#Ici on peut insérer des images en haut.

LancsBox
(#LancsBox: Lancaster University corpus toolbox), un logiciel d’analyse et de comparaisons de corpus a
également été utilisé. Nous proposons ici une présentation du logiciel et de ses différentes options.
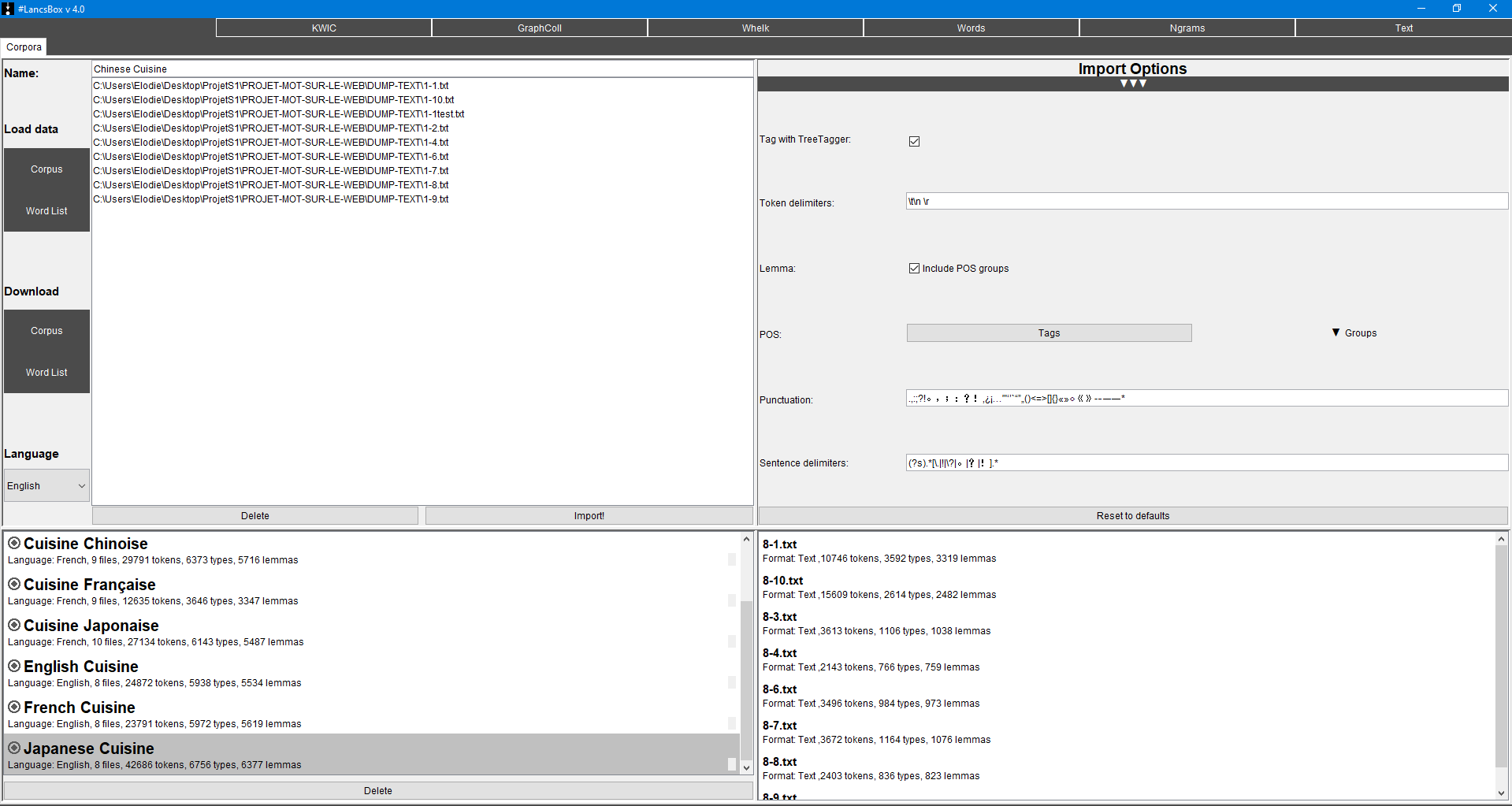
1. Charger les corpus
Pour l’utiliser il faut tout d’abord choisir un ou plusieurs corpus, qu’ils soient présents par défaut ou personnalisés.
Dans le cadre de ce projet, les huit corpus correspondant à nos syntagmes ont été constitués des différents fichiers au format .txt récupérés
dans le dossier DUMP-TEXT grâce au script préalablement créé. Les corpus créés sont alors directement annotés si le logiciel est configuré
avec la langue cible. Dans le cadre de notre travail, trois des quatre langues que nous étudions sont supportées par celui-ci (l’anglais, le chinois
et le français). Une option ("Other") peut cependant être sélectionnée pour traiter les autres langues, l’annotation n’y sera simplement pas traitée.
Lors de l’import de ces fichiers, différentes options sont paramétrables à l’image des séparateurs de texte ou du type d’annotation voulu.
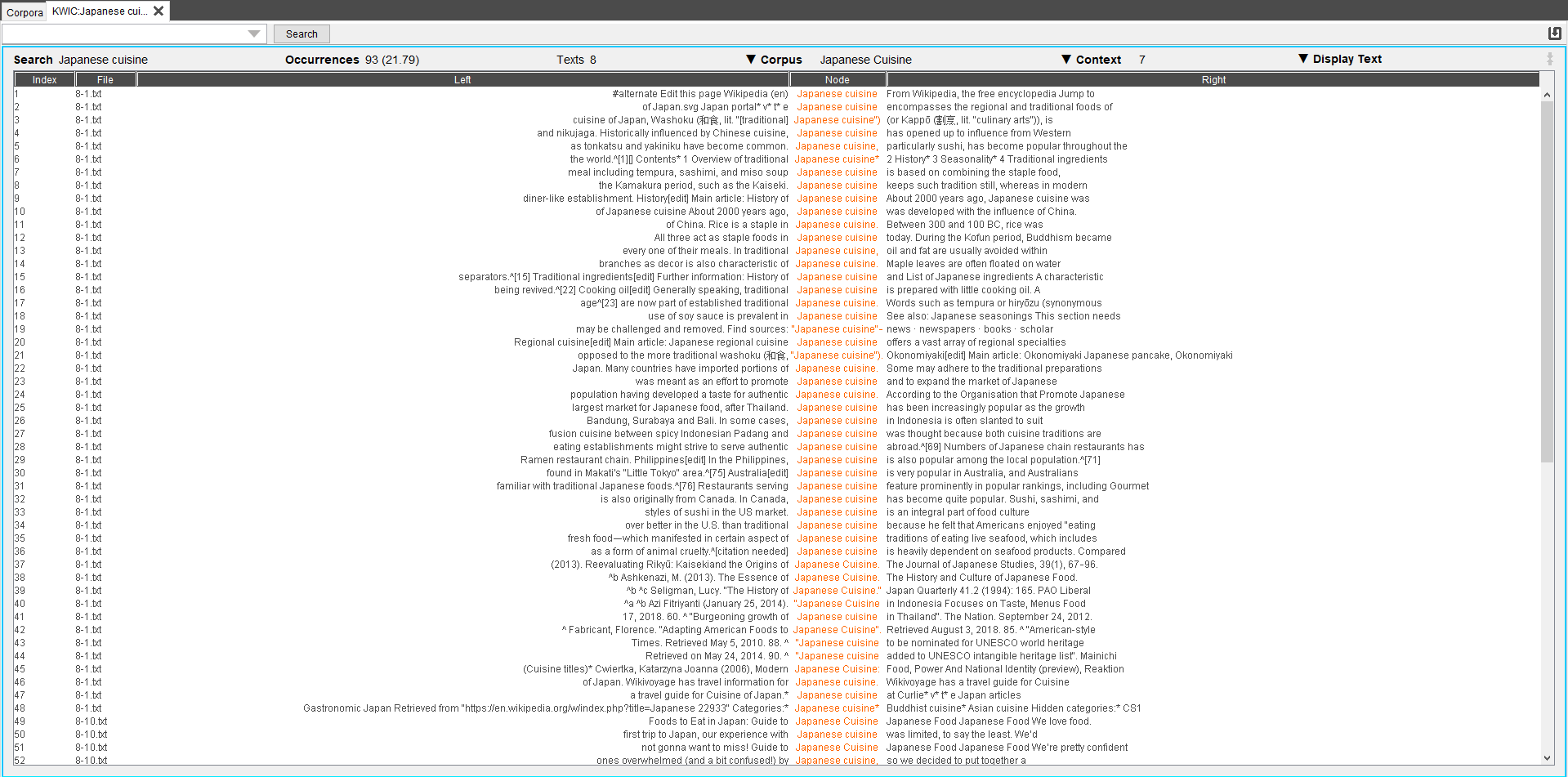
2. KWIC
Il faut alors ouvrir l’onglet KWIC (key word in context) qui permet d’obtenir un concordancier présentant diverses options comme celle de
choisir le nombre de mots des contextes droits et gauches ainsi que l’affichage du texte, ici le choix a été porté sur "plain text", qui plus
lisible de manière naturelle mais il est également possible d’afficher toutes les annotations : les annotations de parties du discours ou uniquement
les lemmes. A partir de là, d’autres options d’analyse sont accessibles.
3. GraphColl
Présenté comme l’outil de représentation de réseaux et de collocations,
ce dernier permet de représenter visuellement les collocations les plus fréquentes,
de les comparer avec un autre corpus, mais aussi de regarder les collocations partagées avec d’autres mots.
Il est là aussi possible de jouer sur différents paramètres : la distance avec le contexte considéré, le type de données statistiques voulues,
le seuil de la fréquence ainsi que le type d’unités observées (lemmes, parties du discours ou les deux).
