La classification des rubriques
Ayant vu les contrastes au niveau de mots et de suite de mots dans chaque rubrique, on constate que chaque rubrique a son propre caractéristique. Donc, c'est possible de mettre en oeuvre un processus de classification automatique des fils RSS en basant sur les caractéristiques. En cours "Introduction à la fouille de textes", on a vu les principes d'entraîner des modèles de classification par différents méthodes et des algorithmes implémentés dans le logiciel WEKA.
"Weka est une suite de logiciels d'apprentissage automatique écrite en Java et développée à l'université de Waikato en Nouvelle-Zélande."
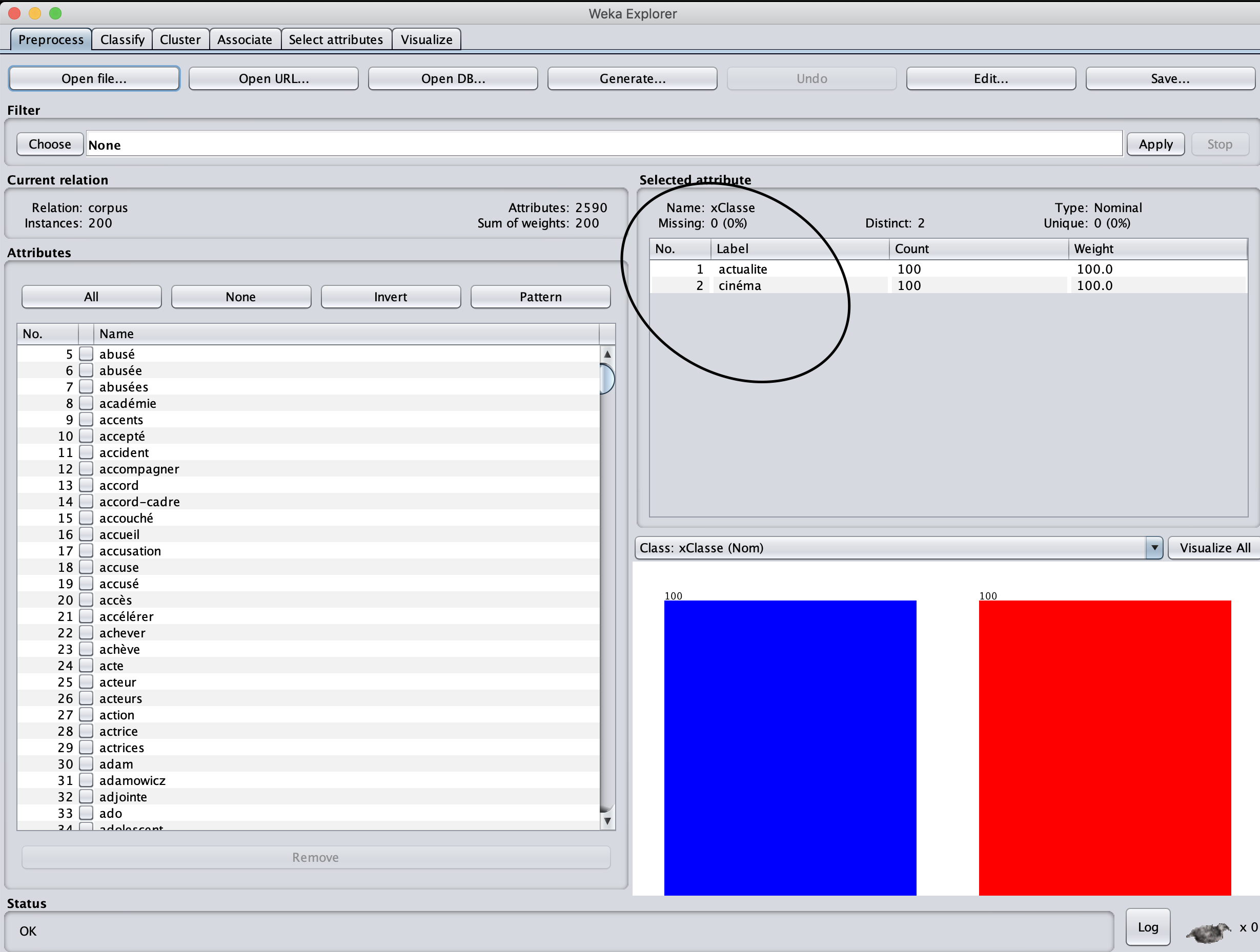
Dans ce site, on va regarder comment l'algorithme qui s'appelle 'arbre de décision' réalise un modèle de classification. Pour le corpus d'entraînement, j'ai extrait 200 paires de titres de descriptions par le résultat de Boîte à outil 2, dont 100 paires sont venus de la rubrique Europe, 100 paires sont venus de la rubrique Cinéma. Donc, on traite juste deux classes ici, soit dans la classification d'actualité, soit dans la classification de cinéma. Le corpus zippé se trouve en bas de cette page.
