Bao 1 - Extraction de données textuelles : nettoyage et filtrage
La boîte à outils 1 (BàO 1) nous permet de réaliser une sorte d'extraction d'information concernant les contenus textuels de flux RSS.
On récupere les contenus des fichiers RSS du journal Le Monde. Ensuite, on structure nos données en mettant dans deux fichiers différents : un fichier texte brut et un fichier XML.
Comment faire ...
Pour faire Bao 1, nous avons écrit un programme en langage de programmation Perl. Ce programme entre tout d'abord dans le répertoire de l'année 2019, puis va entrer dans le répertoire de chaque mois, et dans le répertoire de chaque jour, pour finalement entrer dans les fichiers présents dans ces répertoires. Une fois entré dans un fichier, nous allons récupérer seulement les données textuelles, et en même temps, nous allons mettre les titres de ces fils RSS dans une variable nommée $title et faire la même chose pour les descriptions $description (après nous allons retirer les balises). Ensuite, ces variables vont être affichées normalement dans un fichier texte, et encadrées par des balises xml pour le fichier xml.
Méthodes et Résultats
Deux méthodes différentes pour traiter des données textuelles :
Le script Perl+RegExp : Cliquez ici pour télécharger le script
Exécution :
Rubrique à la une : perl bao1_regexp.pl ../2019 3208
Rubrique Culture : perl bao1_regexp.pl ../2019 3246
La partie d'extraction par l'expression régulière

Voici un aperçu des fichiers d'output txt et xml de la rubrique 3208:


Les fichers d'output de Perl+RegExp :
Fichier de sortie rubrique 3208 txt ,
Fichier de sortie rubrique 3208 xml ,
Fichier de sortie rubrique 3246 txt ,
Fichier de sortie rubrique 3246 xml
Le script Perl+XML::RSS : Cliquez ici pour télécharger le script
Exécution :
Rubrique à la une : perl bao1_rss.pl ../2019 3208
Rubrique Culture : perl bao1_rss.pl ../2019 3246
La partie d'extraction par XML::RSS
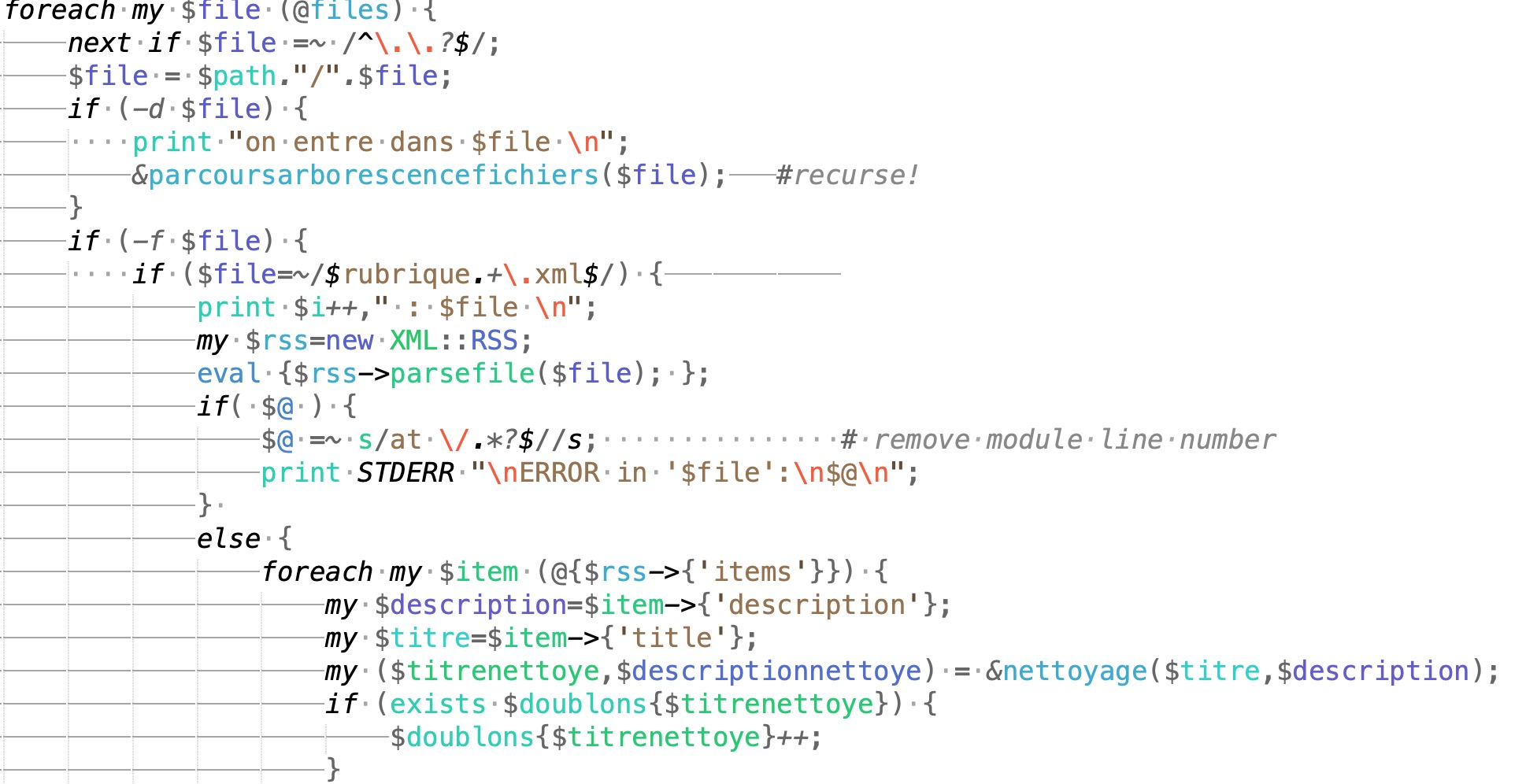
Voici un aperçu des fichiers d'output txt et xml:


Les fichers d'output de Perl+XML::RSS
Fichier de sortie rubrique 3208 txt ,
Fichier de sortie rubrique 3208 xml ,
Fichier de sortie rubrique 3246 txt ,
Fichier de sortie rubrique 3246 xml