BAO1 -- Extraction du texte
La première étape consiste à extraire les informations textuelles comprises dans l´arborescence qui contient les fichiers RSS du journal Le Monde de l´année 2019.
En ce qui concerne la structure des fils RSS, on peut remarquer dans chaque fichier XML les balises « channel » (pour décrire le fil d´information de façon générale), et ensuite les balises « items », qui contient en même temps les balises dont nous nous en servirons : « title » et « description ».
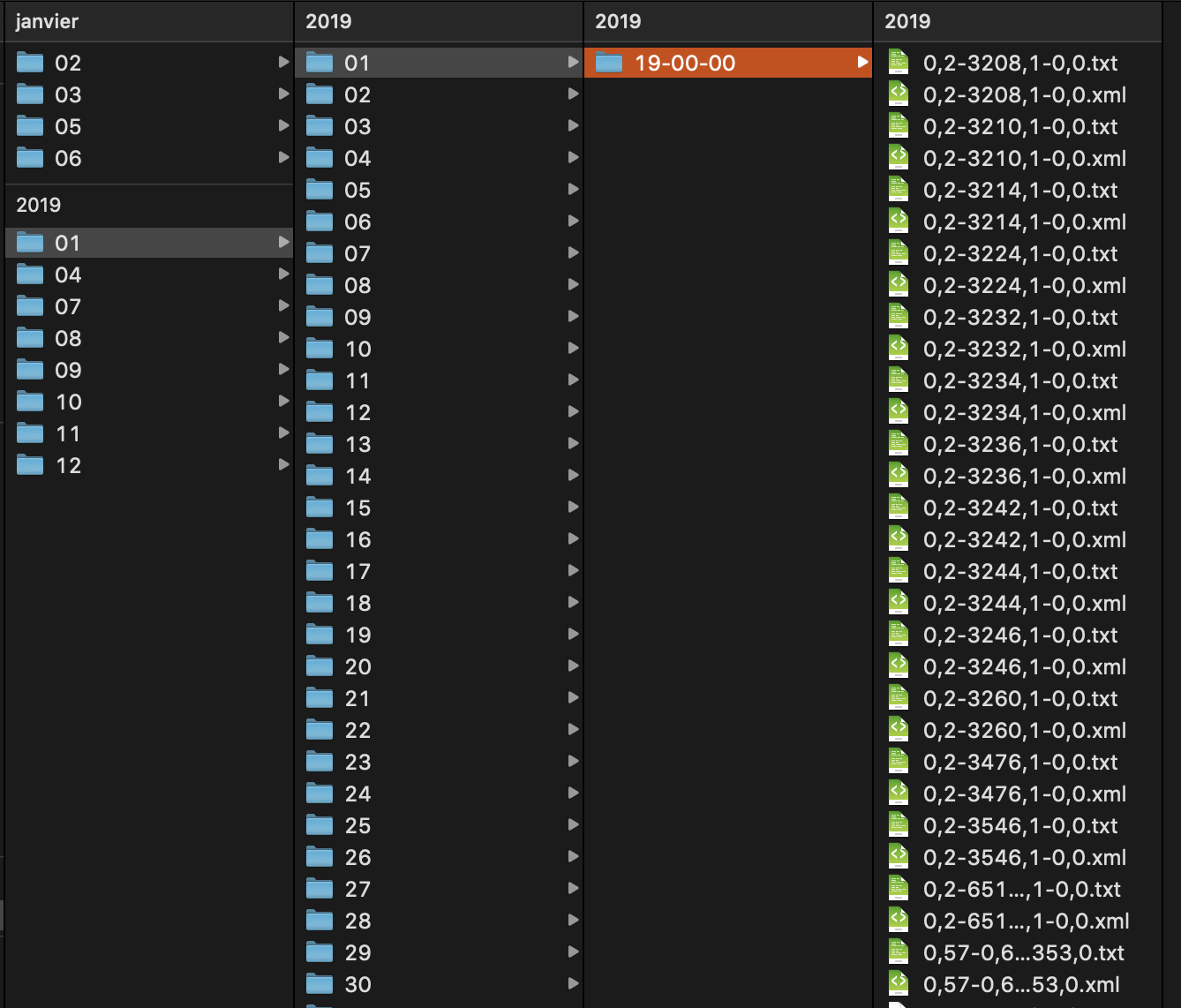
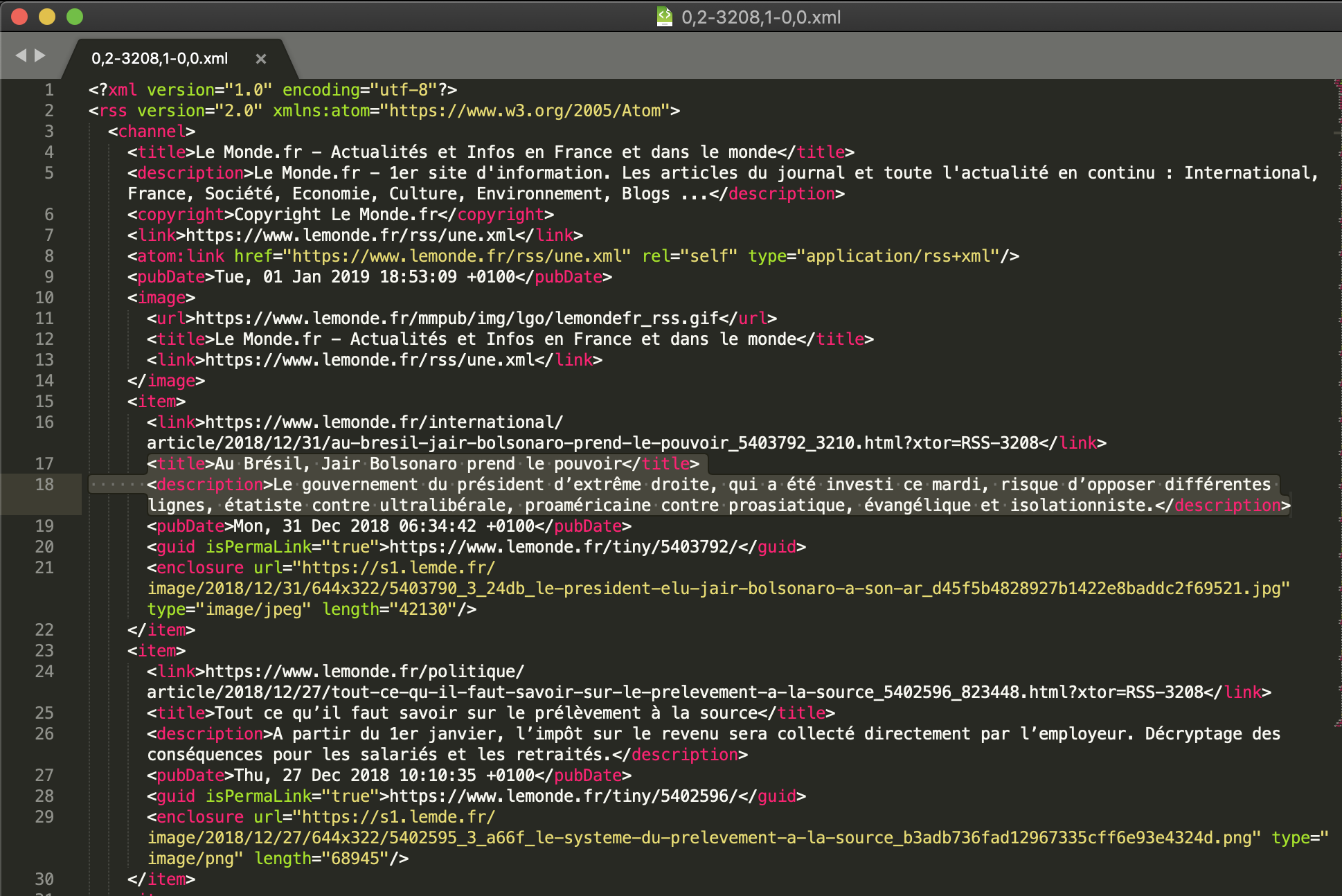
Donc, ce programme écrit en Perl parcourt une arborescence de fichiers XML et applique un traitement sur chacun des fichiers rencontrés au moment du parcours. En sortie, le programme extraira le contenu textuel des fils RSS dans deux fichiers, l´un au format TXT et l´autre au format XML.
