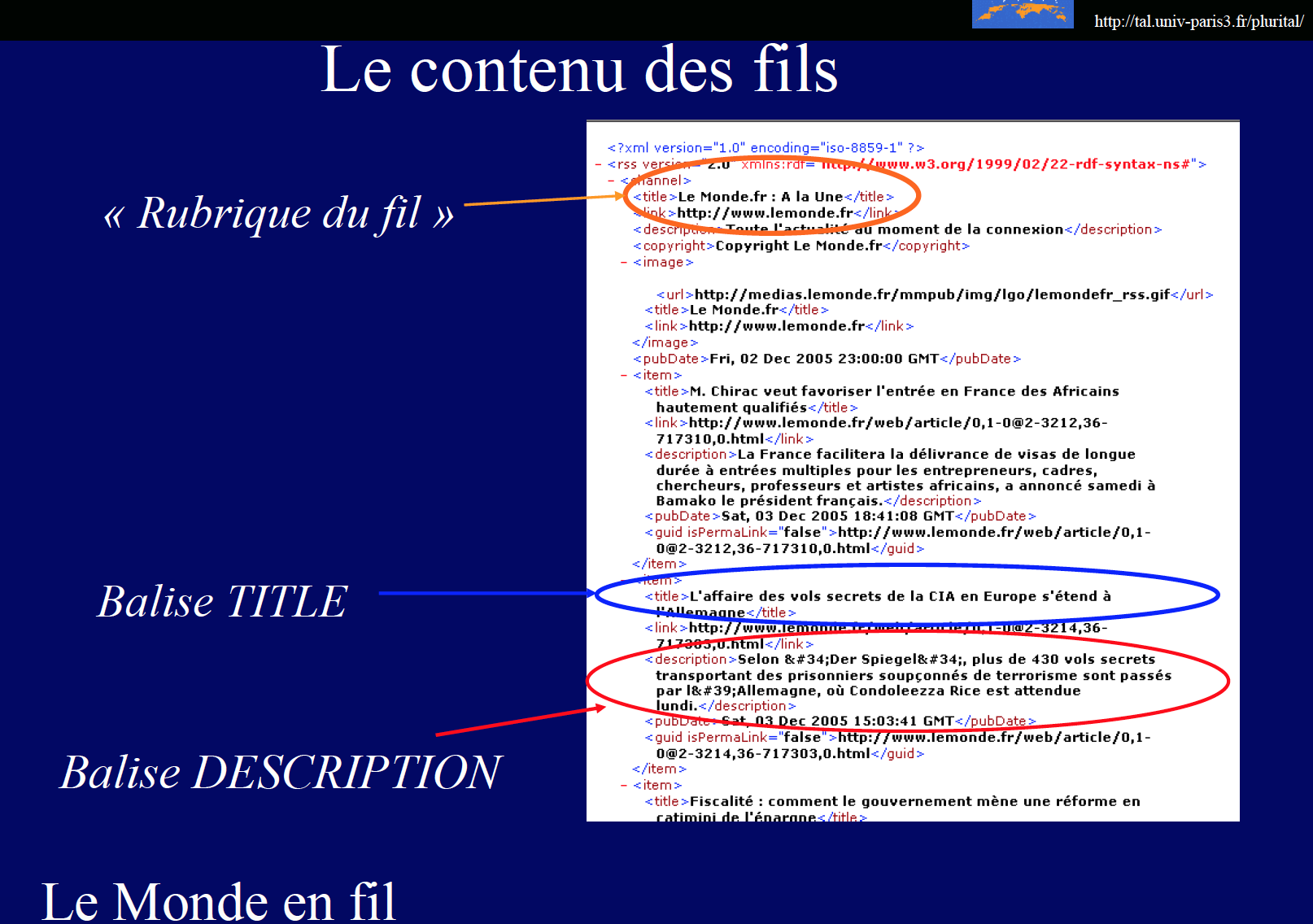
Objective :
Extraire les contenus textuels des balises title et description de l'arborescence des fils RSS du journal le monde pour l’année 2018
Description :
Dans Bao 1 on doit créer un programme qui parcourt une arborescence de fichiers et applique un traitement sur chacun des fichiers rencontrés au moment du parcours. Dans ce script, il faut harmoniser le flux textuel en entrée au regard des différents types de fichiers XML::RSS en entrée, filtrer les contenus textuels des balises TITLE et DESCRIPTION contenues dans les balises ITEM et extraire simultanément le titre et la description de chaque item qui signifie qu’on doit distinguer pour chaque article, le titre et sa description. On veillera aussi à ne pas mémoriser plus d'une fois le même article. On nettoiera les données.