Vu que le logiciel prend un fichier .arff en entré, j'ai utilisé un script python, fourni en cours de "Introduction à la fouille de textes", en vue de transformer mon corpus en format demandé par le logiciel. Ensuite, je télécharge le fichier .arff dans WEKA comme le corpus d'entraînement. Il s'agit un apprentissage supervisé, car il est fourni d'un corpus dont la classification est déjà bien faite en amont. Donc, on a l'aperçu comme ci-dessous:
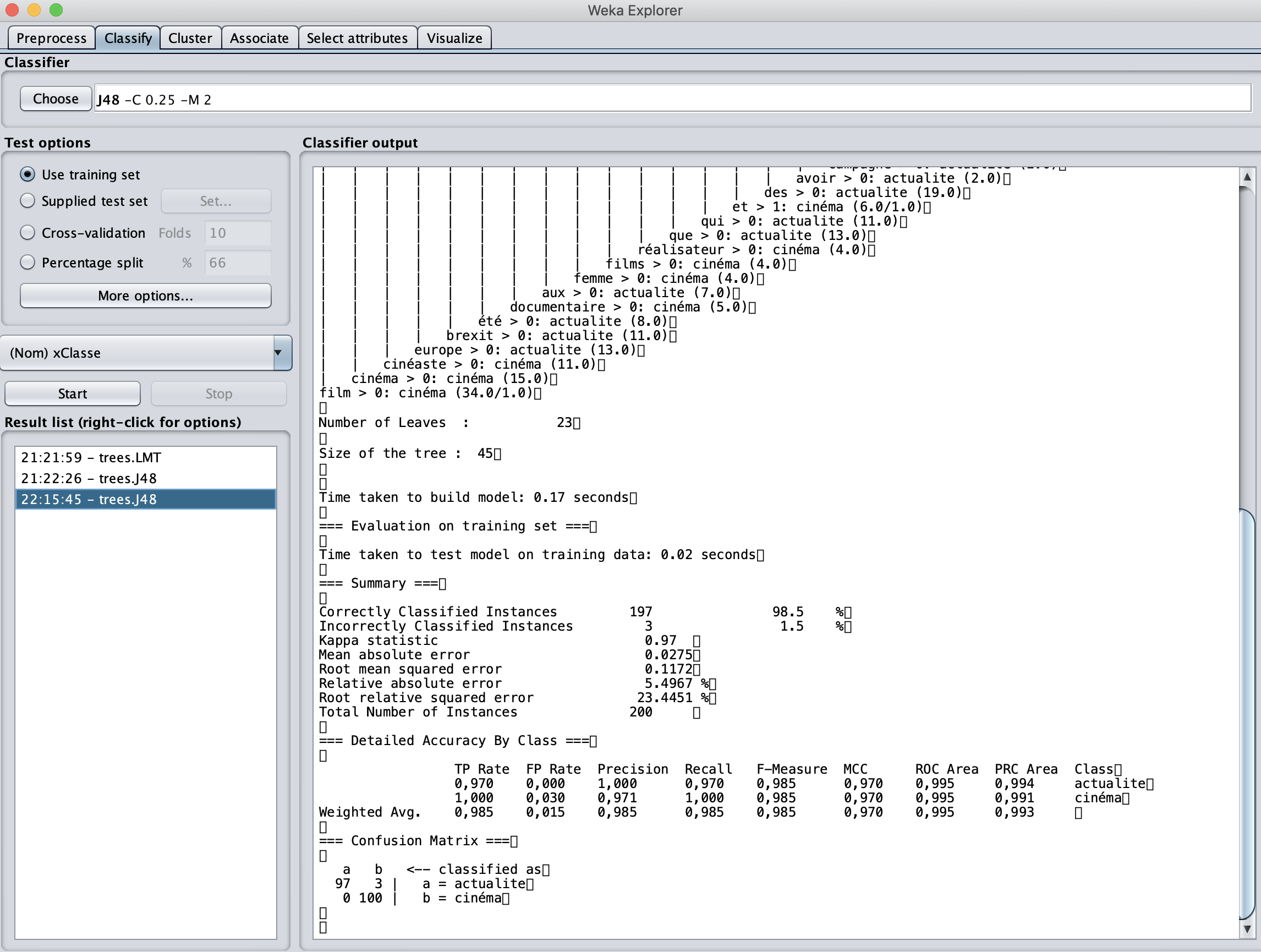
Ayant le but de illustrer un modèle réalisé par un algorithme, j'ai choisi l'algorithme J48 dans le logiciel qui est en fait l'arbre de décision. "L'apprentissage par arbre de décision est une méthode classique en apprentissage automatique. Son but est de créer un modèle qui prédit la valeur d'une variable-cible depuis la valeur de plusieurs variables d'entrée. ", d'après Wikipédia.
Donc, maintenant, on choisit dans l’onglet ‘Classify’ J48.
