
(Télécharger le résultat Talismane) ,
(Télécharger le résultat TXT)
Le résultat TreeTagger au format XML pour la rubrique Voyages (3546):
Télécharger le résultat TreeTagger ,
(Télécharger le résultat Talismane) ,
(Télécharger le résultat TXT)