En premier lieu, on initialise deux variables qui seront les entrées de notre programme : $rep, le dossier contenant tous les fichiers RSS, en l'occurrence, c'est le rubrique 2019; ensuite, $rubrique, le numéro correspond à la rubrique à traiter, à savoir: 3208, 3476, 3214, 3546.
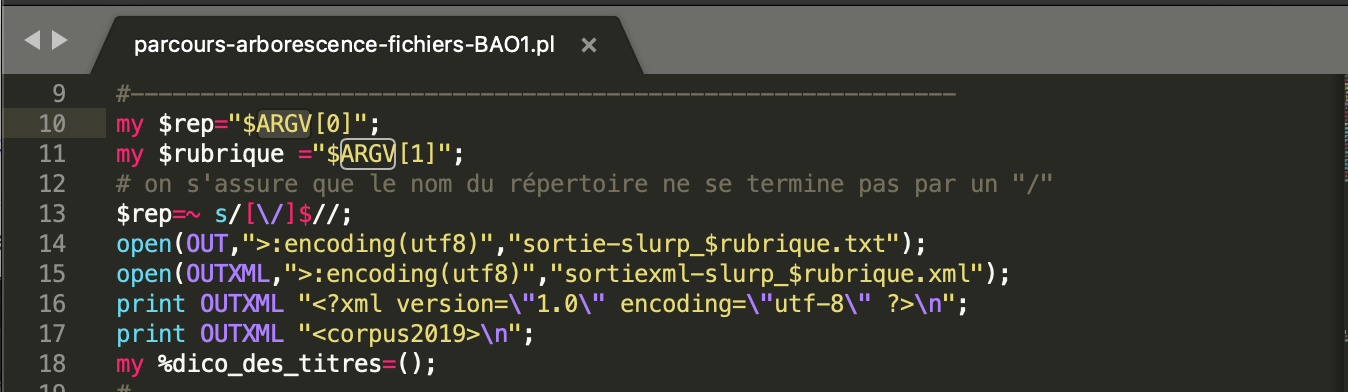
Ensuite, on passe au sous-programme Perl nommé « parcoursarborescencefichiers », qui permet de parcourir tous les fichiers XML de l´arborescence des fils RSS. Ce sous-programme reçoit comme entrée le répertoire où se trouvent tous nos fichiers RSS. À chaque fois qu´il trouve un sous-répertoire, il l´ouvre et vérifie s´il s´agit d´un répertoire ou d´un document XML. Il répète ce procédure jusqu´à ce qu´il a fini toute l´arborescence. C´est à l´intérieur de ce sous-programme où on va ajouter le traitement de chaque fils RSS. Quand il trouve un fichier dont l´extension est « .xml » et le nom corresponde au numéro qu´on a donné en entrée comme rubrique, il passe aux traitements suivants. On concatène toutes les lignes dans une seule ligne; c'est à dire qu'on supprime les retours à ligne et on colle les lignes; En plus, on ajoute des blancs avant coller les textes.