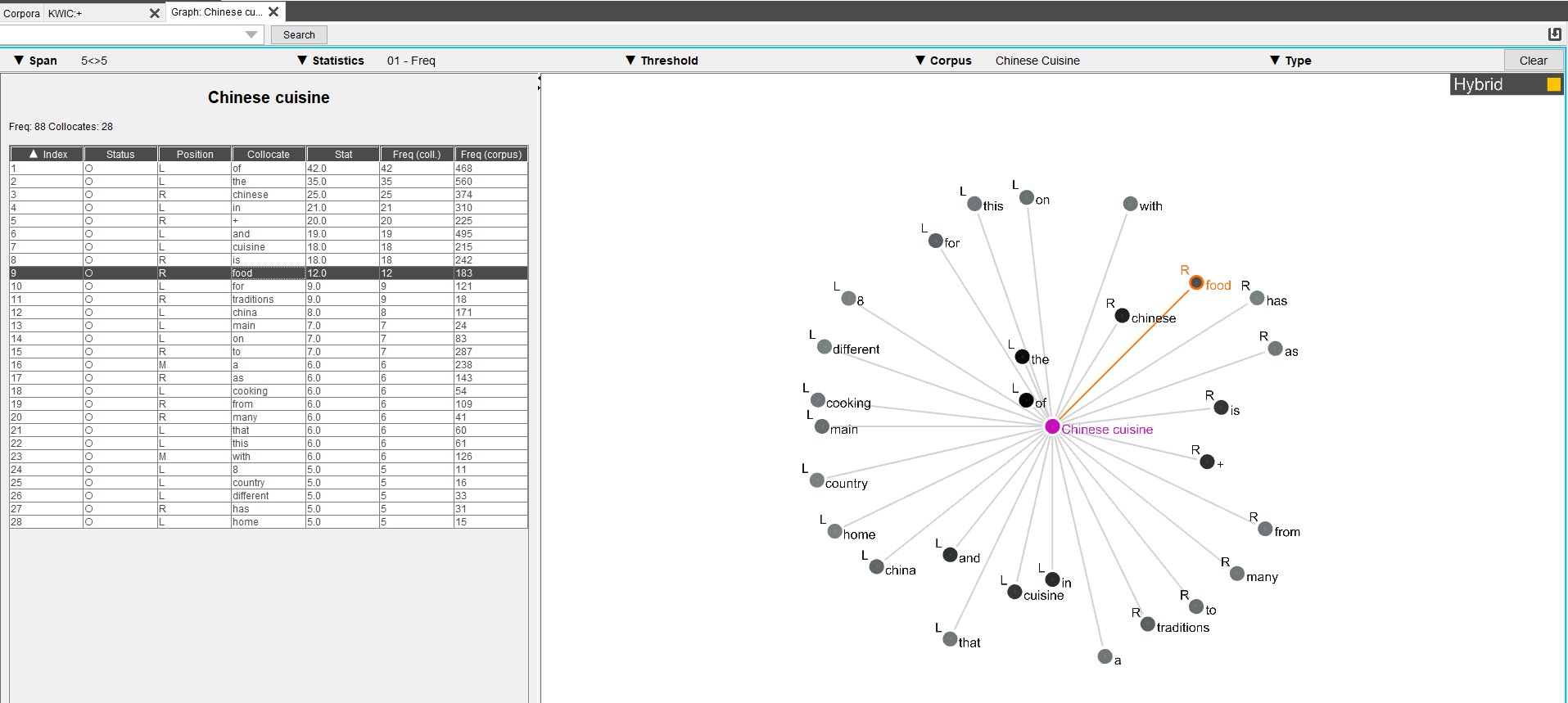
Sur ces graphes, plus le mot est fréquent, plus il sera proche du syntagme cible.
Il y a trois modes d’affichages possibles : Free qui permet de déplacer librement les collocations ,
Hybride qui permet ces mêmes déplacements mais précise la position des contextes (à droite (R), à gauche (L) ou autant dans les deux positions (M))
et Positional, respectant strictement ces contextes et dont les occurrences ne peuvent pas être déplacées.
A l’aide d’un double-click sur l’une des collocations, nous pouvons obtenir des collocations qui sont à
la fois communes aux deux groupes cibles (reliées aux deux), mais aussi ceux qui leur sont spécifiques.
Cet exemple démontre l’intérêt du mode "Free" puisque les collocations communes étaient illisibles car elles se superposaient.
De plus, une augmentation du seuil de fréquence nécessaire pour apparaître a été privilégiée afin de pouvoir voir distinctement les collocations autour du mot "food".
Tous les mots apparaissant dans la première figure mais pas dans la seconde sont ainsi des occurrences pour lesquelles la fréquence n’était plus suffisante pour être prise en compte par le logiciel.
Cette illustration représente deux cibles associées mais davantage peuvent en être sélectionnées de la même manière.

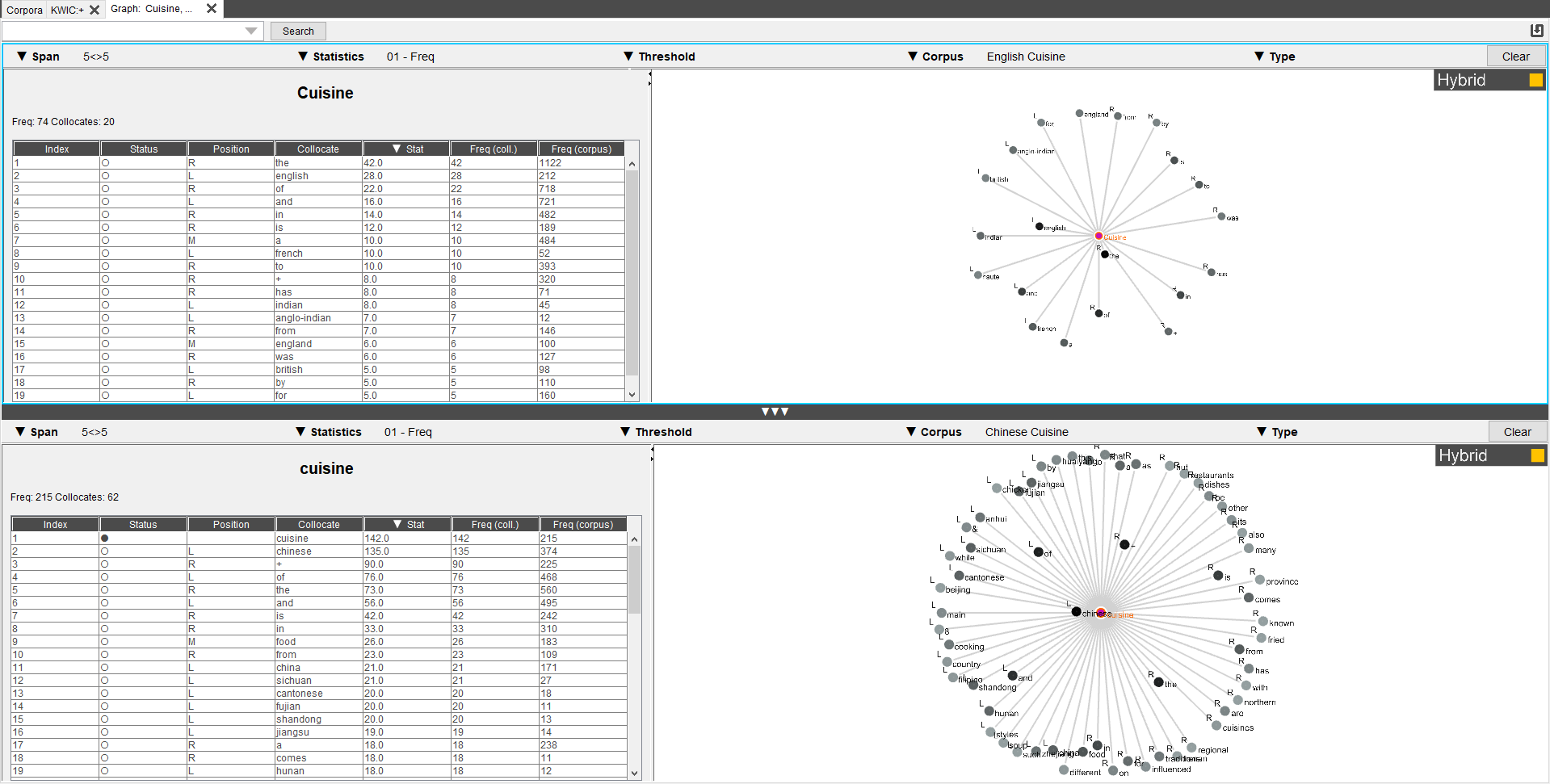
Enfin, cet outil permet également de comparer deux corpus pour une même cible, ici le mot "cuisine"
est attendu pour les deux corpus, une différence de fréquences et du nombre de collocations est alors immédiatement observable.
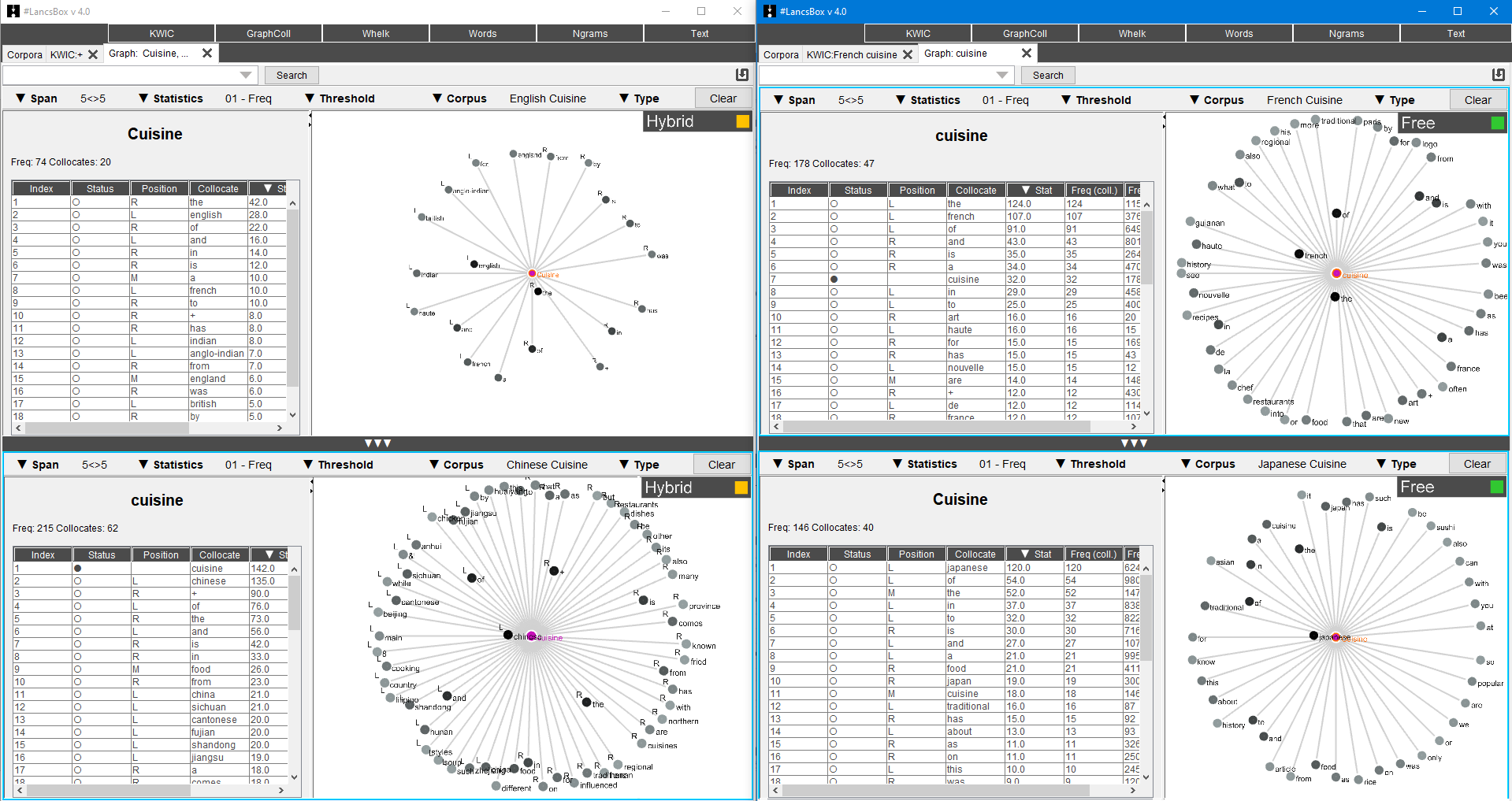
Il est à noter que les corpus ne peuvent s’afficher que deux par deux mais que plusieurs fenêtres peuvent être ouvertes, nous pouvons alors afficher les quatre syntagmes nous intéressant par langue en un seul coup d’oeil :
4. Whelk
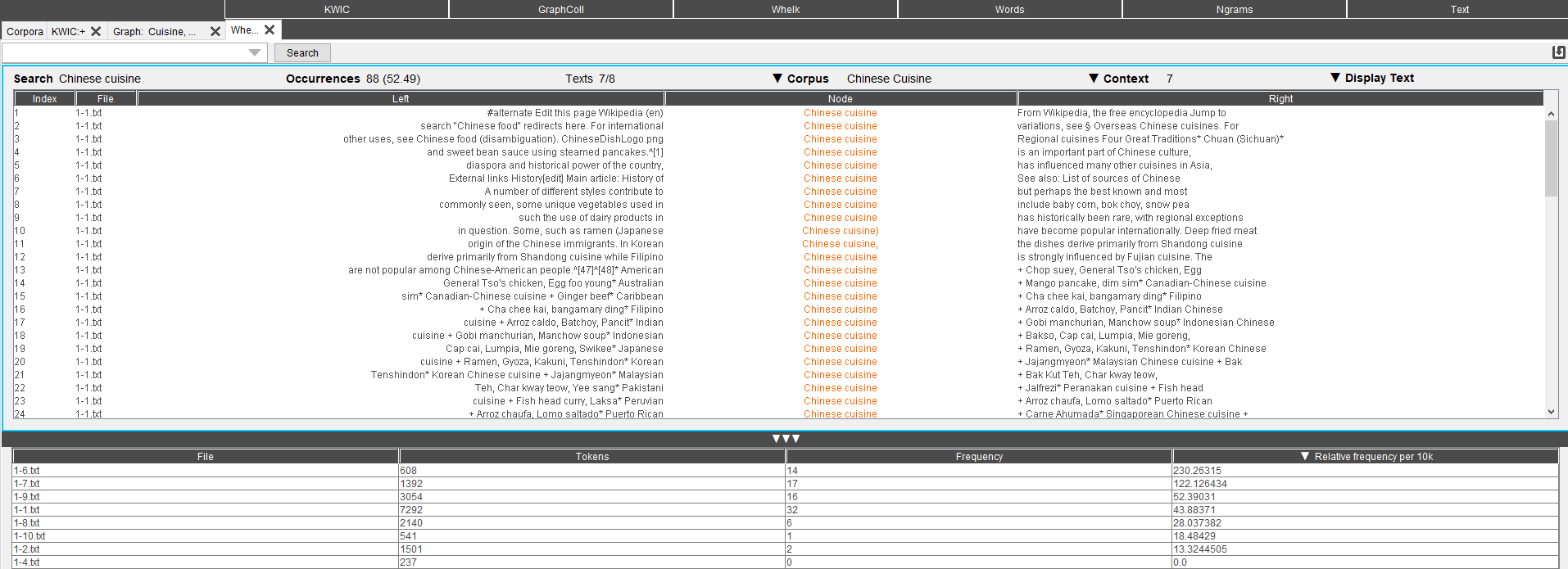
Whelk est un outil mesurant la dispersion de ces valeurs comme suit.
Nous y trouvons également nos concordances mais aussi le nombre de tokens, la fréquence et la fréquence relative de celles-ci.
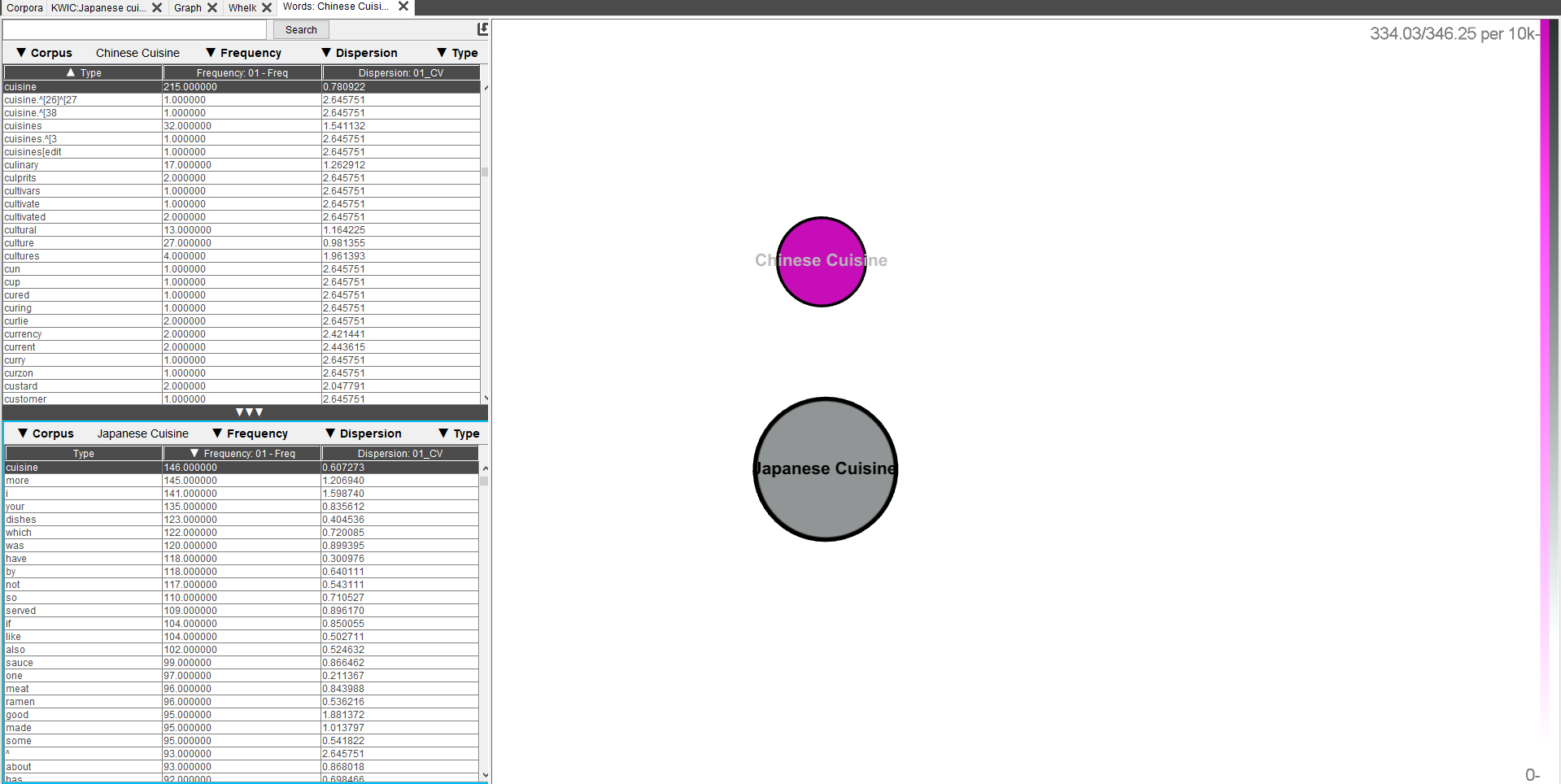
5. Words
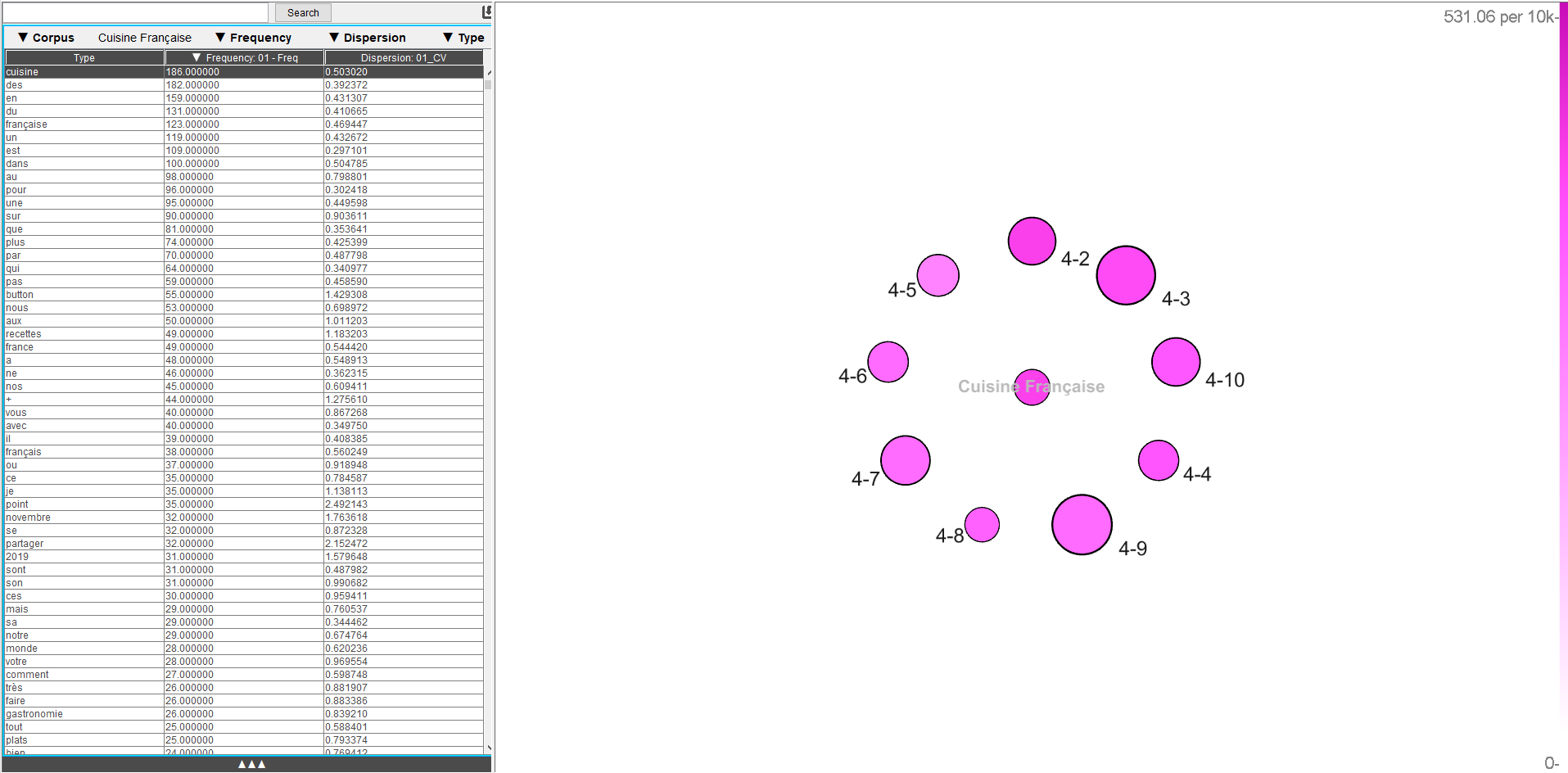
Words est un outil permettant notamment de montrer la taille des corpus mais aussi la taille des différents textes les composant,
ce qui peut permettre de relativiser certaines données. Lors de la recherche de cibles,
la fréquence des occurrences dans les textes est représentée par des nuances de fuchsia ou de gris (dont la différence de nuances est parfois trop subtile pour une claire différenciation).
Il est également possible de comparer deux corpus différents entre eux. La dispersion, en plus des données précédentes, est une valeur mesurée sur cet onglet.
Le type (lemmes, partie du discours ou le tout) est également sélectionnable.
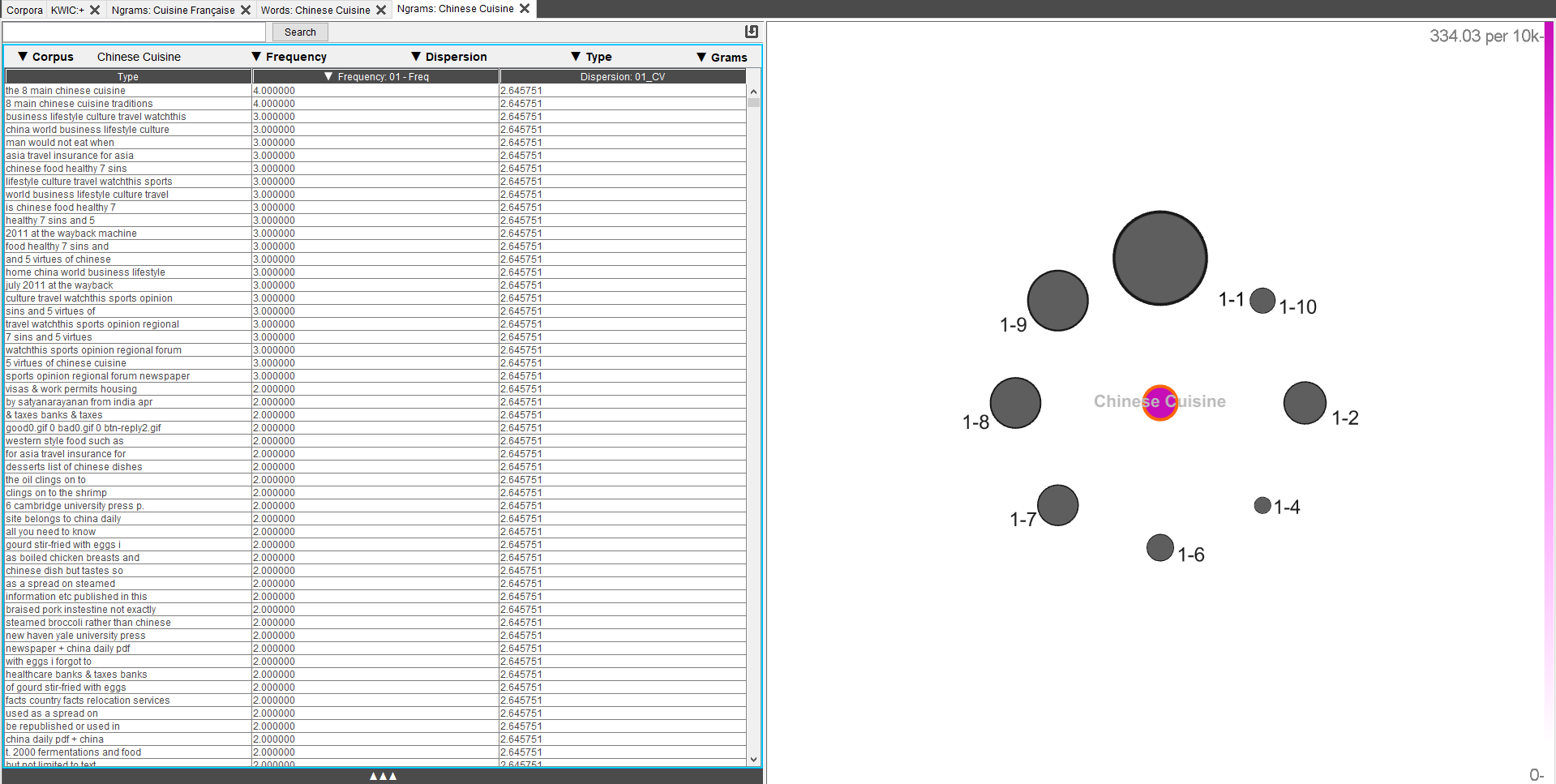
6. Ngrams
L’outil Ngrams est similaire à l’outil word mais ne se concentre pas sur une recherche de mot-clés ou de simple liste de mot, mais sur des séquences de mots.
Il présente les mêmes options et son fonctionnement est sensiblement similaire.
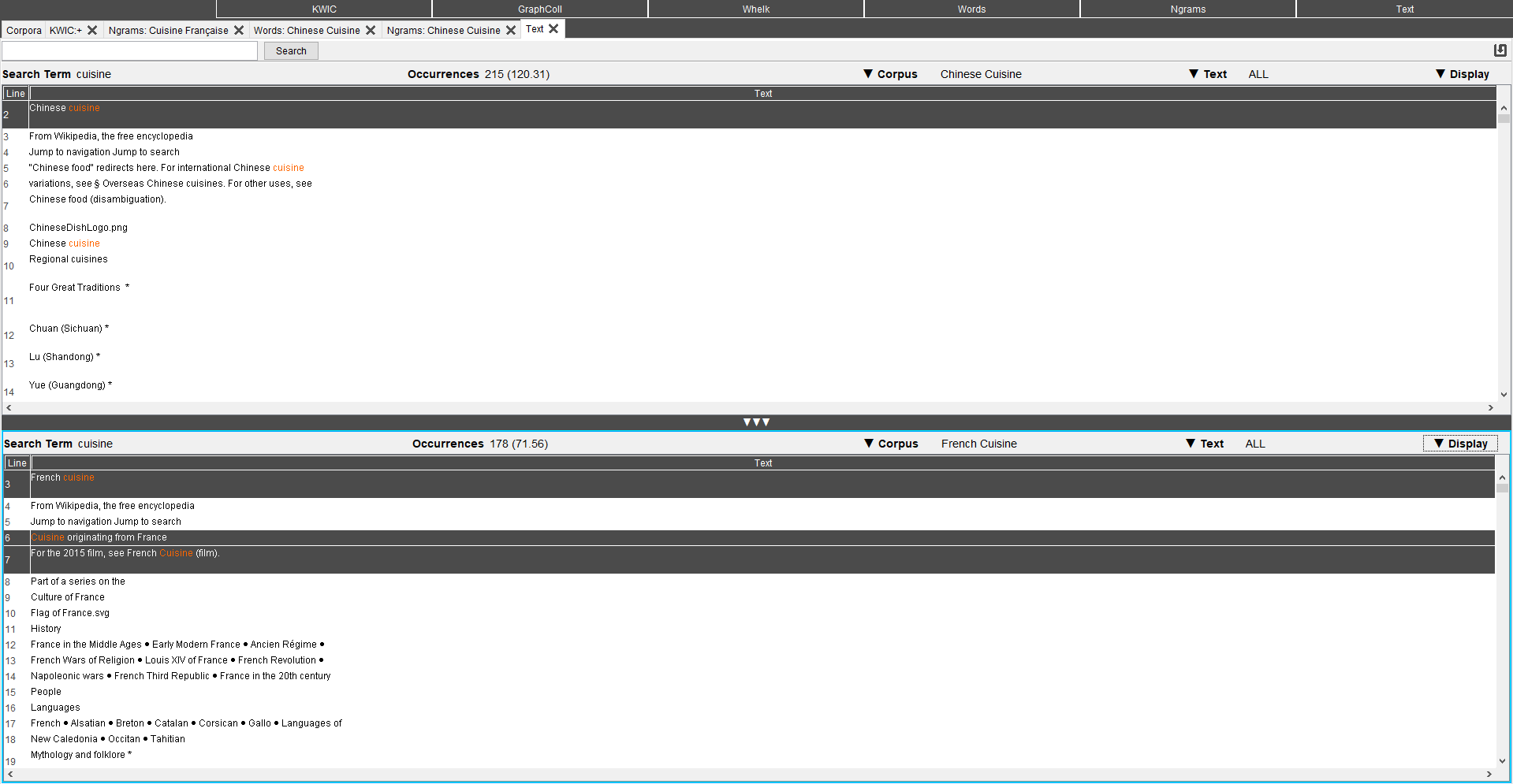
7. Text
Cette partie permet d’accéder aux textes dans leur intégralité, une cible peut y être recherchée, les lignes où elles apparaissent étant alors grisées.
Les textes peuvent être l’intégralité de ceux composant le corpus ou ceux d’un des fichiers textes en particulier.
Il est possible d’afficher uniquement les lemmes, les parties du discours ou l’intégralité des annotations existantes mais aussi de comparer deux corpus différents.
Nous avons, là aussi, accès aux nombres d’occurrences de la valeur cible dans les différents corpus ou fichiers textes.
Ce tutoriel est à présent terminé ! En espérant qu'il puisse être utile.