Le script prend en entrée des fichiers XML-RSS et Il produit en sortie un fichier TXT et un fichier XML. Si on essayer de traiter toutes les rubriques du journal ça va prendre beaucoup de temps. C’est pourquoi chaque groupe devait choisir et traiter seulement deux rubrique. En outre, il fallait produire des sorties distinctes pour chaque rubrique. Puisqu’on a choisi les rubrique culture et Europe, le traitement de la rubrique CULTURE conduit à 2 fichiers de sortie, celui de la rubrique EUROPE aussi.
Avant de passer au traitement automatique de toute l'arborescence des deux rubriques, il fallut s'assurer que le traitement sur un fichier se passe bien et de manière optimale. Pour cela on a testé le script pendant les premières séances sur un corpus de test qui contient seulement les fils RSS de deux journées du mois de Janvier de l’année 2018. Cela nous a permet de vérifier si le texte visé par le motif est réparti sur plusieurs lignes, de nettoyer le texte, de voir si on doit réparer l'encodage, de supprimer les éventuels doublons, etc.
On a utilisé deux méthodes pour faire l'extraction. Dans la première méthode on a utilisé Perl avec les expressions régulières et dans la deuxième méthode on a utilisé la bibliothèque Perl XML::RSS.
Le script d'extraction des contenus textuels avec des REGEXP:
Ce script est lancé de la manière suivante :
Rubrique Culture : perl Load-BAO1-regexp.pl 2018/ 3246
Rubrique Europe :perl Load-BAO1-regexp.pl 2018/ 3214
Dans cette commande il y a deux arguments : le répertoire contenant tous les fichiers « 2018 » et la rubrique qui nous intéresse « 3246 ». Donc le script parcourt l'arborescence des fichiers contenue dans le dossier entré en premier argument, jusqu'au-il tombe sur les fichiers XML de notre rubrique qui est en deuxième argument.
Les deux premières variables de notre script $rep : c’est le dossier contenant tous les fichiers RSS et $rubrique : c’est le chiffre qui correspond à notre rubrique. Après on introduit nos deux fichiers de sorties "sortie-$rubrique-regexp.txt" et "sortie-$rubrique-regexp.xml" qui contient les titres et descriptions
my $rep="$ARGV[0]"; my $rubrique="$ARGV[1]"; # on s'assure que le nom du rÈpertoire ne se termine pas par un "/" $rep=~ s/[\/]$//; my $i=0; my %doublons; open(OUT, ">:encoding(utf-8)", "sortie-$rubrique-regexp.txt"); open(OUTXML, ">:encoding(utf-8)", "sortie-$rubrique-regexp.xml"); print OUTXML "\n"; print OUTXML "\n";
Ensuite, on définit la fonction "parcoursarborescencefichiers" qui permet de parcourir tous les fichiers XML de l´arborescence des fils RSS. Elle ouvre le répertoire « $rep » parcourt les documents et vérifie s´il s´agit d´un document XML correspondant à notre rubrique et répète ce procédure jusqu´à ce qu´elle a fini toute l´arborescence et on ajoute le traitement des RSS à l´intérieur de cette fonction. C’est à dire, quand elle tombe sur un fichier XML dont le nom corresponde au chiffre qu´on a donné en en argument, le script passe aux traitements. On supprime les retours à la ligne, concatène tout le contenu textuel dans la variable $tout_le_texte, supprime les possibles espaces entre balises.
&parcoursarborescencefichiers($rep); #recurse!
close OUT;
print OUTXML "\n";
close OUTXML;
exit;
#----------------------------------------------
sub parcoursarborescencefichiers {
my $path = shift(@_);
opendir(DIR, $path) or die "can't open $path: $!\n";
my @files = readdir(DIR);
closedir(DIR);
foreach my $file (@files) {
next if $file =~ /^\.\.?$/;
$file = $path."/".$file;
if (-d $file) {
print "on entre dans $file \n";
&parcoursarborescencefichiers($file); #recurse!