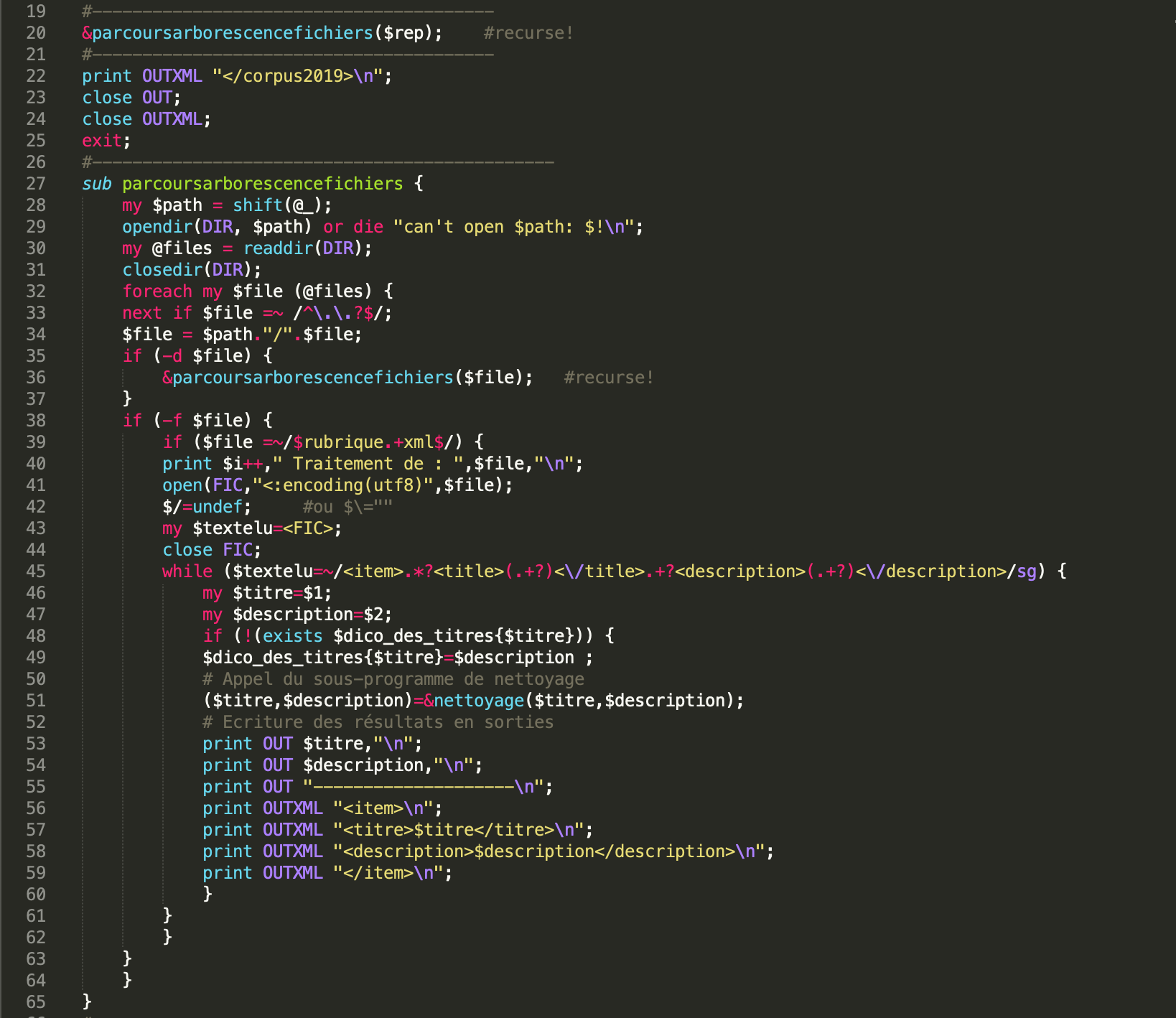
Enfin, une fois qu'on lance le script présenté dessus, nous obtiendrons deux fichiers: l´un en format TXT et l´autre en format XML. Le script est disponible ci-dessous, veuillez cliquez:
Les résultats en format TXT sont disponibles ci-dessous, veuillez cliquez:
Les résultats en format XML sont disponibles ci-dessous, veuillez cliquez: