
BAO 3 - Extraction de patrons syntaxiques

L'objectif de cette troisième boîte à outils est de pouvoir extraire différents patrons syntaxiques sur les fichiers de rubriques étiquetés par TreeTagger ou Talismane. Ces extractions obtenues permettront d'établir des terminologies caractéristiques pour chaque domaine (c'est-à-dire chaque rubrique dans notre cas). Cette boîte à outils va donc permettre de vraiment se rendre compte de l'importance de certains termes précis dans les rubriques ou de l'importance d'un motif syntaxique en particulier par rubrique par exemple.
Les quatre patrons syntaxiques à extraire sont :
- NOM PREP NOM PREP NOM
- VERBE DET NOM
- NOM ADJ
- ADJ NOM
Afin d'obtenir l'extraction de ces patrons, différentes méthodes ont été mises en oeuvre : un script Perl avec des expressions régulières, des feuilles de style XSLT et des requêtes XQuery. Les différentes méthodes sont décrites ci-dessous et sont accompagnées de leurs résultats. L'analyse de ces résultats sera effectuée dans la quatrième et dernière boîte à outils à l'aide de graphes.
Méthode Perl
Cette méthode s'applique aux fichiers textes obtenus grâce à l'étiqueteur Talismane. Ce script fait attention à ne s'intéresser qu'à chaque phrase à la fois (il ne faut pas faire dépasser le patron syntaxique à cheval sur deux phrases par exemple) et n'oublier aucun patron syntaxique dans la recherche globale d'expressions régulières. Pour faire fonctionner ce script, il est nécessaire de lui fournir le fichier de sortie Talismane et un fichier de terminologie contenant les quatre patrons à rechercher. Vous trouverez plus d'informations dans les commentaires ajoutés à ce script.
Voici comment se lance le programme : perl bao3.pl sortie-3210-talismane.txt termino.txt
Vous trouverez ci-dessous le programme Perl, le fichier termino ainsi que les résultats obtenus pour les trois rubriques :
Pour chaque rubrique et pour chaque patron, vous allez pouvoir voir ci-dessous quelques extractions les plus fréquentes (dans l'ordre de droite à gauche : 3210, 3236 puis 3244) :
NOM PREP NOM PREP NOM



Ce patron n'apparaît pas comme très pertinent pour obtenir des terminologies de nos rubriques puisque les nombres d'occurrences sont très faibles alors que ce sont les 20 premières formes. Cependant, il reste intéressant dans la mesure où certaines de ces formes décrivent bien chaque rubrique et nous permettent d'avoir une longue extraction. La forme extraite "gaz à effet de serre" cependant décrit bien à elle seule la rubrique "Planète" !
VERBE DET NOM



Encore une fois, le patron est intéressant mais les extractions obtenues ne nous permettent pas d'étabir véritablement une terminologie par rubrique dans la mesure où les extractions obtenues ne sont encore une fois pas "spécialisées" par rapport à la rubrique.
NOM ADJ

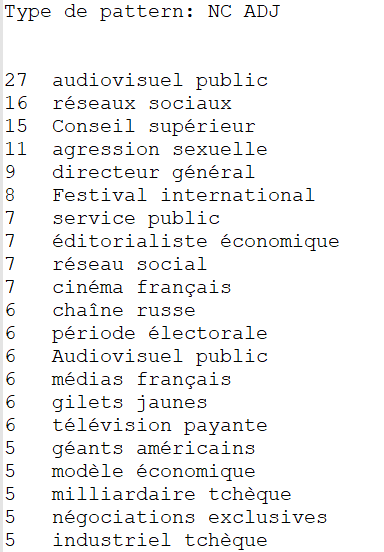
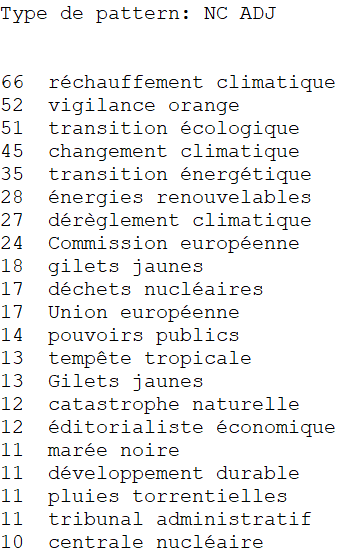
Les extractions obtenues ici par le patron deviennent très intéressantes dans la mesure où elles permettent vraiment de définir une terminologie par rubrique. En effet, ces extractions décrivent bien chaque rubrique : "président américain", "Union européenne", "élection présidentielle" ou encore "affaires étrangères" pour la rubrique "International", "audiovisuel public", "réseaux sociaux", "service public" ou encore "cinéma français" pour la rubrique "Médias" et "réchauffement climatique", "transition écologique", "changement climatique" ou encore "énergies renouvelables" pour la rubrique "Planète".
ADJ NOM
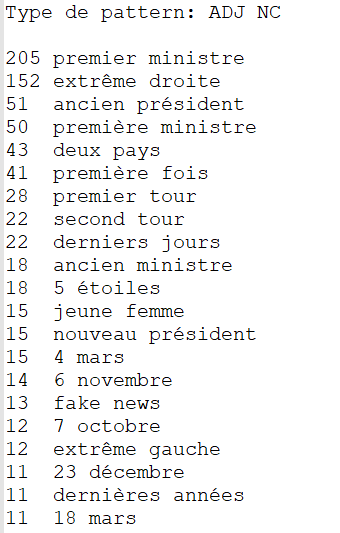
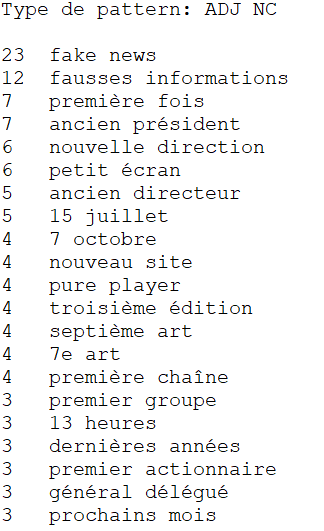
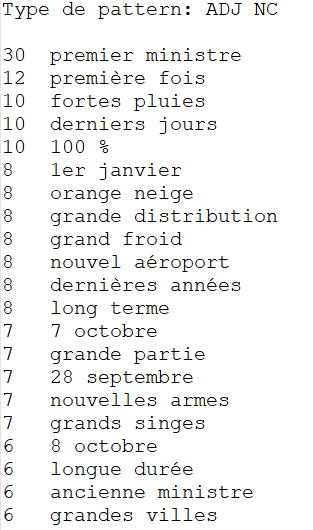
Ce patron, comme le précédent, est également pertinent puisque les termes extraits sont très fréquents et permettent de vraiment reconnaître une rubrique en fonction de l'extraction. Néanmoins, les extractions sont légèrement moins intéressantes que le patron NOM ADJ mais cela est sûrement dû au fait qu'en français, nous avons tendance à mettre les adjectifs après le nom de plus nombreuses fois que devant le nom.
Méthode XSLT
Cette méthode s'applique aux fichiers XML obtenus grâce à TreeTagger. Pour chaque patron, une feuille de style XSLT a été créée afin de pouvoir extraire les patrons pertinents. Enfin, pour obtenir ces extractions, la commande suivante a été tapée sur la machine virtuelle : xsltproc 1.xsl 3210-1.xml | sort | uniq -c | sort -gr > 3210-1.txt afin d'obtenir là aussi une sortie triée par nombre d'occurences, comme pour les résultats fournis par le programme Perl. Vous trouverez ci-dessous les résultats de chaque feuille XSLT accompagnés de celle-ci et d'exemples d'extraction dans le même ordre qu'auparavant.
NOM PREP NOM PREP NOM
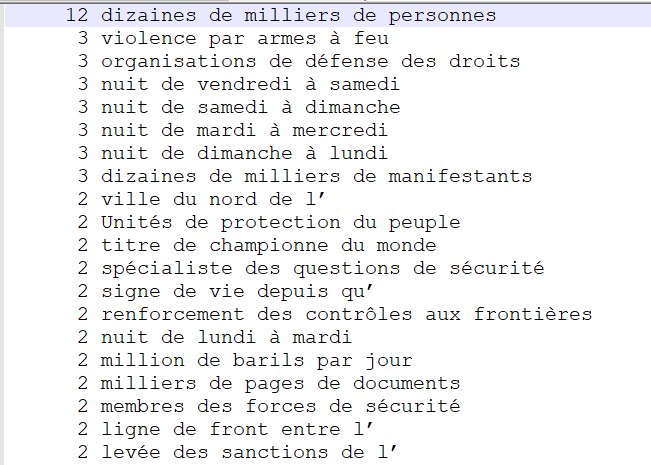
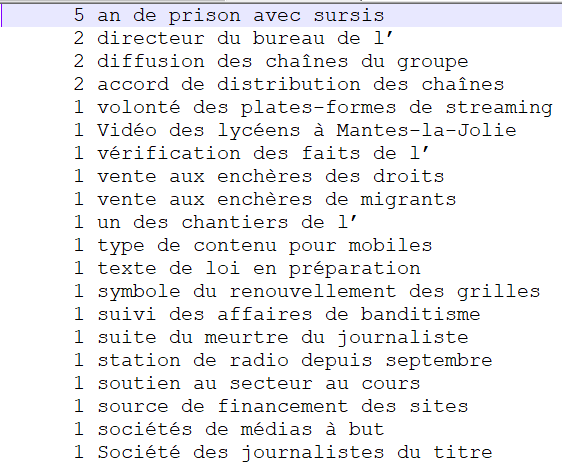

Nous n'obtenons ici pas exactement les mêmes résultats qu'avec l'extraction de patrons sur les fichiers étiquetés par Talismane. L'étiquetage n'est donc pas exactement le même. En effet, nous pouvons remarquer que TreeTagger a étiqueté des articles "l'" en noms. Cependant, la même idée que pour les fichiers Talismane apparaît ici : ce patron n'est pas forcément pertinent pour extraire une terminologie précise sur nos catégories dans le sens où toutes les extractions obtenues ne permettent pas de catégoriser pleinement nos rubriques. Cependant, il peut rester intérresant pour certaines extractions obtenues qui décrivent complètement les rubriques ("hausse des droits de douane" pour la rubrique "International", "accord de distribution des chaînes" pour la rubrique "Médias" ou "émissions de gaz à effet de serre" pour la rubrique "Planète".
VERBE DET NOM
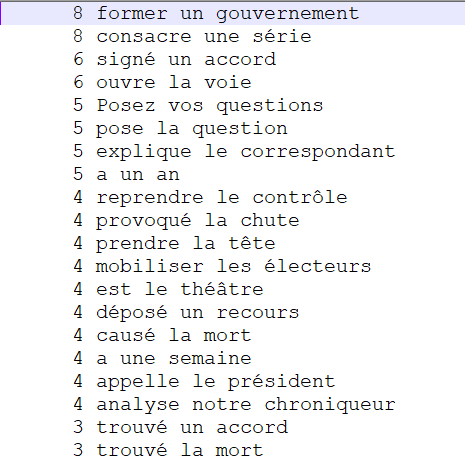

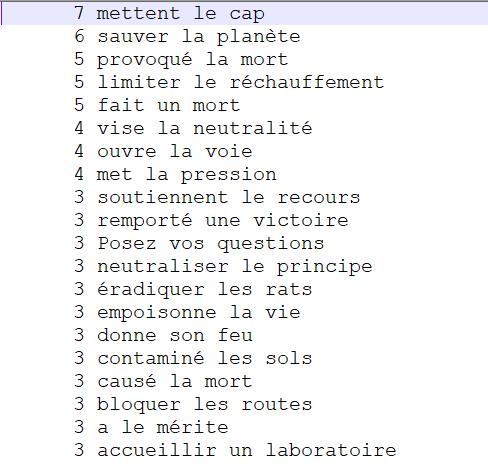
Encore une fois ici les résultats ne sont pas les mêmes que pour ceux de Talismane soit à cause des différences d'étiquetage, soit à cause des erreurs (comme "Twitter" étiqueté comme "verbe"). Ce patron n'est pas très intéressant dans la mesure où seulement certaines extractions obtenues décrivent bien la rubrique ("former une coalition" pour la rubrique "International", "paru la veille" pour la rubrique "Médias" ou "sauver la planète" pour la rubrique "Planète". En majorité encore une fois ici, les extractions obtenues ne nous paraissent pas réellement pertinentes pour vraiment obtenir une terminologie de chaque rubrique.
NOM ADJ


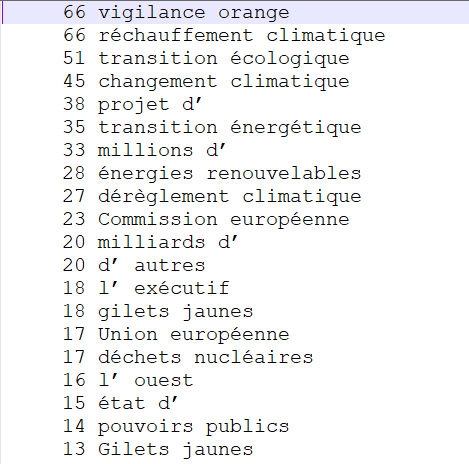
Nous retrouvons à peu près le même genre de résultats qu'avec les fichiers Talismane. Ce patron est très pertinent dans la mesure où de nombreuses occurrences de formes sont trouvées et que ces extractions décrivent bien chaque rubrique ("président américain", "affaires étrangères", "commission européenne" pour la rubrique "International", "réseaux sociaux", "cinéma français" ou "médias français" pour la rubrique "Médias" et "déchets nucléaires", "tempête tropicale" ou "développement durable" pour la rubrique "Planète". Certaines erreurs sont cependant à déplorer ici car nous pouvons voir que les "d'" ont été étiquetés comme adjectifs et que les "l'" ont été étiquetés comme noms par TreeTagger. Nous obtenons alors certaines extractions qui ne sont pas forcément pertinentes en raison de ces erreurs.
ADJ NOM
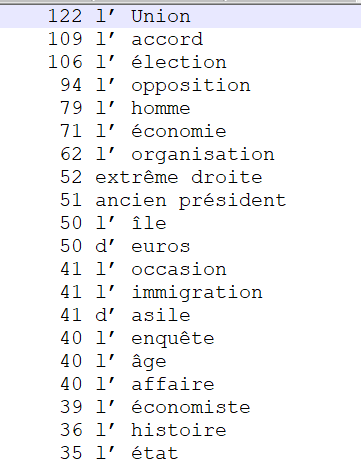
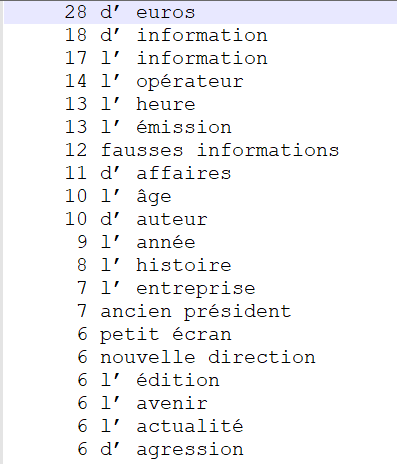

En regardant les 20 termes les plus fréquents dans ces extrations, nous nous apercevons à nouveau des fautes que commet TreeTagger lors de l'étiquetage. En effet, celui-ci a étiqueté beaucoup d'article "l'" ou "d'" en adjectifs. Les résultats sont ainsi en partie faussés. Cependant, lorsque l'on regarde les extractions obtenues après ces erreurs, l'on s'aperçoit que le patron reste lui aussi pertinent puisque les formes extraites permettent d'obtenir là aussi une terminologie précise pour chaque rubrique. En effet, "présidentielle russe", "nouvelle guerre" ou "ancien roi" décrivent bien la rubrique "International", "fausses informations" ou "Audiovisuel public" définissent la rubrique "Médias" et enfin, "fortes pluies" et "centrale nucléaire" décrivent correctement la rubrique "Planète".
Méthode XQuery
Il s'agit ici de la dernière méthode employée afin d'obtenir des extractions pertinentes grâce à nos différents patrons morphosyntaxiques. Cette méthode s'applique aux deux sorties étiquetées, à la fois celle étiquetée par TreeTagger et celle étiquetée par Talismane. Pour pouvoir appliquer ces requêtes XQuery, il a fallu tout d'abord reformater la sortie texte de Talismane en XML grâce à un script Perl fourni en cours. Ensuite, il a fallu créer sur le logiciel BaseX une base pour chaque rubrique (le fichier TreeTagger et le fichier Talismane) pour pouvoir effectuer des requêtes dessus. Vous trouverez ci-dessous pour chaque étiqueteur la requête pour chaque patron accompagnée des résultats. Des captures d'écran des premières formes seront également présentées, toujours dans le même ordre : "International", "Médias" et "Planète" de gauche à droite. Les requêtes seront écrites une seule fois par patron et par étiqueteur car il suffit de changer seulement le nom de base (le nom de la rubrique) pour la faire fonctionner sur les trois rubriques choisies. Les résultats ne seront pas commentés pour cette partie puisque nous avons déjà commenté les résultats des extractions de patrons à la fois sur les fichiers TreeTagger (feuilles XSLT) et sur les fichiers Talismane (script Perl), les mêmes remarques sont donc de nouveau valables ici puisque ce sont les mêmes.
XQuery avec les sorties TreeTagger
NOM PREP NOM PREP NOM
Voici la requête :
for $item in collection("sortie-3210-regexp")//item
for $element in $item//element
let $nextelement:=$element/following-sibling::element[1]
let $nextnextelement:=$element/following-sibling::element[2]
let $nextnextnextelement:=$element/following-sibling::element[3]
let $nextquatre:=$element/following-sibling::element[4]
where $element/data[1]="NOM" and contains($nextelement/data[1],"PRP") and $nextnextelement/data[1]="NOM" and contains($nextnextnextelement/data[1],"PRP") and $nextquatre/data[1]="NOM"
let $nom:=string-join($element/data[3]/text())
let $prep:=string-join($nextelement/data[3]/text())
let $nom2:=string-join($nextnextelement/data[3]/text())
let $prep2:=string-join($nextnextnextelement/data[3]/text())
let $nom3:=string-join($nextquatre/data[3]/text())
return (concat($nom," ",$prep," ",$nom2, " ",$prep2, " ", $nom3))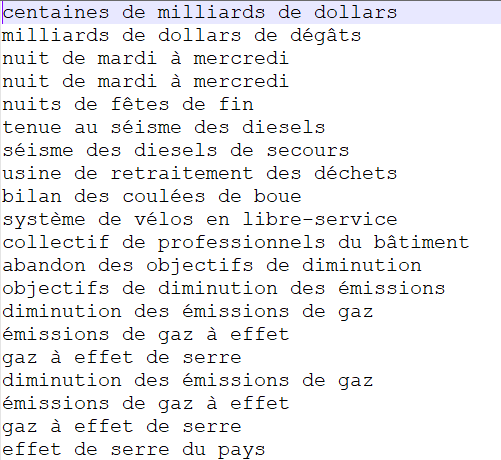


VERBE DET NOM
Voici la requête :
for $item in collection("sortie-3210-regexp")//item
for $element in $item//element
let $nextelement:=$element/following-sibling::element[1]
let $nextnextelement:=$element/following-sibling::element[2]
where contains($element/data[1],"VER") and contains($nextelement/data[1],"DET") and $nextnextelement/data[1]="NOM"
let $verbe:=string-join($element/data[3]/text())
let $det:=string-join($nextelement/data[3]/text())
let $nom:=string-join($nextnextelement/data[3]/text())
return (concat($verbe," ",$det," ",$nom))


NOM ADJ
Voici la requête :
for $item in collection("sortie-3210-regexp")//item
for $element in $item//element
let $nextelement:=$element/following-sibling::element[1]
where $element/data[1]="NOM" and $nextelement/data[1]="ADJ"
let $nom:=string-join($element/data[3]/text())
let $adj:=string-join($nextelement/data[3]/text())
return (concat($nom," ",$adj))


ADJ NOM
Voici la requête :
for $item in collection("sortie-3210-regexp")//item
for $element in $item//element
let $nextelement:=$element/following-sibling::element[1]
where $element/data[1]="ADJ" and $nextelement/data[1]="NOM"
let $adj:=string-join($element/data[3]/text())
let $nom:=string-join($nextelement/data[3]/text())
return (concat($adj," ",$nom))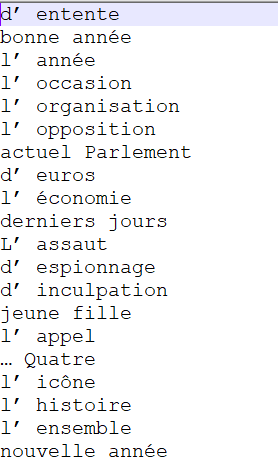


XQuery avec les sorties Talismane
Le script Perl permettant de reformater les sorties Talismane en XML ainsi que les trois fichiers reformatés sont disponibles en cliquant sur le bouton ci-dessous :
NOM PREP NOM PREP NOM
Voici la requête :
for $phrase in collection("TALISMANE-3210")//p
for $data in $phrase/item
let $nextdata:=$data/following-sibling::item[1]
let $nextnextdata:=$data/following-sibling::item[2]
let $next3:=$data/following-sibling::item[3]
let $next4:=$data/following-sibling::item[4]
where $data/a[4]="NC" and $nextdata/a[4]="P" and $nextnextdata/a[4]="NC" and $next3/a[4]="P" and $next4/a[4]="NC"
let $nom:=string-join($data/a[2]/text())
let $prep:=string-join($nextdata/a[2]/text())
let $nom2:=string-join($nextnextdata/a[2]/text())
let $prep2:=string-join($next3/a[2]/text())
let $nom3:=string-join($next4/a[2]/text())
return (concat($nom," ",$prep," ",$nom2," ",$prep2," ",$nom3))


VERBE DET NOM
Voici la requête :
for $phrase in collection("TALISMANE-3210")//p
for $data in $phrase/item
let $nextdata:=$data/following-sibling::item[1]
let $nextnextdata:=$data/following-sibling::item[2]
where $data/a[4]="V" and $nextdata/a[4]="DET" and $nextnextdata/a[4]="NC"
let $verbe:=string-join($data/a[2]/text())
let $det:=string-join($nextdata/a[2]/text())
let $nom:=string-join($nextnextdata/a[2]/text())
return (concat($verbe," ",$det," ",$nom))


NOM ADJ
Voici la requête :
for $phrase in collection("TALISMANE-3210")//p
for $data in $phrase/item
let $nextdata:=$data/following-sibling::item[1]
where $data/a[4]="NC" and $nextdata/a[4]="ADJ"
let $nom:=string-join($data/a[2]/text())
let $adj:=string-join($nextdata/a[2]/text())
return (concat($nom," ",$adj))

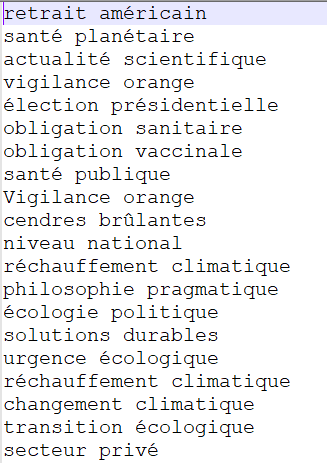
ADJ NOM
Voici la requête :
for $phrase in collection("TALISMANE-3210")//p
for $data in $phrase/item
let $nextdata:=$data/following-sibling::item[1]
where $data/a[4]="ADJ" and $nextdata/a[4]="NC"
let $adj:=string-join($data/a[2]/text())
let $nom:=string-join($nextdata/a[2]/text())
return (concat($adj," ",$nom))


Remarques
Après vérifications des résultats, nous obtenons bien les mêmes nombres d'extractions entre les différentes méthodes (script Perl et XQuery pour Talismane ou feuilles XLST et XQuery pour TreeTagger). Entre les sorties des deux étiqueteurs, nous n'obtenons cependant pas les mêmes extractions car ceux-ci n'étiquettent pas de la même manière toutes les données. Nous avons observé beaucoup d'erreurs d'étiquetage dans les extractions de patrons morphosyntaxiques sur les sorties de TreeTagger. Pour réaliser les analyses de la quatrième et dernière boîte à outils, nous allons donc nous appuyer sur les extractions de motifs obtenues à partir des fichiers de sortie de Talismane, qui a vu d'oeil, ne présentaient pas d'erreurs flagrantes comme celles rencontrées avec TreeTagger. Utiliser ces fichiers nous permettra d'obtenir des analyses plus justes et plus précises. Au niveau de la vitesse d'obtention des extractions de motifs, celle-ci n'est pas très élevée quoi qu'il arrive mais le script Perl met environ 5 secondes à tout extraire et les feuilles XSLT mettent également quelques secondes à produire les sorties (selon la taille du fichier XML). La méthode la plus rapide est XQuery car il faut moins d'une seconde à chaque fois pour extraire tout un motif. Il s'agit donc d'une méthode très performante !