}
if (-f $file) {
if ($file=~/$rubrique.+\.xml$/) {
print $i++," : $file \n";
open(FIC, "<:encoding(utf-8)", $file);
my $tout_le_texte="";
while (my $ligne = ) {
chomp $ligne;
$tout_le_texte = $tout_le_texte . $ligne . " ";
}
close FIC;
On extrait le texte entre les balises titres & descriptions avec l’expression régulières ( while $tout_le_texte = ~ ...) puis, on stocke tous les titres dans la variable $1 et les descriptions dans la variable $2.
while ($tout_le_texte =~ /<item>.*?<title>([^<]*)<\/title>.*?<description>([^<]*)<\/description>.*?<\/item>/g) {
my $titre = $1;
my $description = $2;
On fait l’appel à une deuxième fonction définie qui fait le nettoyage du contenu textuel des fichiers de tous les caractères spéciaux et qui rajoute les points qui manquent à la fin du titre à l'affichage après extraction du texte entre les balises à l'aide d'une expression régulière.
my ($titrenettoye,$descriptionnettoye) = &nettoyage($titre,$description);
Voici la fonction qui fait le nettoyage :
sub nettoyage {
my $var = $_[0]; #my ($tit, $des) = @_;
my $var1 = $_[1];
$var = $var . "." ; # $var .= ".";
#$var1 = $var1 . ".";
$var1 =~ s/'/'/g;
return $var, $var1;
}
On élimine les doublons avec cette instruction :
if (exists $doublons{$titrenettoye}) {
$doublons{$titrenettoye}++;
}
else {
$doublons{$titrenettoye}=1;
En final, on imprime les données qu´on a obtenu comme résultats dans les deux fichiers de sorties.
print OUT "$titrenettoye\n"; print OUT "$descriptionnettoye\n"; print OUTXML "\n"; print OUTXML " \n";$titrenettoye \n"; print OUTXML "$descriptionnettoye \n"; print OUTXML "
Le script d'extraction des contenus textuels avec la bibliothèque Perl XML::RSS:
La deuxième méthode consiste à utilisé la bibliothèque XML::RSS pour récupérer les titres et descriptions au lieu d'utiliser une expression régulière. On utilise presque le même programme avec des petites modifications. On introduit la variable $rss et on récupère les données textuelles des titres et description et on les met dans une liste.
if (-f $file) {
if ($file=~/$rubrique.+\.xml$/) {
print $i++," : $file \n";
my $rss=new XML::RSS;
eval {$rss->parsefile($file); };
if( $@ ) {
$@ =~ s/at \/.*?$//s; # remove module line number
print STDERR "\nERROR in '$file':\n$@\n";
}
else {
foreach my $item (@{$rss->{'items'}}) {
my $description=$item->{'description'};
my $titre=$item->{'title'};
my ($titrenettoye,$descriptionnettoye) = &nettoyage($titre,$description);
if (exists $doublons{$titrenettoye}) {
$doublons{$titrenettoye}++;
}
else {
$doublons{$titrenettoye}=1;
print OUT "$titrenettoye\n";
print OUT "$descriptionnettoye\n";
Les sorties :
Sortie texte brut :
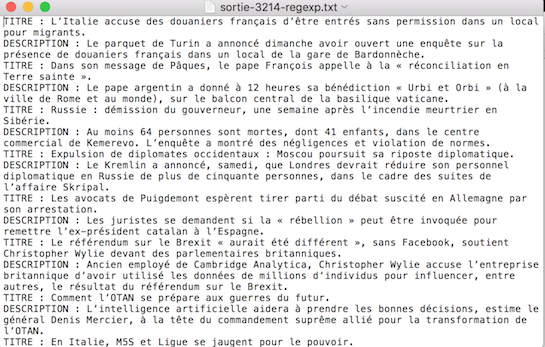
Sortie XML :
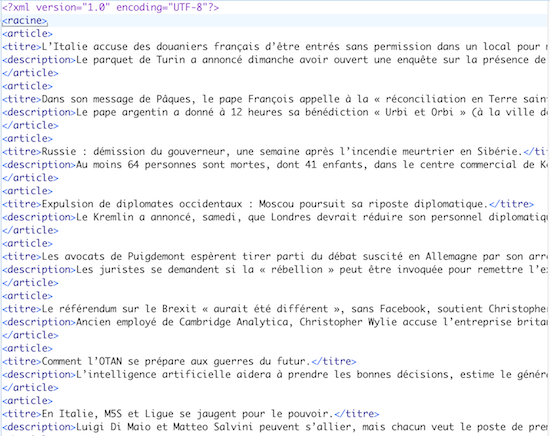
Voici les fichiers de sortie générés par le programme pour les 2 rubriques sélectionnées:
-
Rubrique Culture :
-
Rubrique Europe :