Objectif : extraire les contenus textuels des fils RSS de l'arborescence (les contenus des balises title et description)
Moyens :
- Expressions régulières : considérer le texte comme un « sacs de caractères » dans lequel on va essayer de repérer certaines régularités
- XML::RSS : considérer que la structuration du texte est logique (sous la forme d'un arbre de « la famille RSS » ) et sa modélisation dans un programme pour au final n'avoir qu'à « cueillir » les feuilles textuelles visées
Pour utiliser ce moyen, le plus important est de trouver la régularité des articles. Enfin, la règle a été trouvée. Voici notre script et les résultats. Pour le fonctionner, il nous faut le mettre dans le même répertoire du dossier cible (ici c'est 2019).
Remarques :
- Commande : perl BaO1-extraction-regex.pl repertoire-a-parcourir code-rubrique
- Moyen : On extrait des titres et des descriptions à l'aide des expressions régulières.
- Entrée : Le programme prend en entrée le nom du répertoire contenant les fichiers à traiter.
- Sortie : Le programme construit en sortie deux fichiers :
- BaO1-extraction-regex-sortie-slurp_$rubrique.txt : un texte brut séparé par « ------ » tous les articles
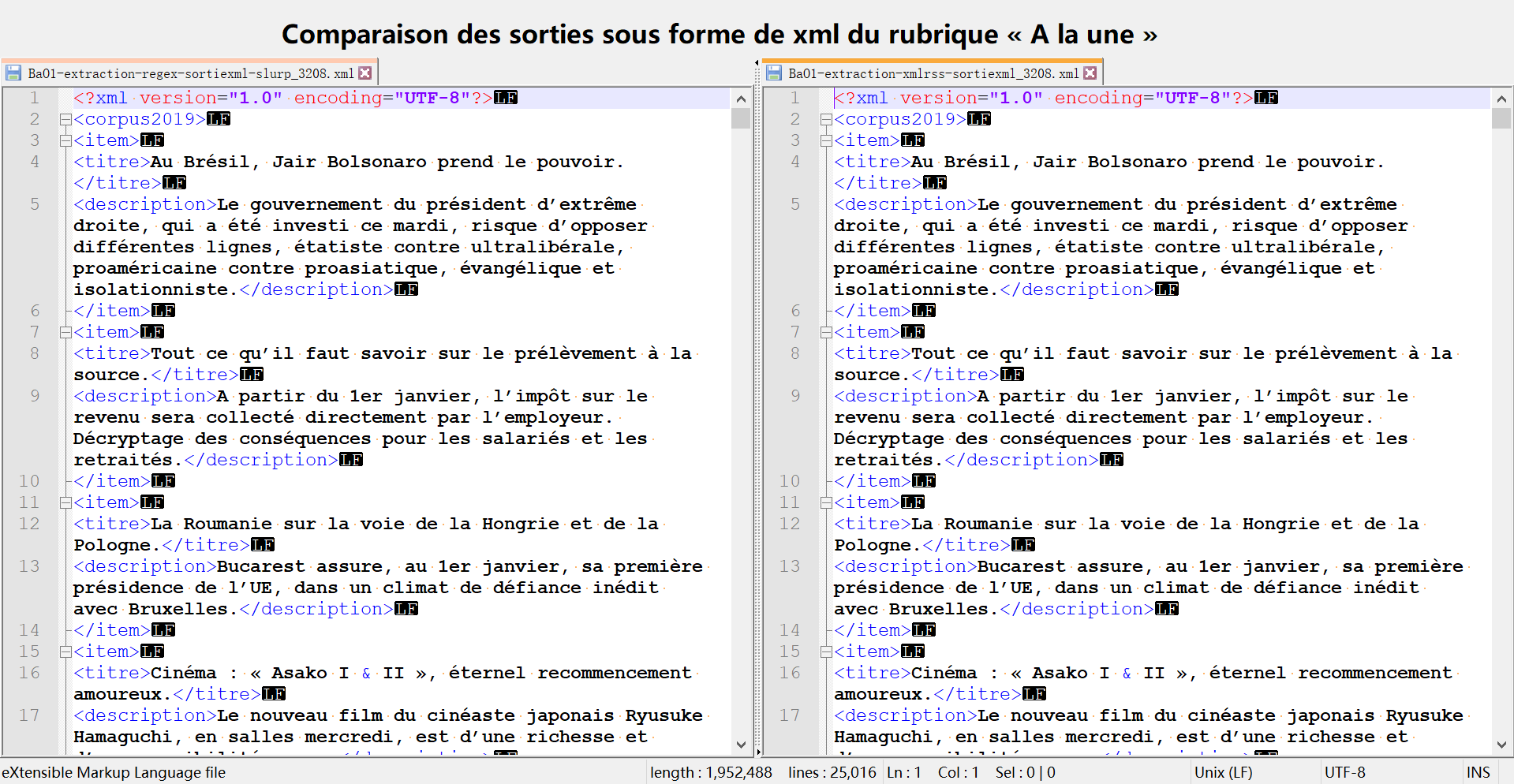
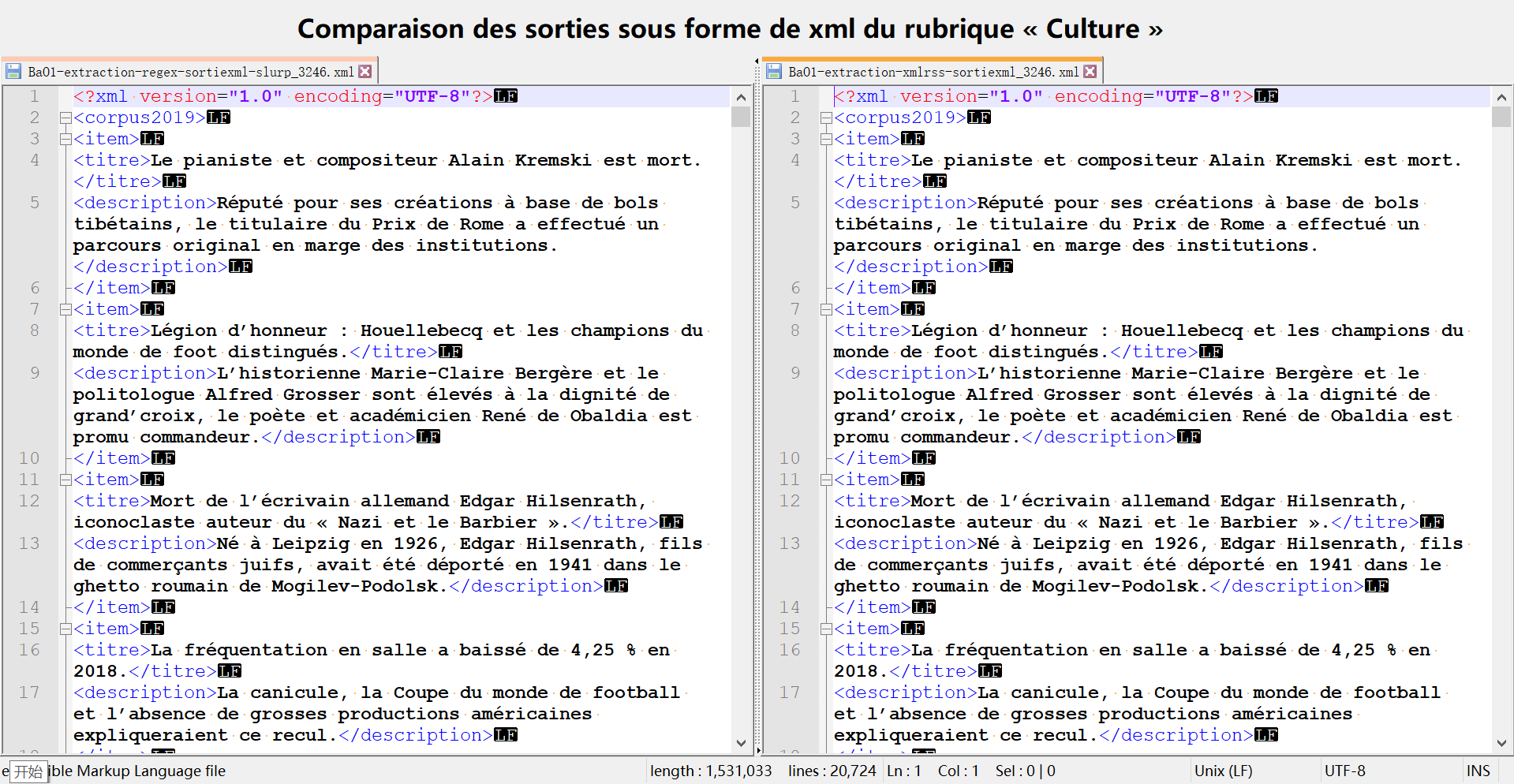
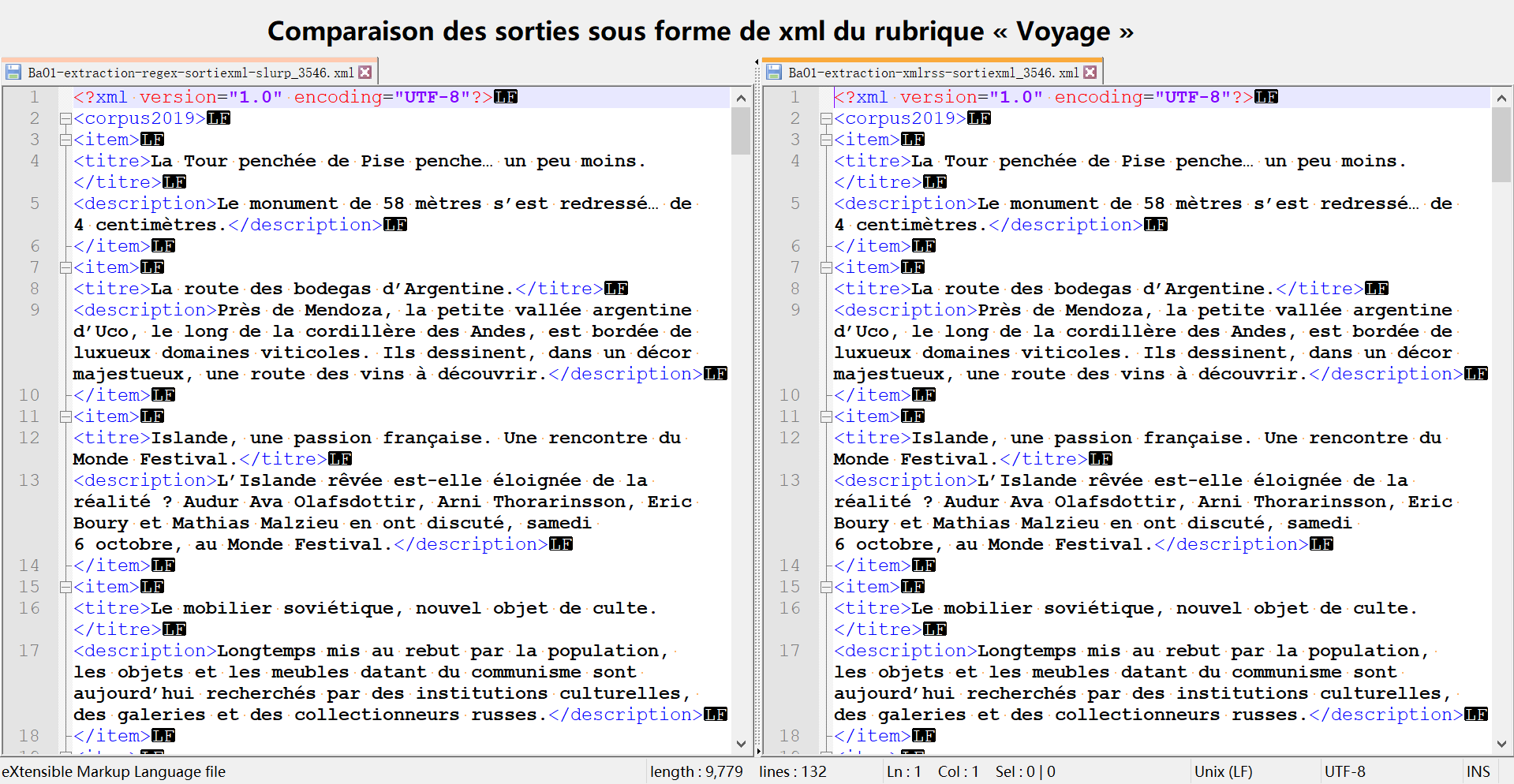
- BaO1-extraction-regex-sortiexml-slurp_$rubrique.xml : un fichier structuré contenant les noms des articles et leur description sous la structure arborescente ci-dessous :

- Fonction supplémentaire : À la fin de la programme, il nous affiche le temps de calcul.



Remarques :
- Commande : perl BaO1-extration-regex.pl repertoire-a-parcourir code-rubrique
- Moyen : On extrait des titres et des descriptions à l'aide du module XML::RSS.
- Entrée : Le programme prend en entrée le nom du répertoire contenant les fichiers à traiter.
- Sortie : Le programme construit en sortie deux fichiers :
- BaO1-extraction-xmlrss-sortie_$rubrique.txt : un texte brut séparé par "------" tous les articles
- BaO1-extraction-xmlrss-sortiexml_$rubrique.xml : un fichier structuré contenant les noms des articles et leur description sous la structure arborescente ci-dessous :
- Fonction supplémentaire : À la fin de la programme, il nous affiche le temps de calcul.
Pour utiliser ce moyen, le plus important est de comprendre le fonctionnement du module. Vous pouvez trouver ci-join notre script et les résultats. Le script se trouve à côté du dossier cible.