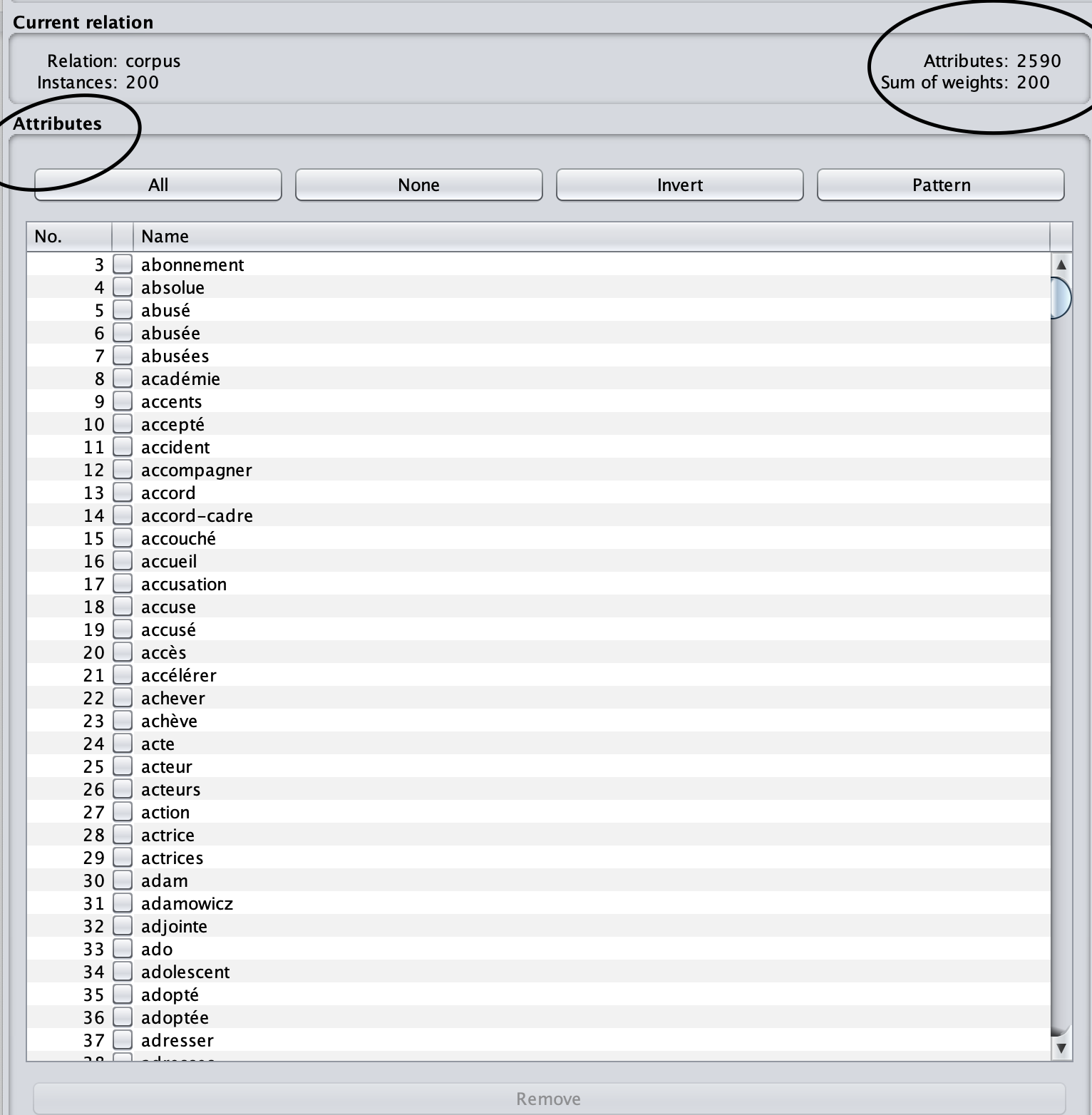
En général, le processus de constitution d'un arbre est une répétition de recherche d'un noeud sur l'arbre où un attribut est capable de classer un couple de titre et description soit dans la rubrique 'A la une', soit dans 'Europe'. Donc, chaque noeud est une décision de choix d'un attribut et cet attribut est capable de faire la segmentation. En l'occurrence, on a 2590 attributs dans le corpus.
Pour visualiser l'arbre généré par le corpus d'entraînement, on clique sur 'Visualize tree', donc on obtient le résultat:

Ayant le modèle généré par l'algorithme de l'arbre de décision, il convient d'évaluer sa performance sur un corpus de test. Donc, j'ai créé un corpus de test ayant juste 100 paires de titres et descriptions. Ensuite, je le télécharge:
Par le résultat de test, on constate que la précision de ce modèle est 0.837 en moyenne. La précision de classer les exemples de test dans la rubrique d'actualité est 0.804, et celle de classer les exemples de test dans la rubrique de cinéma est 0.870. En ce qui concerne la précision, elle mesure les exemples vraiment pertinents parmis ce qui sont classé comme pertinents. Le rappel représente le nombre d'exemples vraiment pertinents qui sont trouvés par le modèle. En l'occurrence, le rappel est 0.835, le f-mesure est 0.835. Donc, la performance du modèle généré par l'algorithme J48 est plustôt favorable.

Vu qu'il existe beaucoup d'algorithmes dans le logiciel, on peut en tester et explorer plusieurs dans le future afin de trouver un meilleur modèle pour faire la classification automatique des fils RSS.
Voici le corpus d'entraînement et le corpus de test: